
Text to video with Artificial Intelligence
Hello everyone, today we are going to create a simple application that will generate a video from a text with images generated with Artificial Intelligence.
I am going to use Google Collab to run this program because requires GPU with a lot of memory.
This just an introduction of the amazing world of the generation of synthetic images.
The technique is based on generative adversarial network (GAN) is a machine learning (ML) model in which two neural networks compete with each other to become more accurate in their predictions.
What we are going to create a pipeline that will convert a long text into small sentences that from them will create several pictures which later is processed to create a video with subtitles and synthetic voice.
The story is summarized using DistillBART model. Then, then it is generated the images by using Dalle-mini and create subtitles with speech by using gTTS (Google Text-to-Speech). These are generated as a video.
For example from the following text:
'Once, there was a girl called Laura who went to the supermarket to buy the ingredients to make a cake. Because today is her birthday and her friends come to her house and help her to prepare the cake.'
This AI program will produce the following video:
The interesting point is that from the text that was inserted into the program, the AI program “analyzes the text” and summarizes them into sentences that will be used to generate new images based on generative adversarial networks and putting everything together in a video with subtitles and voice speech.
From the point of view of creation, we may say that this is really an creation of knowledge based on what was learned before. This is a good example about what the AI may achieve.
DistilBERT uses a technique called distillation, which approximates the Google’s BERT, i.e. the large neural network by a smaller one. The idea is that once a large neural network has been trained, its full output distributions can be approximated using a smaller network.
DALL-E is a version of GPT-3 with 12 billion parameters, which is trained to generate image from a text description. While OpenAI may have started with concepts from previous researches which took detailed text captions and generated somewhat meaningful images, the DALL-E reached a very different level. DALL-E can
Step 1 - Libraries Installation
The application that we will use will perform a summary of the text that you will introduce by sing the BART-Model and the generation of the Images will be produced by Dalle-Mini.
-
Dalle mini is a free, open-source AI that produces amazing images from text inputs.
-
The BART Model with a language modeling head. Can be used for summarization. This model inherits from PreTrainedModel.
In the Google Notebook first, we need to install all our libraries needed:
!nvidia-smi
!pip install min-dalle
!pip install gradio -q
!pip install transformers torch requests moviepy huggingface_hub opencv-python
!pip install moviepy
!pip install imageio-ffmpeg
!pip install imageio==2.4.1
!apt install imagemagick
!cat /etc/ImageMagick-6/policy.xml | sed 's/none/read,write/g'> /etc/ImageMagick-6/policy.xml
!pip install mutagen
!pip install gtts
!pip install nltk
#We reset the runtime
#exit()
Sun Aug 21 12:58:13 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 62C P8 11W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting min-dalle
Downloading min-dalle-0.4.11.tar.gz (10 kB)
Once the libraries were installed, we proceed to import the libraries,
Step 2 - Importing Libraries
from moviepy.editor import *
from PIL import Image
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM,pipeline
import requests
import gradio as gr
import torch
import re
import os
import sys
from huggingface_hub import snapshot_download
import base64
import io
import cv2
import nltk
nltk.download('punkt')
If you could import all the previous libraries good!, you are now able to create the application.
Step 3- Creation of the application
In this part we need to write the text that we want to create our video story
text ='Once, there was a girl called Laura who went to the supermarket to buy the ingredients to make a cake. Because today is her birthday and her friends come to her house and help her to prepare the cake.'
you can use any story that you want to test, this is the interesting part.
print(text)
Once, there was a girl called Laura who went to the supermarket to buy the ingredients to make a cake. Because today is her birthday and her friends come to her house and help her to prepare the cake.
and we need to load our summary AI program
tokenizer = AutoTokenizer.from_pretrained("sshleifer/distilbart-cnn-12-6")
model = AutoModelForSeq2SeqLM.from_pretrained("sshleifer/distilbart-cnn-12-6")
Now that have loaded our pretrained ML model to summayse our text we can get the summary
inputs = tokenizer(text,
max_length=1024,
truncation=True,
return_tensors="pt")
summary_ids = model.generate(inputs["input_ids"])
summary = tokenizer.batch_decode(summary_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=False)
plot = list(summary[0].split('.'))
now we need to create the main program that generate the images
import argparse
import os
from PIL import Image
from min_dalle import MinDalle
import torch
def save_image(image: Image.Image, path: str):
if os.path.isdir(path):
path = os.path.join(path, 'generated.png')
elif not path.endswith('.png'):
path += '.png'
print("saving image to", path)
image.save(path)
return image
def generate_image(
is_mega: bool,
text: str,
seed: int,
grid_size: int,
top_k: int,
image_path: str,
models_root: str,
fp16: bool,
):
model = MinDalle(
is_mega=is_mega,
models_root=models_root,
is_reusable=False,
is_verbose=True,
dtype=torch.float16 if fp16 else torch.float32
)
image = model.generate_image(
text,
seed,
grid_size,
top_k=top_k,
is_verbose=True
)
save_image(image, image_path)
im = Image.open("generated.png")
return im
Let us generate the images from our summary text
generated_images = []
for senten in plot[:-1]:
print(senten)
image=generate_image(
is_mega='store_true',
text=senten,
seed=1,
grid_size=1,
top_k=256,
image_path='generated',
models_root='pretrained',
fp16=256,)
display(image)
generated_images.append(image)
and you will get the following output:
Once, Laura went to the supermarket to buy the ingredients to make a cake
using device cuda
downloading tokenizer params
intializing TextTokenizer
tokenizing text
['Ġonce', ',']
['Ġlaura']
['Ġwent']
['Ġto']
['Ġthe']
['Ġsupermarket']
['Ġto']
['Ġbuy']
['Ġthe']
['Ġingredients']
['Ġto']
['Ġmake']
['Ġa']
['Ġcake']
17 text tokens [0, 6619, 11, 7309, 8398, 123, 99, 12553, 123, 403, 99, 13241, 123, 1077, 58, 2354, 2]
downloading encoder params
initializing DalleBartEncoder
encoding text tokens
downloading decoder params
initializing DalleBartDecoder
downloading detokenizer params
initializing VQGanDetokenizer
detokenizing image
saving image to generated.png

