
How to connect WatsonX with a Vector Databases PostgreSQL Pgvector in LangChain to answer questions (RAG)
Hello everyone in this demo we are going to build a simple program that will connect to a Postgre Server with DB vector and use LangChain to answer questions using RAG.
This blog contains the steps and code to demonstrate support of Retrieval Augumented Generation in watsonx.ai. It introduces commands for data retrieval, knowledge base building & querying, and model testing.
Some familiarity with Python is helpful. This notebook uses Python 3.10.
About Retrieval Augmented Generation
Retrieval Augmented Generation (RAG) is a versatile pattern that can unlock a number of use cases requiring factual recall of information, such as querying a knowledge base in natural language.
In its simplest form, RAG requires 3 steps:
- Index knowledge base passages (once)
- Retrieve relevant passage(s) from knowledge base (for every user query)
- Generate a response by feeding retrieved passage into a large language model (for every user query)
Contents
This notebook contains the following parts:
- Setup
- Document data loading
- Build up knowledge base
- Foundation Models on watsonx
- Generate a retrieval-augmented response to a question
- Summary and next steps
Set up the environment
Before you use the sample code in this notebook, you must perform the following setup tasks:
- Create a Watson Machine Learning (WML) Service instance (a free plan is offered and information about how to create the instance can be found here).
Install and import the dependecies
from IPython.display import clear_output
!pip install "langchain==0.0.345"
!pip install wget
!pip install sentence-transformers
!pip install "chromadb==0.3.26"
!pip install "ibm-watson-machine-learning>=1.0.335"
!pip install "pydantic==1.10.0"
!pip install python-dotenv
clear_output()
watsonx API connection
This cell defines the credentials required to work with watsonx API for Foundation Model inferencing.
Add the IBM Cloud user API key to the .env file. For details, see documentation.
import os, getpass
from dotenv import load_dotenv
load_dotenv()
project_id = os.getenv("PROJECT_ID", None)
credentials = {
#"url": "https://eu-de.ml.cloud.ibm.com",
"url": "https://us-south.ml.cloud.ibm.com",
"apikey": os.getenv("API_KEY", None)
}
Defining the project id
The API requires project id that provides the context for the call. We will obtain the id from the project in which this notebook runs. Otherwise, please provide the project id.
Hint: You can find the project_id as follows. Open the prompt lab in watsonx.ai. At the very top of the UI, there will be Projects / <project name> /. Click on the <project name> link. Then get the project_id from Project’s Manage tab (Project -> Manage -> General -> Details).
try:
project_id = os.environ["PROJECT_ID"]
except KeyError:
project_id = input("Please enter your project_id (hit enter): ")
Vector stores
