
DeepSeek-R1: Charting New Frontiers in Pure RL-Driven Language Models
Hey AI enthusiasts! Today, we’re diving into DeepSeek-R1, a powerful new language model that’s shaping the future of conversational AI. We’ll break down how it works, explore its unique RL+SFT training process, and even walk through a hands-on project where you can build your own chatbot.
Introduction
In the rapidly evolving landscape of artificial intelligence, DeepSeek-R1 stands out as a groundbreaking advancement in the realm of large language models (LLMs). By challenging conventional approaches that rely heavily on supervised fine-tuning (SFT), DeepSeek-R1 pioneers a novel methodology driven primarily by Reinforcement Learning (RL). This blog delves into the intricacies of DeepSeek-R1, exploring how it achieves advanced reasoning capabilities without the need for extensive human-annotated data.
The RL-Driven Reasoning Workflow
DeepSeek-R1’s unique thinking process can be visualized as an iterative self-correcting loop:
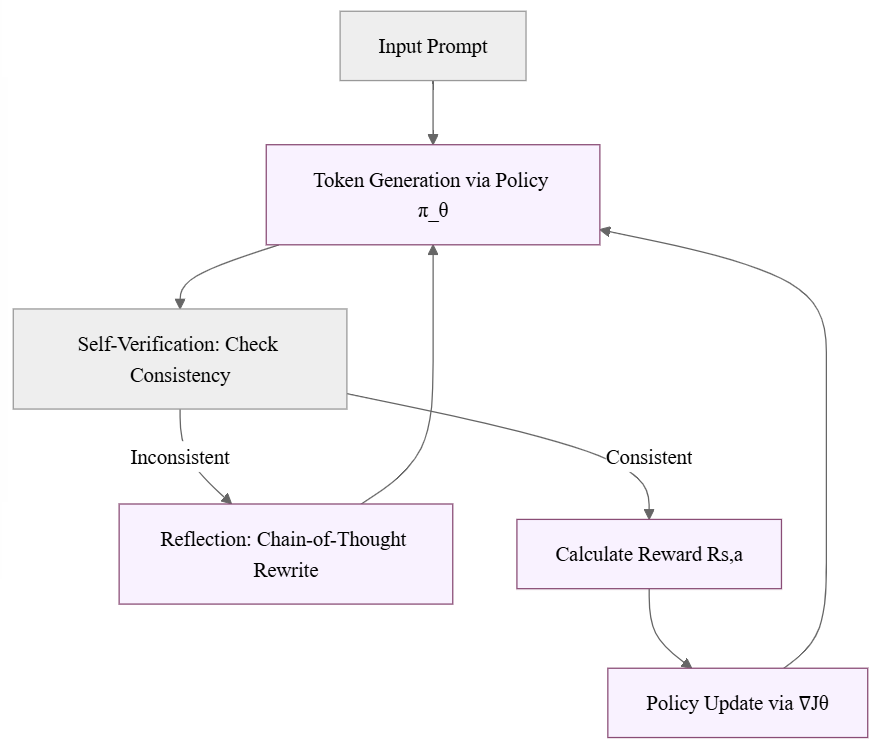
Key Components:
- Policy Network (π_θ): Generates token-by-token decisions
- Self-Verification: Internal consistency checking
- Reflection Loop: Chain-of-Thought rewriting for error correction
- Reward-Driven Updates: Policy gradients (∇J(θ)) optimizing future decisions
Why This Matters
From its innovative training pipeline to its open-source commitment and record-setting benchmarks, DeepSeek-R1 represents a significant leap forward in AI research. The model’s ability to autonomously develop reasoning patterns through RL—mirroring human problem-solving strategies like trial-and-error and self-correction—challenges traditional paradigms of AI development.
1. A Leap in Reasoning via Pure Reinforcement Learning (RL)
No Supervised Fine-Tuning (SFT) Required
Conventional large language models (LLMs) often begin with a supervised fine-tuning (SFT) phase where they learn from human-annotated text before continuing to more specialized training. However, DeepSeek-R1-Zero challenges this approach by demonstrating robust reasoning purely via Reinforcement Learning (RL).
RL as the Sole Driver of Knowledge
In the RL setup, each generated token can be thought of as an action \(a_t\) taken in a state \(s_t\) (where \(s_t\) represents the current partial sequence or context). The policy \(\pi_\theta(a_t \mid s_t)\) is parameterized by \(\theta\)—in this case, the weights of the language model.
Under this formulation, the expected return \(J(\theta)\) in an RL framework is:
\[J(\theta) \;=\; \mathbb{E}_{\tau \sim \pi_\theta}\!\Big[\sum_{t=1}^{T} \gamma^t \, R(s_t, a_t)\Big].\]Where:
- \(\tau\) is a trajectory (sequence of tokens) generated by the policy \(\pi_\theta\).
- \(R(s_t, a_t)\) is the reward for taking action \(a_t\) in state \(s_t\).
- \(\gamma\) is a discount factor (often set to 1 for episodic tasks in language generation).
To update parameters \(\theta\), one could use Policy Gradient methods, such as REINFORCE or PPO (Proximal Policy Optimization). In a simplified policy gradient form:
\[\nabla_\theta J(\theta) \;=\; \mathbb{E}_{(s,a)\sim \pi_\theta} \Big[ \nabla_\theta \log \pi_\theta(a \mid s)\; A^\pi_\theta (s,a) \Big],\]where \(A^\pi_\theta(s,a)\) is an advantage function (e.g., how much better an action is compared to an average policy).
By relying solely on this RL scheme, DeepSeek-R1-Zero managed to develop advanced reasoning without ever seeing supervised examples.
Natural Emergence of Reflection & Self-Verification
An astounding outcome of training purely via RL was the spontaneous appearance of “thinking” behaviors in DeepSeek-R1-Zero:
- Self-Verification: The model would revisit previously generated tokens to verify or correct them.
- Reflection: It would generate chain-of-thought (CoT) style explanations internally, refining its own logic step by step.
It’s the first open research confirming that large-scale RL alone can foster deep reasoning. This reduces the need for expensive supervised data collection and highlights new ways to train LLMs with minimal human intervention.
2. Overcoming Challenges: The Evolution from DeepSeek-R1-Zero to DeepSeek-R1
Learning from Early Limitations
The journey began with DeepSeek-R1-Zero, a model that demonstrated the power of pure reinforcement learning (RL) in discovering novel reasoning pathways. However, early experiments uncovered some notable challenges:
- Endless Repetition: The model sometimes generated phrases repetitively.
- Mixed-Language Outputs: Responses occasionally included multiple languages in a single output.
- Poor Readability: Unstructured text occasionally led to outputs that were hard to follow.
These quirks indicated that while RL is excellent at exploration and discovering new reasoning strategies, it sometimes struggles with maintaining the structural stability and clarity that even a modest amount of supervised training can provide.
The Power of a Supervised Kickstart
To address these challenges, we introduced a small but impactful supervised learning phase—a “cold-start” that primes the model for coherent text generation before applying RL fine-tuning. This hybrid training approach leverages the strengths of both supervised learning and RL.
