
Give LangChain, LangGraph & CrewAI Real Memory With Matrix Context
Hello everyone. In a previous post we gave a plain Python chatbot a memory in three lines. Today we go one step further and wire that same memory into the three frameworks most agents are actually built with — LangChain, LangGraph, and CrewAI — using Matrix Context. We will download a real document from the internet, ingest it once, and then query it from each framework, and I will be honest about when this beats a plain vector database and when it does not.
The shape is always the same: ingest once into typed memory, then recall from anywhere.

Step 1 — download and ingest a real document
No toy strings. We pull a real page off the web, chunk it, and store it in the document expert. Matrix Context is local-first, so this is a single file on disk with no service to run.
import urllib.request
import matrix_context as mc
URL = "https://en.wikipedia.org/wiki/PostgreSQL"
req = urllib.request.Request(URL, headers={"User-Agent": "matrix-context-demo/0.1"})
text = urllib.request.urlopen(req, timeout=30).read().decode("utf-8", "ignore")
memory = mc.open("docs-demo")
# `mc add` accepts text, a file, a folder, or a URL; here we ingest the page text:
for para in (p.strip() for p in text.split("\n\n") if len(p.strip()) > 120):
memory.add(para, expert="document", scope="project:docs")
print(memory.ask("What license is PostgreSQL released under?"))
memory.ask(...) returns a prompt-ready context pack. memory.pack(...) returns the structured object (kept items, scores, dropped items) if your agent code wants the details. Everything below simply calls one of those two.
LangChain — a memory-backed retriever
In LangChain, memory is a Retriever. We wrap Matrix Context so it drops straight into any chain or agent.
from langchain_core.retrievers import BaseRetriever
from langchain_core.documents import Document
from pydantic import ConfigDict
class MatrixContextRetriever(BaseRetriever):
model_config = ConfigDict(arbitrary_types_allowed=True)
memory: object
scope: str = "project:docs"
def _get_relevant_documents(self, query, *, run_manager=None):
pack = self.memory.pack(query, scope=self.scope, max_tokens=400)
return [Document(page_content=p.item.content,
metadata={"expert": p.item.expert, "score": p.final_score})
for p in pack.items]
retriever = MatrixContextRetriever(memory=memory)
docs = retriever.invoke("What license is PostgreSQL released under?")
print(docs[0].page_content)
Now any LangChain RAG chain you already have keeps working — but its retrieval is typed and routed, and every document carries the expert and score that earned it a place.
LangGraph — memory as a graph node
LangGraph models an agent as a state machine. Memory becomes two nodes: one that recalls before the model, one that remembers after.
from langgraph.graph import StateGraph, END
from typing import TypedDict
class S(TypedDict):
question: str
context: str
answer: str
def recall(s): return {"context": memory.context_for(s["question"], scope="project:docs")}
def generate(s): return {"answer": llm(f"Context:\n{s['context']}\n\nQ: {s['question']}")}
def remember(s): memory.record_turn(s["question"], s["answer"], scope="project:docs"); return {}
g = StateGraph(S)
g.add_node("recall", recall); g.add_node("generate", generate); g.add_node("remember", remember)
g.set_entry_point("recall")
g.add_edge("recall", "generate"); g.add_edge("generate", "remember"); g.add_edge("remember", END)
app = g.compile()
print(app.invoke({"question": "What does ACID mean in PostgreSQL?"})["answer"])
The graph reads naturally: recall → generate → remember. The agent’s memory is now a first-class part of its control flow, not a side effect buried in a prompt.
CrewAI — memory as a tool
In CrewAI, give your crew a tool they can call to consult memory.
from crewai.tools import BaseTool
class MemoryTool(BaseTool):
name: str = "team_memory"
description: str = "Recall typed, relevant context for a question."
def _run(self, query: str) -> str:
return memory.ask(query, scope="project:docs", max_tokens=400)
# attach MemoryTool() to any agent in your crew
Same engine, three idioms. You ingest once and every framework recalls from the same typed, inspectable store.
Why not just a vector database?
This is the fair question, and the honest answer is: for keyword-aligned lookups over a small corpus, a plain vector store (or Milvus) is perfectly good — and on those queries it is hard to beat. The advantages of typed context routing show up under the conditions real agents actually face:
- Fewer wrong-but-similar hits. A flat index returns whatever is nearest in vector space, so a document chunk that shares a few words with the query can outrank the policy you must never miss. Routing to the right expert first keeps those distractors out of the pack.
- A budgeted, de-duplicated pack — not a top-k dump. Matrix Context assembles a token-budgeted pack scored by relevance, importance, and recency, with redundancy penalized, so the model sees a small, clean context instead of five near-identical chunks.