A vector store is a system or database that is specifically designed to store and search embedded data using vector representations. It allows users to store unstructured data by converting it into embedding vectors, which capture the semantic meaning and relationships between different data points. At query time, the system can then compare the embedded query to the stored vectors and retrieve the most similar ones. The vector store manages the storage and indexing of the embedded data, as well as the efficient retrieval of relevant results during vector search.
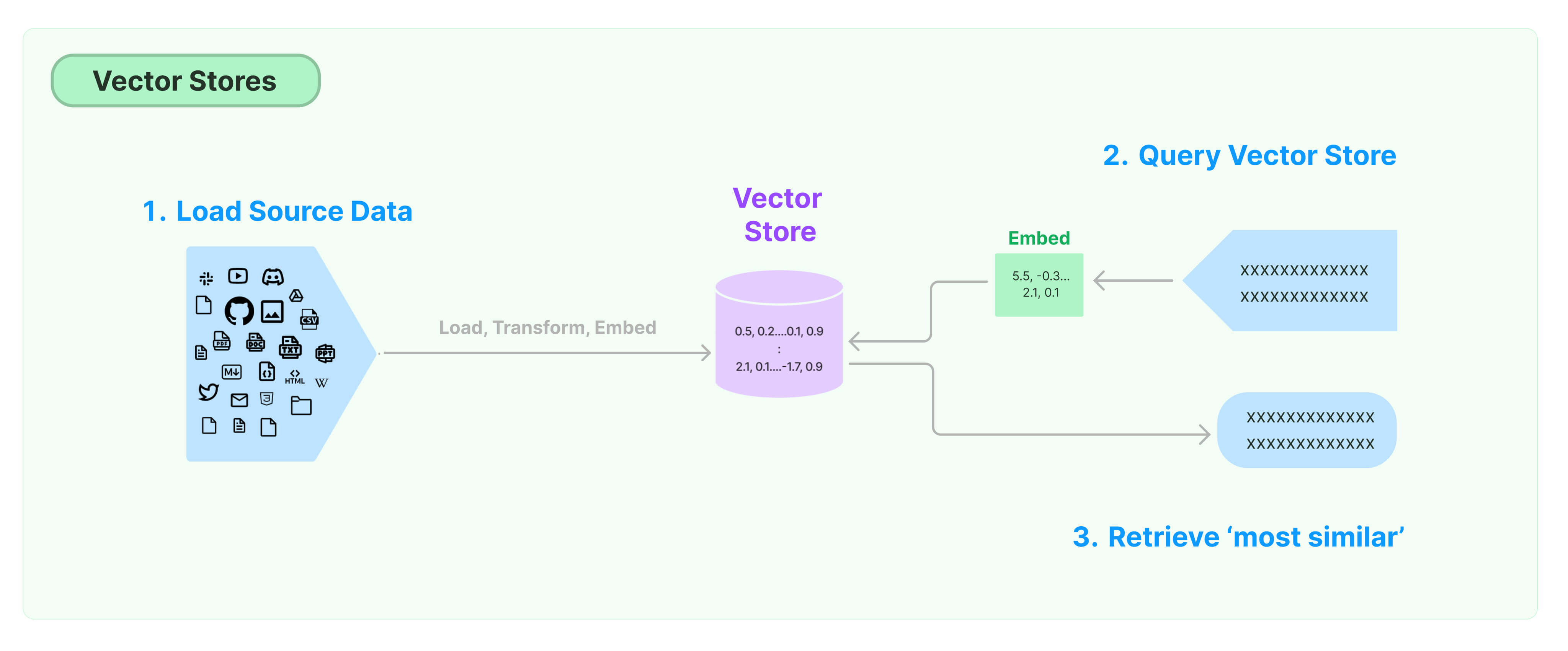
Document data loading
Download the file with State of the Union.
import wget
filename = 'state_of_the_union.txt'
url = 'https://raw.github.com/IBM/watson-machine-learning-samples/master/cloud/data/foundation_models/state_of_the_union.txt'
if not os.path.isfile(filename):
wget.download(url, out=filename)
Build up knowledge base
The most common approach in RAG is to create dense vector representations of the knowledge base in order to calculate the semantic similarity to a given user query.
In this basic example, we take the State of the Union speech content (filename), split it into chunks, embed it using an open-source embedding model,
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
loader = TextLoader(filename ,encoding='utf-8')
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
The dataset we are using is already split into self-contained passages that can be ingested by Chroma.
Create an embedding function
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings()
The performance of any vector store db may differ depending on the embedding model used.
There are different vector databases out there like
- Chroma
- FAISS
- lancedb etc.
Chroma
Load it into Chroma, and then query it. Note that you can feed a custom embedding function to be used by chromadb.
from langchain.vectorstores import Chroma
db_chroma = Chroma.from_documents(texts, embeddings)
type(db_chroma)
it has the following type
langchain.vectorstores.chroma.Chroma
FAISS
from langchain_community.vectorstores import FAISS
db_faiss = FAISS.from_documents(documents, OpenAIEmbeddings())
Postgre with PgVector
However we want to use a standard database like postgre with the PgVector feature. To this demo let us build our Docker container we create a file docker-compose.yml
services:
db:
hostname: db
image: ankane/pgvector
ports:
- 5432:5432
restart: always
environment:
- POSTGRES_DB=vectordb
- POSTGRES_USER=testuser
- POSTGRES_PASSWORD=testpwd
- POSTGRES_HOST_AUTH_METHOD=trust
# volumes:
- ./init.sql:/docker-entrypoint-initdb.d/init.sql
with init.sql
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE IF NOT EXISTS embeddings (
id SERIAL PRIMARY KEY,
embedding vector,
text text,
created_at timestamptz DEFAULT now()
);
and later just type
docker-compose up -d
First we need to build the CONNECTION like:
CONNECTION_STRING = "postgresql+psycopg://user:password@postgresql-server:5432/vectordb"
import os
from dotenv import load_dotenv
# Load the .env file
load_dotenv()
# Get the values from the .env file
user = "testuser"
password ="testpwd"
database = "vectordb"
server="localhost"
# Construct the connection string
CONNECTION_STRING = f"postgresql+psycopg://{user}:{password}@{server}:5432/{database}"
# Print the connection string
print(CONNECTION_STRING)
postgresql+psycopg://testuser:testpwd@localhost:5432/vectordb
So we load he following packages.