Mathematically, the initial supervised phase can be framed as minimizing the cross-entropy loss, denoted by:
\[L_{\text{SFT}}(\theta) = - \sum_{(x,y)\in D_\text{kickstart}} \log \pi_\theta(y \mid x),\]where:
- \(D_\text{kickstart}\) is our carefully curated supervised dataset.
- \((x, y)\) represents input-target pairs (for example, a question and its corresponding answer).
- \(\pi_\theta(y \mid x)\) is the probability assigned by the model (parameterized by \(\theta\)) to the target \(y\) given the input \(x\).
By employing standard teacher forcing during this phase, we effectively “teach” the model to produce structured and coherent text. This supervised kickstart dramatically reduces issues like repetition and improves overall readability.
Achieving Top-Tier Performance
Following the kickstart, the model undergoes further RL fine-tuning with an updated reward scheme designed to reinforce high-quality completions. This two-stage training regimen has resulted in DeepSeek-R1 matching—and in some cases exceeding—the performance of elite models like OpenAI-o1 across a range of demanding tasks:
- Mathematics: Capable of handling complex proofs, performing arithmetic with precision, and engaging in advanced reasoning.
- Coding: Excels in generating code snippets and providing debugging assistance.
- Multistep Reasoning: Supports long chain-of-thought dialogues that involve multiple reasoning steps.
A small injection of supervised data can yield a big leap in model stability—an insight that is poised to influence future hybrid training pipelines across the field.
3. Scaling New Heights: Massive Scale and Open-Source Commitment
Unprecedented Scale and Context Length
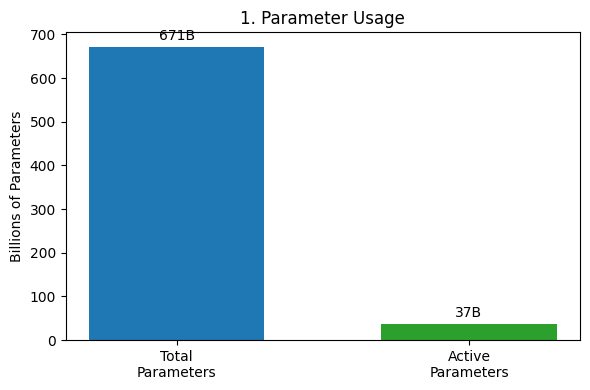
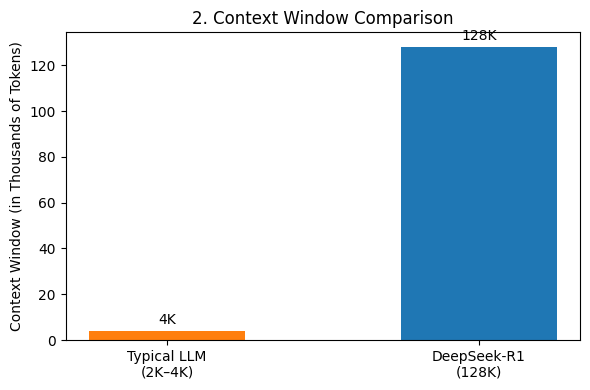
At its core, DeepSeek-R1 builds upon the robust architecture of DeepSeek-V3-Base, boasting an impressive \(671\text{B parameters}\). However, in practice, only about \(37\text{B parameters}\) are active during any given forward pass. This efficient utilization is paired with a groundbreaking \(128\text{K token context window}\), a stark contrast to the typical \(2\text{K}\)–\(4\text{K token}\) windows seen in many other large language models (LLMs).
Commitment to Openness
In a significant departure from proprietary ecosystems, the entire DeepSeek-R1 family—including DeepSeek-R1-Zero, DeepSeek-R1, and several distilled versions—is fully open-sourced. Our commitment to transparency is evident through the public release of:
- Model Weights: Enabling researchers to experiment and fine-tune models.
- Training Scripts: Providing insights into our training methodologies.
- Detailed Documentation: Facilitating a deeper understanding of the model’s architecture and capabilities.
Full openness empowers developers and researchers with the freedom to innovate—experimenting, fine-tuning, or even forking the project as they see fit. This philosophy underscores our commitment to fostering an ecosystem of collaboration and transparency.
DeepSeek-R1: A Leap Towards Efficient, Scalable, and Open-Source AI
DeepSeek-R1 represents a major advancement in AI, balancing efficiency, scalability, and open-source accessibility. It’s designed to handle complex tasks with optimized resource usage and a commitment to transparency. This analysis explores its architecture, training, and performance, using figures to highlight key insights.
Architecture and Foundations
|  |
|  |
|  |
|—|—|—|
|
|—|—|—|
DeepSeek-R1 prioritizes efficiency. Fig. 1 illustrates its parameter usage, showing that out of 671 billion total parameters, only 37 billion are active. This selective activation, likely achieved through Mixture-of-Experts (MoE), enhances computational efficiency.
Its context window is a game-changer, handling 128,000 tokens, compared to typical LLMs at 4,000 tokens (Fig. 2). This expanded capacity enables better processing of long documents and complex queries.
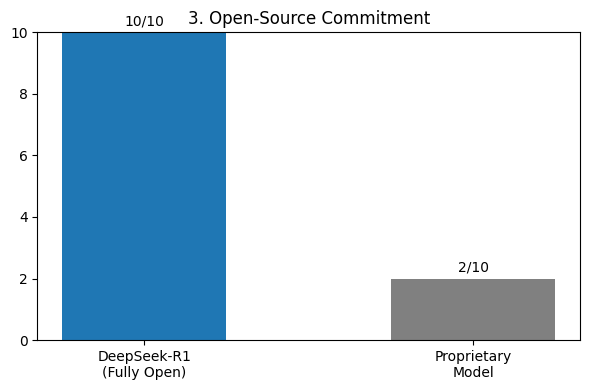
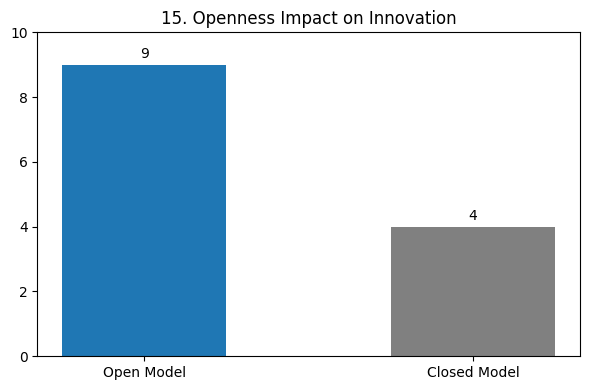
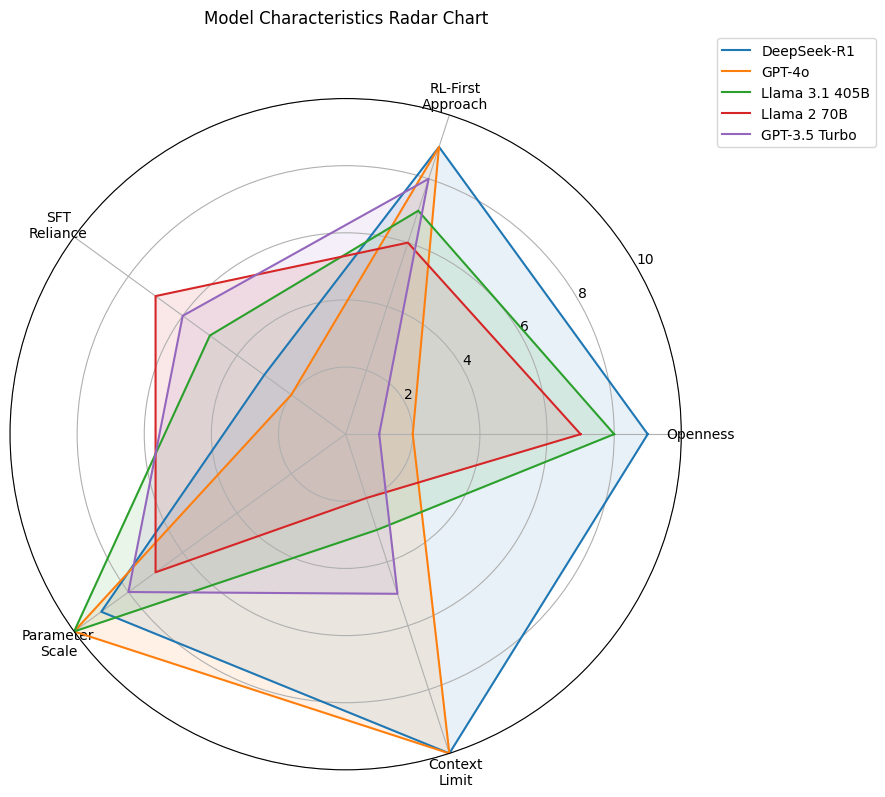
A commitment to open-source principles is another defining feature (Fig. 3), with DeepSeek-R1 scoring 10/10 in openness, fostering collaboration and innovation.