- Inspectability. You can see the routing decision and every kept/dropped item with its score — something a raw similarity search cannot give you.
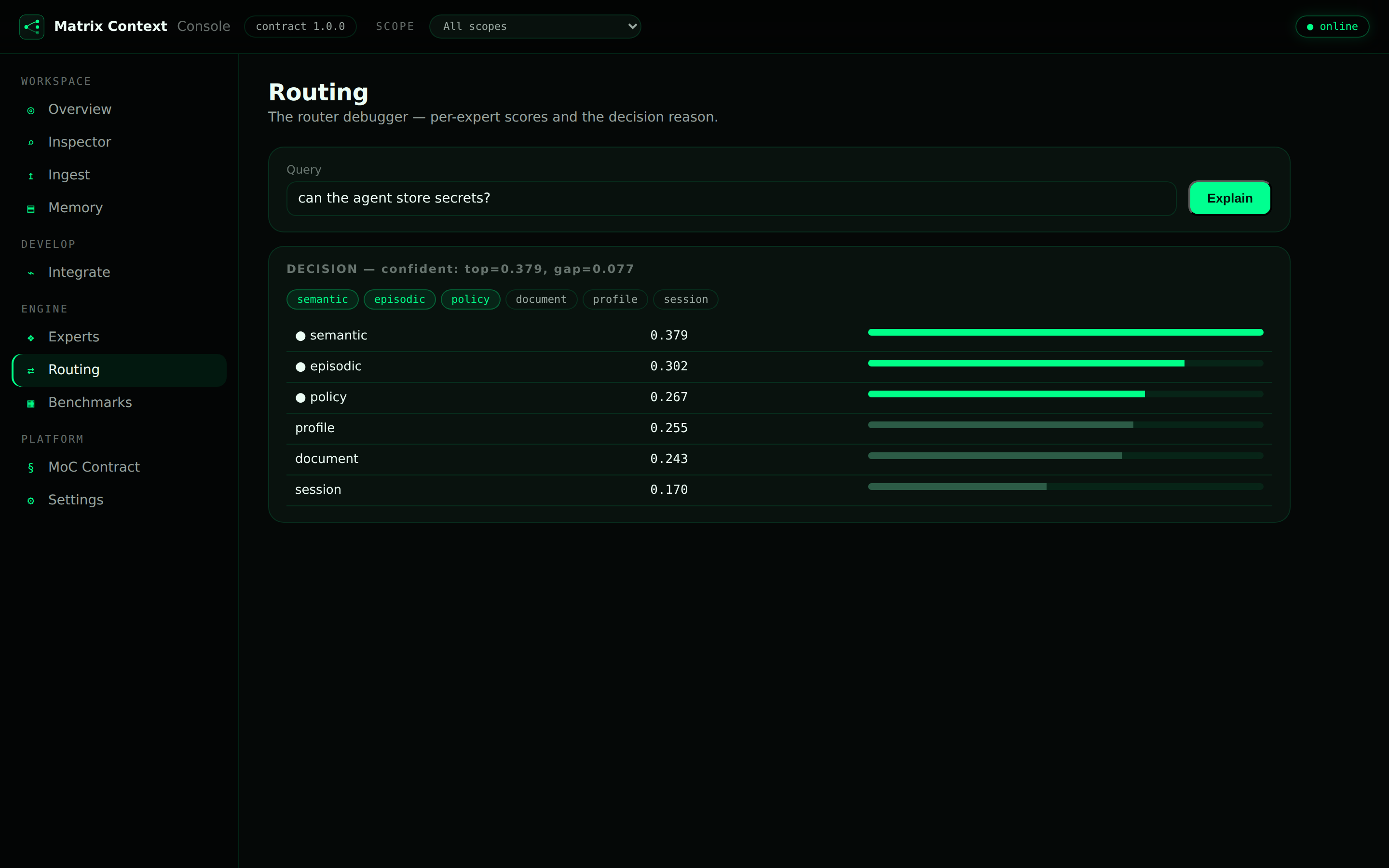
In a public benchmark of typed agent memory, a strong keyword baseline scored a perfect 100 on plain queries and then collapsed by 36 points under adversarial phrasing, while typed routing held within 17, overtook it, and carried roughly half the harmful context. Not “better everywhere” — more robust and more efficient exactly where memory is noisy and queries are messy. The full result, and how to reproduce it, is in the essay A Memory That Knows What It Remembers.
Scaling to the enterprise
The same engine is built to grow up without changing your code:
- Multi-tenant by
scope. Every item and every query carries a scope (project:acme,user:42), so one store cleanly isolates teams, customers, and projects. - Local-first, with SQL as the source of truth. It starts as a single file and scales to a real database; metadata and governance live in SQL, and vectors are a rebuildable accelerator, not the system of record.