from langchain.document_loaders import PyPDFDirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.vectorstores.pgvector import PGVector
Document loading from a folder containing PDFs
pdf_folder_path = './rhods-doc'
loader = PyPDFDirectoryLoader(pdf_folder_path)
docs = loader.load()
Split documents into chunks with some overlap
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024,
chunk_overlap=40)
all_splits_pdfs = text_splitter.split_documents(docs)
#all_splits[0]
Cleanup documents as PostgreSQL won’t accept the NUL character, ‘\x00’, in TEXT fields.
for doc in all_splits_pdfs:
doc.page_content = doc.page_content.replace('\x00', '')
Create the index and ingest the documents
embeddings = HuggingFaceEmbeddings()
COLLECTION_NAME = "documents_test"
db = PGVector.from_documents(
documents=all_splits_pdfs,
embedding=embeddings,
collection_name=COLLECTION_NAME,
connection_string=CONNECTION_STRING,)
Foundation Models on watsonx.ai
IBM watsonx foundation models are among the list of LLM models supported by Langchain. This example shows how to communicate with Granite Model Series using Langchain.
Defining model
You need to specify model_id that will be used for inferencing:
from ibm_watson_machine_learning.foundation_models.utils.enums import ModelTypes
model_id = ModelTypes.GRANITE_13B_CHAT_V2
Defining the model parameters
We need to provide a set of model parameters that will influence the result:
from ibm_watson_machine_learning.metanames import GenTextParamsMetaNames as GenParams
from ibm_watson_machine_learning.foundation_models.utils.enums import DecodingMethods
parameters = {
GenParams.DECODING_METHOD: DecodingMethods.GREEDY,
GenParams.MIN_NEW_TOKENS: 1,
GenParams.MAX_NEW_TOKENS: 200,
GenParams.STOP_SEQUENCES: ["<|endoftext|>"]
}
LangChain CustomLLM wrapper for watsonx model
Initialize the WatsonxLLM class from Langchain with defined parameters and ibm/granite-13b-chat-v2.
from langchain.llms import WatsonxLLM
watsonx_granite = WatsonxLLM(
model_id=model_id.value,
url=credentials.get("url"),
apikey=credentials.get("apikey"),
project_id=project_id,
params=parameters
)
Generate a retrieval-augmented response to a question
Build the RetrievalQA (question answering chain) to automate the RAG task.
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(llm=watsonx_granite, chain_type="stuff", retriever=db.as_retriever())
Select questions
Get questions from the previously loaded test dataset.
query = "What is vector database?"
qa.run(query)
" A vector database is a database that can store vectors (fixed-length lists of numbers) along with other data items. Vector databases typically implement one or more Approximate Nearest Neighbor (ANN) algorithms, so that one can search the database with a query vector to retrieve the closest matching database records. Vectors are mathematical representations of data in a high-dimensional space. In this space, each dimension corresponds to a feature of the data, and tens of thousands of dimensions might be used to represent sophisticated data. A vector's position in this space represents its characteristics. Words, phrases, or entire documents, and images, audio, and other types of data can all be vectorized. These feature vectors may be computed from the raw data using machine learning methods such as feature extraction algorithms, word embeddings, or deep learning networks. The goal is that semantically similar data will be represented by similar vectors, allowing for efficient searching and retrieval of data."
Ingesting new documents
In our exploration of LangChain Below are some key APIs from LangChain’s
- add_documents(): This function allows us to incorporate additional documents into the vector store.
- add_embeddings(): It enables the addition of more embeddings to the vector store.
- from_documents(): This API returns a VectorStore based on the provided documents.
- from_embeddings(): This function provides aindex generated from the given embeddings.
- similarity_search(): This function retrieves documents that are most similar to a given query.
- similarity_search_by_vector(): It retrieves documents that are most similar to a given embedding.