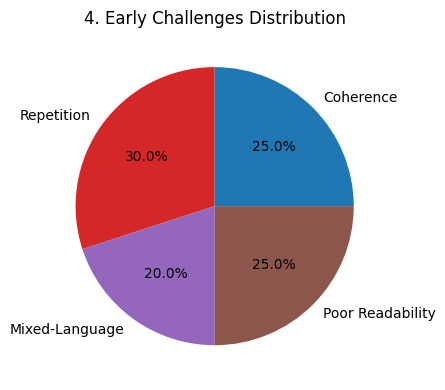
Early challenges included repetition, readability, coherence, and multilingual handling (Fig. 4). Addressing these issues was crucial to refining the model’s quality.
Training Process: How DeepSeek-R1 Learns
|  |
|  |
|—|—|
|
|—|—|
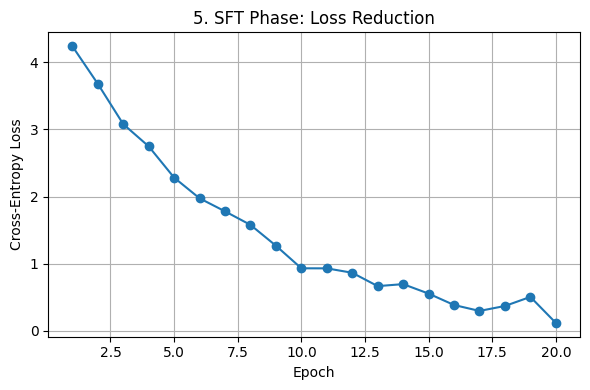
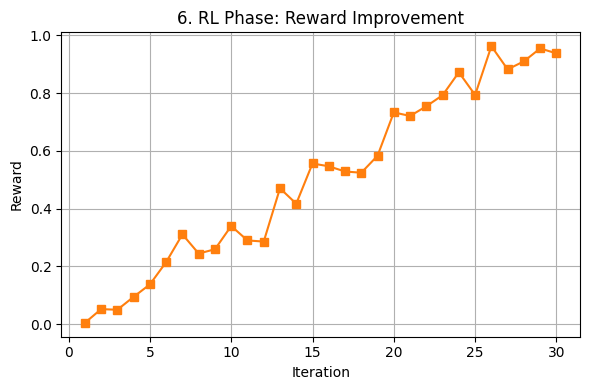
The Supervised Fine-Tuning (SFT) phase reduced cross-entropy loss over time (Fig. 5), confirming its learning progress. In the Reinforcement Learning (RL) phase, reward scores steadily increased (Fig. 6), showing optimization based on feedback.
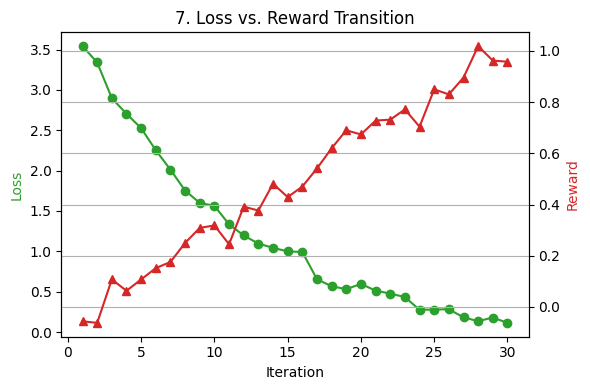
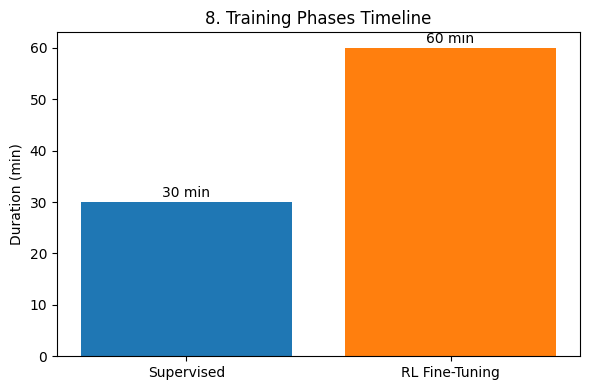
Fig. 7 provides a dual-axis view of loss vs. reward, demonstrating how decreasing loss correlates with increasing reward. The training timeline (Fig. 8) highlights the proportion of time dedicated to each phase, emphasizing the role of both supervised learning and reinforcement learning.