- One contract, many surfaces. Python SDK, CLI, and a versioned REST API expose the same objects, so a notebook prototype and a production service speak the same protocol.
- Governed by design. Typed memory with importance and time-to-live is the foundation for policy — what may be stored, what must be recalled, what should expire.
The copy-paste snippets for each surface are built into the Console’s Integrate view, wired to your live server:
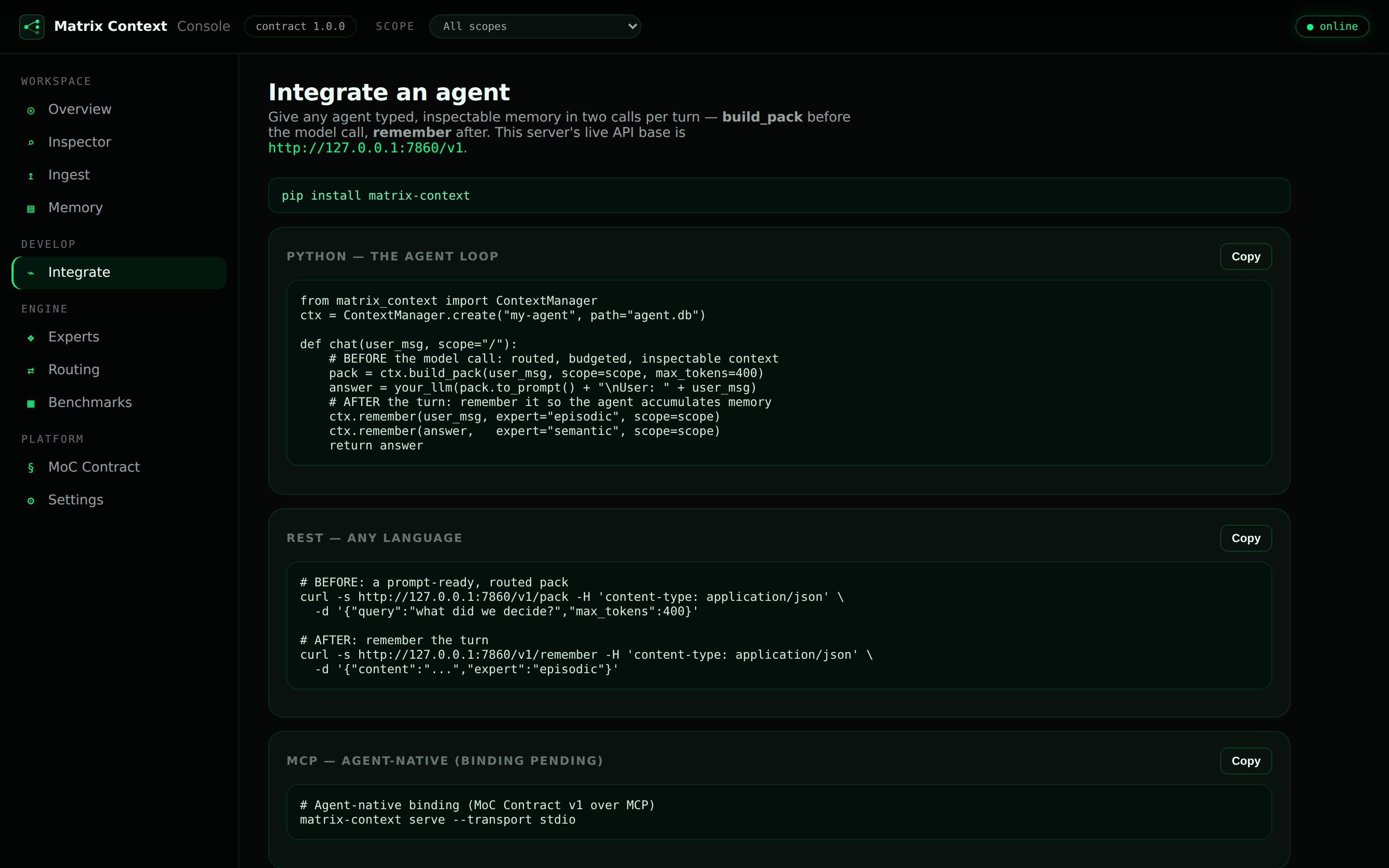
Next steps
- Source & docs — github.com/agent-matrix/matrix-context
- Start simpler — Build your first chatbot with memory
- The thinking behind it — A Memory That Knows What It Remembers
Ingest once, recall anywhere — and always be able to explain what your agent remembered.
Leave a comment