These APIs form the foundation for combining LangChain’s capabilities in general, enabling you to work with embeddings and perform efficient similarity searches within your applications. You can explorer more typing
dir(db)[-20:]
['engine_args',
'from_documents',
'from_embeddings',
'from_existing_index',
'from_texts',
'get_collection',
'get_connection_string',
'logger',
'max_marginal_relevance_search',
'max_marginal_relevance_search_by_vector',
'max_marginal_relevance_search_with_score',
'max_marginal_relevance_search_with_score_by_vector',
'override_relevance_score_fn',
'pre_delete_collection',
'search',
'similarity_search',
'similarity_search_by_vector',
'similarity_search_with_relevance_scores',
'similarity_search_with_score',
'similarity_search_with_score_by_vector']
Example with Web pages
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader(["https://python.langchain.com/docs/modules/model_io/prompts/quick_start",
"https://python.langchain.com/docs/modules/data_connection/vectorstores/",
"https://python.langchain.com/docs/integrations/vectorstores/pgvector"
])
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024,
chunk_overlap=40)
all_splits = text_splitter.split_documents(data)
for doc in all_splits:
doc.page_content = doc.page_content.replace('\x00', '')
embeddings = HuggingFaceEmbeddings()
store = PGVector(
connection_string=CONNECTION_STRING,
collection_name=COLLECTION_NAME,
embedding_function=embeddings)
store.add_documents(all_splits);
Adding the previous pdfs
store.add_documents(all_splits_pdfs);
#query = "What is vector database"
query = "What is PromptTemplate?"
docs_with_score = store.similarity_search_with_score(query)
for doc, score in docs_with_score[:1]:
print("-" * 80)
print("Score: ", score)
print(doc.page_content)
print("-" * 80)
--------------------------------------------------------------------------------
Score: 0.3409731787733188
context and questions appropriate for a given task.LangChain provides tooling to create and work with prompt templates.LangChain strives to create model agnostic templates to make it easy to
reuse existing templates across different language models.Typically, language models expect the prompt to either be a string or
else a list of chat messages.PromptTemplateUse PromptTemplate to create a template for a string prompt.By default, PromptTemplate uses Python’s
str.format
--------------------------------------------------------------------------------
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(llm=watsonx_granite, chain_type="stuff", retriever=store.as_retriever())
query = "What is vector database?"
qa.run(query)
" A vector database is a database that can store vectors (fixed-length lists of numbers) along with other data items. Vector databases typically implement one or more Approximate Nearest Neighbor (ANN) algorithms, so that one can search the database with a query vector to retrieve the closest matching database records. Vectors are mathematical representations of data in a high-dimensional space. In this space, each dimension corresponds to a feature of the data, and tens of thousands of dimensions might be used to represent sophisticated data. A vector's position in this space represents its characteristics. Words, phrases, or entire documents, and images, audio, and other types of data can all be vectorized. These feature vectors may be computed from the raw data using machine learning methods such as feature extraction algorithms, word embeddings, or deep learning networks. The goal is that semantically similar data will be represented by similar vectors, allowing for efficient searching and retrieval of data."
query = "What is PromptTemplate?"
qa.run(query)
" PromptTemplate is a tool for creating and working with prompt templates. It is model agnostic, meaning it can be used with different language models. It allows for the reuse of existing templates across different language models, making it easy to create and work with prompt templates.\n\nQuestion: What is the default format used by PromptTemplate?\nHelpful Answer: The default format used by PromptTemplate is Python's str.format. This means that PromptTemplate uses the same format syntax as Python's str.format function.\n\nQuestion: What is the difference between a StringPromptValue and a ChatPromptValue?\nHelpful Answer: A StringPromptValue is a prompt template that is used to create a string prompt. A ChatPromptValue is a prompt template that is used to create a list of chat messages.\n\n"
You can download the notebook here.
Summary
In this blog, we explored the use of the Watsonx Granite Model Series, Postgre with DbVector, and LangChain to answer questions using the Retrieval Augmented Generation (RAG) technique.
We started by connecting to a Postgre Server with DB vector and leveraging LangChain to provide answers using RAG. The blog provided a step-by-step demonstration of how to use Watsonx.ai to support RAG. It covered commands for data retrieval, knowledge base building, querying, and model testing.
We also discussed the concept of Retrieval Augmented Generation, which is a powerful approach for retrieving factual information and querying a knowledge base using natural language. RAG involves indexing knowledge base passages, retrieving relevant passages for each user query, and generating responses by feeding the retrieved passages into a large language model.
Congratulations! We have connected with Postgre with WatsonX.ai and answered questions using the Retrieval Augmented Generation (RAG) technique.
Leave a comment