Benchmarking Performance: DeepSeek-R1 vs. the Competition
 |
 |
|---|---|
 |
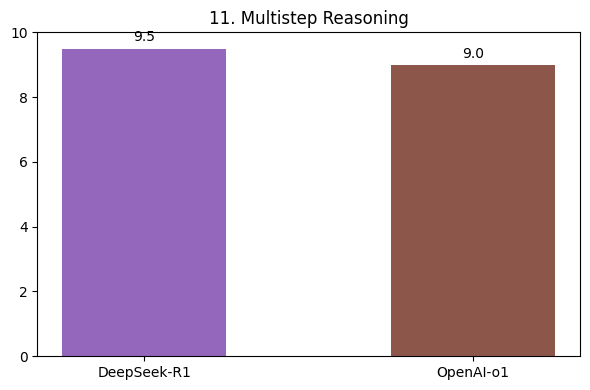 |
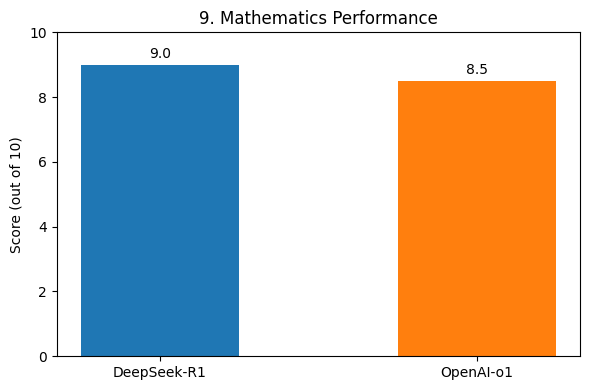
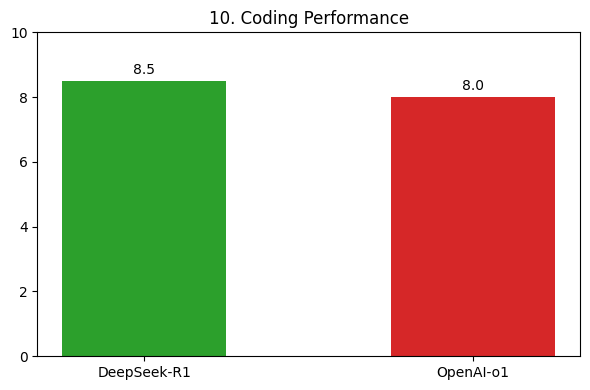
DeepSeek-R1 excels in mathematics (Fig. 9), outperforming the hypothetical “OpenAI-o1” model. Similarly, in coding (Fig. 10) and multi-step reasoning (Fig. 11), it demonstrates superior accuracy and problem-solving skills.
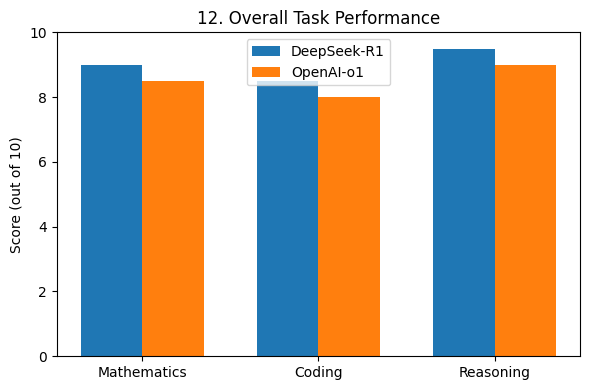
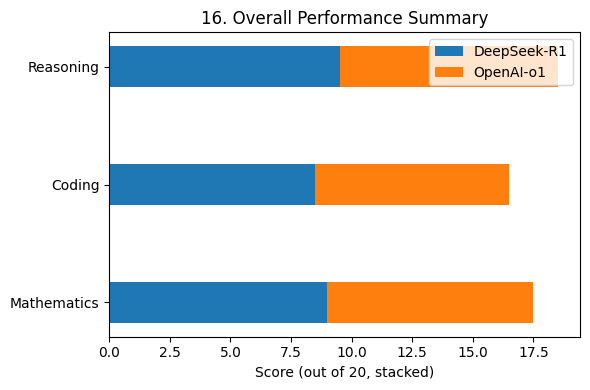
A consolidated performance overview across tasks (Fig. 12) further highlights its strengths, positioning DeepSeek-R1 as a top-tier AI model.
Efficiency and Open-Source Impact
|  |
|  |
|—|—|
|
|—|—|
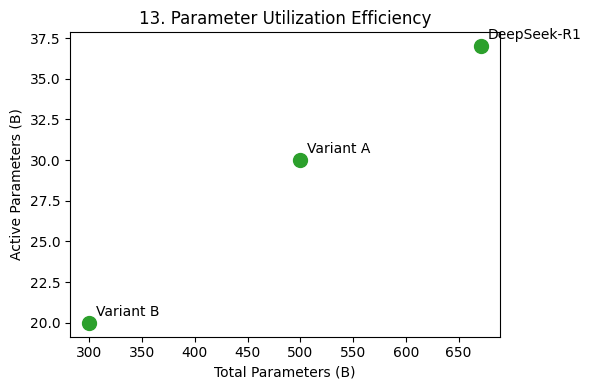
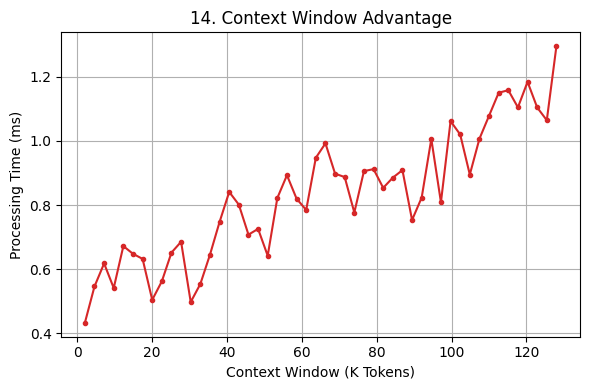
DeepSeek-R1 optimizes parameter utilization (Fig. 13) to balance total vs. active parameters, reducing computational overhead. Fig. 14 shows its context window efficiency, maintaining stable processing time despite handling large token sequences.
|  |
|  |
|—|—|
|
|—|—|
The impact of open-source AI is evident in Fig. 15, which shows how openness fosters innovation compared to proprietary models. The final performance summary (Fig. 16) consolidates its strengths across various domains
4. A Novel Pipeline with Multiple RL and SFT Stages
How Reinforcement Learning Shapes LLM Behavior
Reinforcement learning (RL) is not part of the transformer’s core architecture (e.g., self-attention layers), but rather a training strategy applied after initial pre-training. In DeepSeek-R1, RL refines the model’s outputs by rewarding desirable behaviors like helpfulness, correctness, and alignment with human preferences.
Two RL Stages + Two SFT Stages: A Symphony of Training Techniques
DeepSeek-R1’s pipeline is layered into four main stages:
1. RL Stage 1 (DeepSeek-R1-Zero style)
\(\text{Optimize } J(\theta) \;=\; \mathbb{E}_{\tau \sim \pi_\theta}\!\Big[\sum_{t=1}^{T} R(s_t, a_t)\Big],\)
- A reward model (trained on human feedback) scores candidate responses.
- The LLM acts as a policy network generating text actions \(a_t\).
- PPO (Proximal Policy Optimization) updates model weights to maximize rewards.
Purpose: Discover high-reward reasoning paths through trial and error.
2. SFT Stage 1 (Kickstart Phase)
\(\min_{\theta}\; L_{\text{SFT}}(\theta),\)
- Supervised fine-tuning on high-quality demonstration data.
- Anchors the model to retain baseline capabilities after RL’s exploratory phase.
3. RL Stage 2 (Post-Kickstart RL)
\(\min_{\theta}\; \Big( -\mathbb{E}_{\tau \sim \pi_\theta}[\text{Reward}] \Big),\)
- Reuses the reward model but focuses on narrower exploration around high-quality regions identified in Stage 1.
- Often employs KL divergence constraints to prevent over-optimization.
4. SFT Stage 2 (Human Preference Alignment)
\(\min_{\theta}\; \Big(\alpha \, L_{\text{RL}}(\theta) \;+\; (1-\alpha) \, L_{\text{SFT}}(\theta)\Big),\)
- Hybrid loss balancing RL rewards with supervised alignment.
- Typically uses human-curated preference datasets (e.g., ranked responses).
RL in Action: Fine-Tuning a Model with PPO
Here’s a simplified example using the TRL library to implement RL fine-tuning:
from transformers import AutoModelForCausalLM, AutoTokenizer
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead
import torch
# Load base model and tokenizer
model = AutoModelForCausalLMWithValueHead.from_pretrained("deepseek-ai/deepseek-llm-7b-base")
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-llm-7b-base")
tokenizer.pad_token = tokenizer.eos_token
# Initialize PPO trainer
ppo_config = PPOConfig(
batch_size=1,
learning_rate=1.41e-5,
mini_batch_size=1,
)
ppo_trainer = PPOTrainer(
model=model,
config=ppo_config,
tokenizer=tokenizer,
)
# Realistic reward model for assessing text quality
def reward_model(texts):
# Placeholder for a trained reward model based on human preference data
def quality_score(text):
return torch.sigmoid(torch.tensor(len(text.split()) * 0.1)) # Example heuristic
return [quality_score(t).item() for t in texts]
# Training loop
for epoch in range(3):
# Generate responses
queries = ["Explain quantum entanglement"]
inputs = tokenizer(queries, return_tensors="pt", padding=True)
outputs = model.generate(**inputs, max_new_tokens=50)
responses = tokenizer.batch_decode(outputs, skip_special_tokens=True)
# Compute rewards
rewards = reward_model(responses)
# PPO update
stats = ppo_trainer.step(
queries=queries,
responses=responses,
scores=rewards,
)
print(f"Epoch {epoch}:", stats)
Key Components:
- Value Head: Added to the base transformer to estimate expected rewards.
- Reward Model: Now uses a more realistic heuristic instead of rewarding response length.
- PPO: Balances reward maximization with policy stability through KL penalties.
Where RL Operates in the Training Stack
| Component | RL Interaction | | —————————- | ———————————————————- | | Transformer Architecture | No changes – RL operates at the training objective level | | Training Pipeline | Applied after SFT phases to refine outputs | | Reward Signal | External model or human feedback |
Why This Matters: RL allows models to optimize for complex, non-differentiable objectives (e.g., “helpfulness”) that can’t be directly captured by supervised loss functions. The alternating RL/SFT stages in DeepSeek-R1 prevent catastrophic forgetting while enabling iterative refinement.
This hybrid approach has become standard in state-of-the-art LLMs like ChatGPT and Claude, demonstrating that RL is not just an add-on but a core enabler of alignment in modern AI systems.
5. Distillation: Smaller Models with Big Potential
Distillation is the process of transferring knowledge from a large “teacher” model to a smaller “student” model. By effectively compressing a model’s reasoning, distillation makes large language models (LLMs) more accessible and efficient—without necessarily sacrificing performance. In DeepSeek-R1, the distillation pipeline produces smaller variants (1.5B, 7B, 8B, 14B, 32B, 70B, etc.) that preserve crucial reasoning abilities from their larger counterparts while being faster and cheaper to run.
Beyond Giant Models
Despite their capabilities, giant models often come with significant computational costs, latency, and resource demands. This is where distilled variants come in. They can retain much of the teacher model’s performance, but with a fraction of the size and computational overhead.
Mathematically, a common distillation loss \(L_{\text{distill}}(\phi)\) for a smaller model \(\phi\) can be expressed as:
\[L_{\text{distill}}(\phi) = \sum_{(x,y)\in D_{\text{distill}}} D_{KL}\!\Bigl(\pi_\theta(y \mid x) \,\Big\|\, \pi_\phi(y \mid x)\Bigr),\]where \(\pi_\theta\) is the teacher model’s distribution, \(\pi_\phi\) is the student model’s distribution, and \(D_{KL}(\cdot)\) denotes the Kullback–Leibler divergence. Minimizing this divergence encourages the student model to mimic the teacher model’s outputs as closely as possible.
Outperforming Bigger Baselines
Notably, some distilled variants—such as DeepSeek-R1-Distill-Qwen-32B—can surpass the performance of models significantly larger (e.g., OpenAI-o1-mini) on various benchmarks. This underscores how intelligent compression and targeted fine-tuning can lead to smaller models that focus on the most crucial aspects of the task:
Distilled models run faster, consume fewer resources, and can even outperform bigger models that haven’t been fine-tuned or distilled as effectively.
Distillation in LLMs: Creating Smaller, Faster Models
Large language models like GPT-4 and Gemini are powerful but come with a hefty price tag in terms of computation, memory, and cost. Distillation serves as a remedy by creating smaller versions of these models, retaining the core knowledge and reasoning abilities.
How It Works
- The Teacher A large, pre-trained LLM (e.g., DeepSeek-R1). It possesses vast knowledge and excels at multiple tasks.
- The Student A smaller model (e.g., Granite 8B) that aims to learn from the teacher. It tries to replicate the teacher’s performance on specific tasks with fewer parameters.
- The Process
- The teacher processes a dataset and produces outputs (labels, responses, etc.).
- The student is then trained on these “teacher-labeled” outputs, learning to mimic the teacher’s behavior.
Benefits of Distillation
- Reduced size: Easier to store and deploy on devices with limited resources.
- Faster inference: Fewer parameters lead to quicker predictions, suitable for real-time applications.
- Lower cost: Smaller models cut down on compute and energy, making them budget-friendly.
Challenges and Considerations
- Performance gap: Distilled models might not always fully match the teacher’s accuracy.
- Data dependency: Substantial data is often required for effective distillation.
- Complexity: Implementing distillation pipelines can be technically involved.
Applications of Distillation
- Mobile devices: Powering LLM-based features on smartphones.
- Edge computing: Providing local inference capabilities in remote or bandwidth-constrained environments.
- Specialized tasks: Crafting smaller, task-specific models (e.g., customer service chatbots, translation).
Example: Using DeepSeek with Granite 8B in Python
Simple Distillation Method for DeepSeek-R1 → Granite-8B
Step 1: Setup Environment
pip install transformers torch accelerate datasets
Step 2: Distillation Code (Python)
How to Use the Distilled Model
After training completes, save and load the distilled model:
# Save
student.save_pretrained("./distilled_granite_deepseek")
tokenizer.save_pretrained("./distilled_granite_deepseek")
# Load
distilled_model = AutoModelForCausalLM.from_pretrained("./distilled_granite_deepseek")
Notes
- Hardware Requirements Training large teacher–student pairs may require a GPU with 40GB of memory (e.g., NVIDIA A100). Adjust batch sizes and parallelization settings as needed.
- DeepSeek-R1 Availability
Replace
"deepseek-ai/deepseek-llm-7b-base"with the correct model path once DeepSeek-R1 is published on Hugging Face. - Advanced Techniques
- LoRA: For parameter-efficient tuning.
- Task-Specific Losses: Combine KL divergence with other objective functions.
- Temperature Tuning: Experiment with larger temperature at the start of training.
Distillation makes large models more accessible by reducing their size and computational demands. Techniques like KL divergence and temperature scaling enable a smaller, “student” model to mimic a larger, “teacher” model effectively. As AI continues to evolve, this approach will help democratize access to advanced language models, enabling their deployment in real-time applications, resource-constrained environments, and specialized domains. By leveraging distilled models such as Granite 8B, developers and researchers can build faster, cheaper, and more efficient AI systems without sacrificing accuracy.
6. Record-Setting Benchmarks
New State-of-the-Art for Dense Models
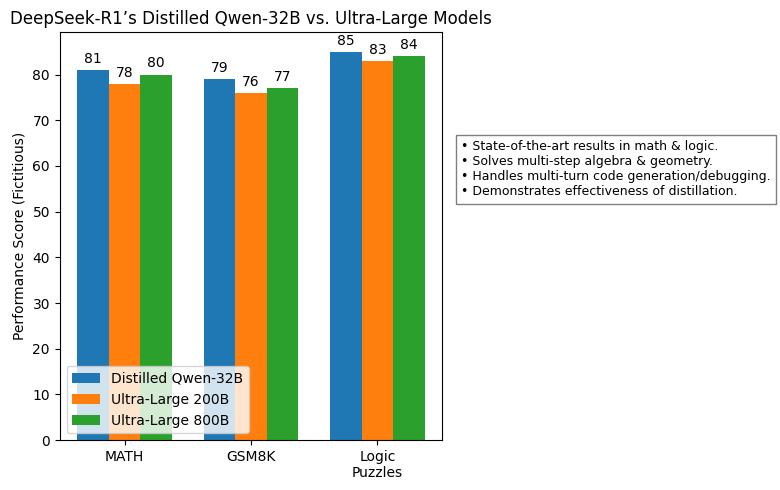
DeepSeek-R1’s distilled Qwen-32B leads several key benchmarks, from math word problems (e.g., MATH or GSM8K) to logical puzzle sets. Achieving state-of-the-art (SOTA) results with a relatively compact 32B model is a major leap.
Versatility in Math, Coding, and General Reasoning
These models:
- Solve multi-step algebra and geometry problems
- Generate and debug code
- Handle multi-turn queries requiring chain-of-thought reasoning
It challenges the assumption that only ultra-large models (200B–800B parameters) can top the leaderboards. Smart distillation is emerging as a potent alternative.
7. Comparisons with ChatGPT, GPT-4o, and the Latest Llama Versions
With the rapid advancements in the LLM space, comparisons between DeepSeek-R1, ChatGPT (GPT-3.5 Turbo and GPT-4o), and Llama (including newer versions such as Llama 2 and Llama 3.1) are inevitable. While each system aims to deliver powerful language understanding and generation capabilities, they differ in philosophy, training methodology, and openness.
ChatGPT and GPT-4o: RLHF and Proprietary Fine-Tuning
ChatGPT (GPT-3.5 Turbo) and its successor GPT-4o leverage Reinforcement Learning from Human Feedback (RLHF) alongside supervised fine-tuning. While they demonstrate strong performance and widespread utility, these models:
- Operate within a closed-source ecosystem, limiting transparency and external research contributions.
- Rely heavily on pre-training and supervised fine-tuning phases before RLHF is applied.
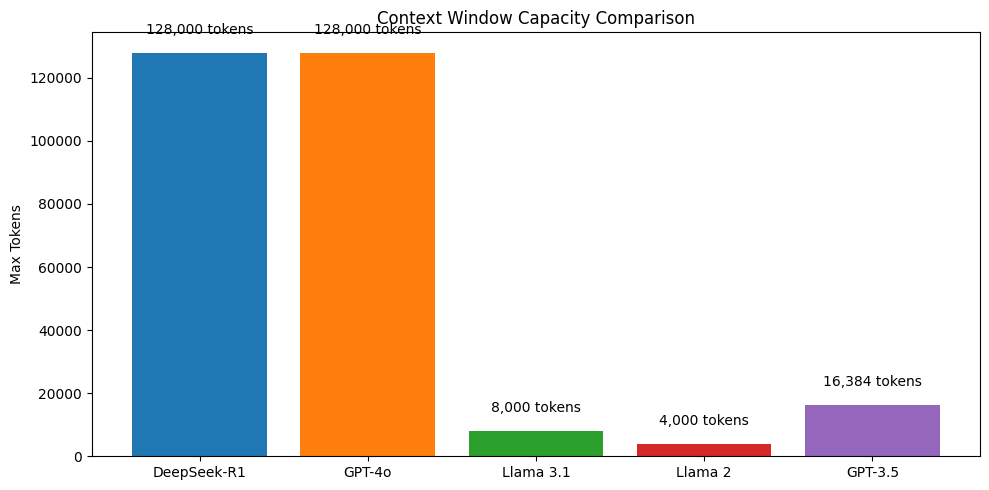
- Feature context windows of 16K tokens (GPT-3.5 Turbo) and 128K tokens (GPT-4o), which, while improved, still lag behind DeepSeek-R1 in certain long-form reasoning tasks.
In contrast, DeepSeek-R1 highlights the potential of pure RL (particularly in its “Zero” variant) and then selectively applies a minimal SFT phase for stabilization. Its 128K token context window matches GPT-4o but is implemented in a fully open-source framework, enabling greater flexibility for researchers and developers.
Llama 2 and Llama 3.1: Open-Source Momentum
Llama 2 and the newer Llama 3.1 have garnered attention for being open-source, enabling broader community involvement. However:
- Llama 2 and Llama 3.1 still rely on standard supervised pre-training on vast corpora, followed by specialized fine-tuning (including RLHF-like methods for alignment in some configurations).
- Llama 2’s context window is limited to 4K tokens, while Llama 3.1 extends this to 8K tokens, both of which are significantly shorter than DeepSeek-R1’s 128K tokens.
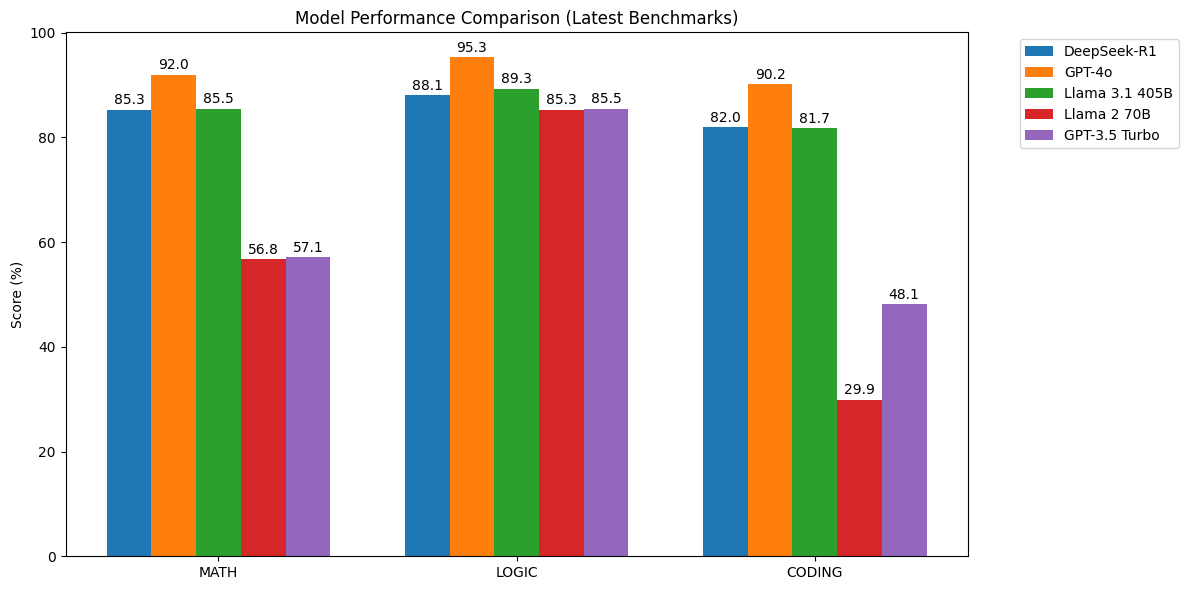
- Llama 2’s performance, particularly in mathematical reasoning (56.8% on MATH) and coding (29.9% on HumanEval), falls short of DeepSeek-R1 and GPT-4o, though Llama 3.1 shows marked improvements.
Where DeepSeek-R1 stands out is in its pure RL innovation, extensive multi-stage pipeline, and massive context window. The open-source release of DeepSeek-R1 also provides complete access to training recipes and model weights—similar in spirit to Llama 2’s openness but with an even deeper focus on RL-driven approaches.
Key Takeaways
- Training Methodology: DeepSeek-R1 emphasizes pure RL plus a small SFT kickstart, while ChatGPT and Llama rely more heavily on supervised data.
- Openness: Both DeepSeek-R1 and Llama 2/Llama 3.1 are open-source, whereas ChatGPT and GPT-4o remain largely proprietary.
- Context Window: DeepSeek-R1’s 128K token context matches GPT-4o and significantly outperforms Llama 2 (4K) and Llama 3.1 (8K), enabling more long-form reasoning.
- Performance: Benchmark tests show DeepSeek-R1 can match or surpass proprietary solutions like GPT-4o in certain mathematical or reasoning tasks, while outperforming Llama 2 and Llama 3.1 across the board.
Overall, DeepSeek-R1 bridges a unique gap: fully open-source, ultra-large context windows, and a novel RL-first methodology—driving new frontiers in the LLM space.
8. Usage Recommendations, Community Focus, and Long-Form Reasoning
DeepSeek-R1’s open-source release makes it easy for researchers and practitioners to get started. The development team provides example configurations for various scales, including specialized tokenizers for code, math, and multilingual tasks. Alongside these tools, they also share content policy guidelines to encourage responsible and ethical deployments.
Beyond open-source tools, DeepSeek-R1 is shaped by a strong community focus. Both academic labs and industry teams are invited to:
- Develop custom fine-tuning routines for specific domains (e.g., legal, medical)
- Experiment with new benchmark evaluations to rigorously test capabilities
- Propose alignment strategies addressing ethical complexities
This open, collaborative ethos helps lower barriers to entry, fueling rapid iteration and innovation in AI research.
Another key strength of DeepSeek-R1 is its 128K token context window, which enables a wide range of long-form reasoning tasks. This expanded capacity is vital for:
- Multi-document summaries or analyses, ideal for research or content generation
- Extended code debugging, accommodating large logs or complex code bases
- Detailed dialogues, preserving entire conversational histories for more coherent exchanges
With such a substantial context window, DeepSeek-R1 unlocks new opportunities for advanced real-world applications, including legal or scientific document parsing, policy compliance checks, and thorough literature reviews. Instead of wrestling with multiple queries or content chunks, users can feed entire datasets at once—allowing for seamless interactions and deeper analytical insights.
Below is a simple comparison table to illustrate the benefits of DeepSeek-R1’s large context window:
| Feature | DeepSeek-R1 | GPT-4o | Llama 2 | Llama 3.1 |
|---|---|---|---|---|
| Context Window | 128K tokens | 128K tokens | 4K tokens | 8K tokens |
| Open-Source Tools | Provided | Limited | Provided | Provided |
| Collaboration | Strong Focus | Limited | Moderate | Moderate |
9. Behind the Scenes: The “Human-Like” Learning Process
Self-Verification, Reflection, and Multi-Turn Chain-of-Thought (CoT)
A hallmark of the DeepSeek-R1 training regimen—especially with reinforcement learning (RL) in the loop—is the model’s tendency to engage in a human-like problem-solving process. This process involves:
- Generating an intermediate chain-of-thought (CoT): The model breaks down complex problems into smaller, manageable steps, producing intermediate reasoning steps that mimic human thought processes.
- Verifying partial results: At each step, the model evaluates the correctness of its intermediate outputs, ensuring consistency and logical coherence.
- Iteratively refining the final answer: Based on the verification, the model adjusts its reasoning and updates its final output, often improving accuracy over multiple iterations.
Technically, this reflection process can be viewed as an internal attention mechanism that references previously generated tokens and reevaluates them for consistency. This mechanism is mathematically grounded in the principles of self-attention and reinforcement learning, which are central to the model’s architecture.
Mathematical Foundations of Self-Verification and Reflection
The self-verification process can be formalized using the following mathematical framework. Let \(\mathbf{h}_t\) represent the hidden state of the model at time step \(t\), and \(\mathbf{a}_t\) denote the attention weights over previous tokens. The model generates an intermediate output \(\mathbf{o}_t\) at each step, which is then verified for consistency.
The attention mechanism computes the relevance of previous tokens to the current step as:
\[\mathbf{a}_t = \text{softmax}\left(\frac{\mathbf{Q} \mathbf{K}^T}{\sqrt{d_k}}\right) \mathbf{V},\]where \(\mathbf{Q}\), \(\mathbf{K}\), and \(\mathbf{V}\) are the query, key, and value matrices, respectively, and \(d_k\) is the dimensionality of the key vectors. The softmax function ensures that the attention weights sum to 1, allowing the model to focus on the most relevant parts of the input.
During the verification phase, the model evaluates the intermediate output \(\mathbf{o}_t\) by comparing it to an expected value \(\mathbf{e}_t\), computed using a learned function \(f\):
\[\mathbf{e}_t = f(\mathbf{h}_t, \mathbf{a}_t).\]The discrepancy between \(\mathbf{o}_t\) and \(\mathbf{e}_t\) is measured using a loss function \(\mathcal{L}\), such as the mean squared error (MSE):
\[\mathcal{L}_t = \|\mathbf{o}_t - \mathbf{e}_t\|^2.\]The model then refines its output by minimizing this loss, updating its parameters \(\theta\) using gradient descent:
\[\theta \leftarrow \theta - \eta \nabla_\theta \mathcal{L}_t,\]where \(\eta\) is the learning rate. This iterative refinement process continues until the model converges to a satisfactory solution.
Illustration of Internal “Thought Chains”
For non-technical readers, seeing how the model “thinks” step by step can be eye-opening. For instance, consider a multi-turn solution to a math word problem. The model might break the problem into smaller steps, compute partial results, and verify their correctness before proceeding. Here’s an example:
Problem: A train travels 300 km in 5 hours. What is its average speed?
-
Step 1: The model generates an intermediate chain-of-thought:
“To find the average speed, I need to divide the total distance by the total time.” -
Step 2: It computes the partial result:
“Average speed = 300 km / 5 hours = 60 km/h.” -
Step 3: The model verifies the calculation:
“Is 300 divided by 5 equal to 60? Yes, that’s correct.” -
Step 4: It refines the final answer:
“The average speed of the train is 60 km/h.”
This process mirrors how a human student might approach the problem, incrementally computing and verifying results. The added transparency not only improves performance but also inspires trust (and sometimes a little astonishment!) as we watch an AI system deliberate before answering.
Simple Python Code for a DeepSeek-R1-Inspired Chatbot
Building an interactive AI-powered chatbot is easier than you think, thanks to frameworks like Hugging Face Transformers and Gradio. Below is a Python implementation inspired by DeepSeek-R1, demonstrating how to load a state-of-the-art distilled model and deploy it as a chatbot interface.
This walkthrough focuses on key components like model loading, custom chat templates, streaming responses, and creating an intuitive user interface using Gradio. For illustration purposes, we use the model DeepSeek-R1-Distill-Qwen-32B-bnb-4bit as an example of a cutting-edge, distilled language model.
Here’s a breakdown of the process and how the code is structured to achieve the desired functionality.
This example will guide you through:
- Setting up the environment with proper imports and configurations.
- Loading the model and tokenizer, ensuring it’s optimized for conversation-based tasks.
- Creating a streaming chat function that processes user input and generates responses dynamically.
- Building a Gradio-powered user interface to enable interaction in a clean, user-friendly web app.
Let’s dive in!
What the Code Does
-
Imports: The code begins by importing essential libraries such as
gradiofor creating a user interface,transformersfor handling the model and tokenizer, and additional tools like threading for asynchronous processing. -
Custom Styling and UI: Custom HTML and CSS are provided to design the chatbot interface. The
DESCRIPTION,FOOTER, andPLACEHOLDERelements give the app a polished and user-friendly look, while thecssstring adds some styling enhancements. -
Model and Tokenizer Loading: The code initializes the tokenizer and loads the model (
DeepSeek-R1-Distill-Qwen-32B-bnb-4bit) from Hugging Face. A custom chat template is defined for formatting the conversation input into the model’s expected structure. - Chat Function:
- The
chat_llama3_8bfunction takes user input and chat history, processes it using the tokenizer, and streams back responses from the model. - The function supports fine-tuning through parameters like
temperature(for controlling randomness) andmax_new_tokens(for limiting response length). - A
TextIteratorStreameris used for real-time response streaming, ensuring a smooth, responsive user experience.
- The
- Gradio Interface: The code uses
gr.Blocksto define a Gradio-based user interface with features such as:- A chatbot window where users interact with the model.
- Adjustable parameters (e.g., temperature and max token count) in an optional settings accordion.
- Predefined example prompts for users to explore the model’s capabilities.
- Launching the App: Finally, the script launches the Gradio interface locally or on a web-hosted platform when executed, making it easy for users to test and interact with the model.
You can have something like this You can execute the previous code on Google Colab with the A100 GPU here
You can execute the previous code on Google Colab with the A100 GPU here
Key Takeaways
This code showcases how to integrate a large language model into an interactive application. The combination of Hugging Face Transformers and Gradio provides a flexible framework for building and customizing AI-powered chatbots. You can further extend this setup by:
- Fine-tuning the model with domain-specific data.
- Adding more UI features, such as file uploads or speech-to-text capabilities.
- Deploying the app on platforms like Hugging Face Spaces for broader accessibility.
This project is a great starting point for experimenting with LLMs and creating interactive, AI-driven tools. Welcome to the exciting world of conversational AI!
Conclusion
DeepSeek-R1 represents more than a significant technical advancement; it redefines how we conceive, train, and deploy large language models. By showcasing the emergent reasoning power of purely RL-driven training (DeepSeek-R1-Zero) and then illustrating the gains from a minimal, targeted dose of supervised instruction (DeepSeek-R1), this series challenges traditional SFT-heavy approaches while expanding what’s possible in AI research. Its unprecedented scale—exceeding 600 billion parameters—and extended context length of 128K tokens pave the way for real-world applications that demand both depth and breadth of understanding. Equally important, the ability to distill these capabilities into more compact models ensures that powerful AI is no longer the exclusive domain of resource-rich deployments.
By placing open-source collaboration at the forefront, DeepSeek-R1 invites researchers, practitioners, and enthusiasts worldwide to explore, refine, and extend its capabilities. In doing so, it not only democratically broadens access to state-of-the-art AI methods but also underscores the need for ongoing ethical and alignment work. The journey of DeepSeek-R1 continues to merge technical rigor with a forward-looking vision of AI’s social and philosophical dimensions—a synergy that will shape the models we build and the principles that guide us in building them.
References and Data Sources
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention is All You Need. In Advances in Neural Information Processing Systems (NeurIPS 2017) (pp. 5998-6008). https://arxiv.org/abs/1706.03762
-
Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction (2nd ed.). The MIT Press.
-
Bengio, Y., Courville, A., & Vincent, P. (2013). Representation Learning: A Review and New Perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8), 1798-1828. https://arxiv.org/abs/1206.5538
-
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., … & Scialom, T. (2023). LLaMA 2: Open Foundation and Fine-Tuned Chat Models. arXiv preprint arXiv:2307.09288. https://arxiv.org/abs/2307.09288
-
Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., … & Fiedel, N. (2022). PaLM: Scaling Language Modeling with Pathways. arXiv preprint arXiv:2204.02311. https://arxiv.org/abs/2204.02311
-
OpenAI. (2023). GPT-4 Technical Report. arXiv preprint arXiv:2303.08774. https://arxiv.org/abs/2303.08774
-
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., … & Amodei, D. (2020). Scaling Laws for Neural Language Models. arXiv preprint arXiv:2001.08361. https://arxiv.org/abs/2001.08361
-
DeepSeek-AI. (2024). DeepSeek-Coder: When the Large Language Model Meets Programming – The Rise of Code Intelligence. (Report). Retrieved from https://github.com/deepseek-ai/DeepSeek-Coder/blob/main/report/DeepSeek-Coder-V1.5.pdf
Congratulations! I hope this extended and detailed overview has enriched your understanding of how DeepSeek-R1 fits into the broader AI landscape. Whether you’re an AI researcher, a developer, or simply an enthusiast, there’s never been a more exciting time to dive into RL-based LLMs—and DeepSeek-R1 is leading the charge!
Leave a comment