Her friends come to her house and help her to prepare the cake
using device cuda
intializing TextTokenizer
tokenizing text
['Ġher']
['Ġfriends']
['Ġcome']
['Ġto']
['Ġher']
['Ġhouse']
['Ġand']
['Ġhelp']
['Ġher']
['Ġto']
['Ġprepare']
['Ġthe']
['Ġcake']
15 text tokens [0, 447, 3103, 4118, 123, 447, 610, 128, 1980, 447, 123, 11147, 99, 2354, 2]
initializing DalleBartEncoder
encoding text tokens
initializing DalleBartDecoder
initializing VQGanDetokenizer
detokenizing image
saving image to generated.png

Because today is her birthday, she has friends help her prepare it for her birthday
using device cuda
intializing TextTokenizer
tokenizing text
['Ġbecause']
['Ġtoday']
['Ġis']
['Ġher']
['Ġbirthday', ',']
['Ġshe']
['Ġhas']
['Ġfriends']
['Ġhelp']
['Ġher']
['Ġprepare']
['Ġit']
['Ġfor']
['Ġher']
['Ġbirthday']
18 text tokens [0, 6177, 1535, 231, 447, 1249, 11, 748, 1238, 3103, 1980, 447, 11147, 353, 129, 447, 1249, 2]
initializing DalleBartEncoder
encoding text tokens
initializing DalleBartDecoder
initializing VQGanDetokenizer
detokenizing image
saving image to generated.png

Laura's friends come and help prepare her to make her birthday cake
using device cuda
intializing TextTokenizer
tokenizing text
['Ġlaura', "'s"]
['Ġfriends']
['Ġcome']
['Ġand']
['Ġhelp']
['Ġprepare']
['Ġher']
['Ġto']
['Ġmake']
['Ġher']
['Ġbirthday']
['Ġcake']
15 text tokens [0, 7309, 168, 3103, 4118, 128, 1980, 11147, 447, 123, 1077, 447, 1249, 2354, 2]
initializing DalleBartEncoder
encoding text tokens
initializing DalleBartDecoder
initializing VQGanDetokenizer
detokenizing image
saving image to generated.png
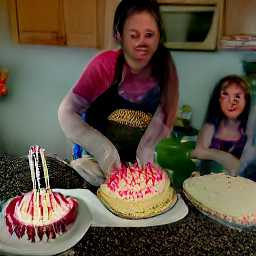
You can identify now, which sentences the AI have been created
for senten in plot[:-1]:
print(senten)
Once, Laura went to the supermarket to buy the ingredients to make a cake
Her friends come to her house and help her to prepare the cake
Because today is her birthday, she has friends help her prepare it for her birthday
Laura's friends come and help prepare her to make her birthday cake
sentences =plot[:-1]
num_sentences=len(sentences)
we just check if everything is okay
assert len(generated_images) == len(sentences) , print('Something is wrong')
let us show all the pictures created by the AI with the sentences
for k in range(len(generated_images)):
display(generated_images[k])
print(sentences[k])

Once, Laura went to the supermarket to buy the ingredients to make a cake

Her friends come to her house and help her to prepare the cake

Because today is her birthday, she has friends help her prepare it for her birthday
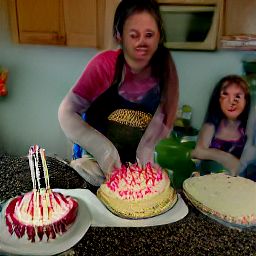
Laura's friends come and help prepare her to make her birthday cake
Step 4 - Creation of the subtitles
There are two ways to create the subtitles
- With Spacy
- WIth NLTK
By default, spaCy uses its dependency parser to do sentence segmentation, which requires loading a statistical model. The sentencizer is a rule-based sentence segmenter that you can use to define your own sentence segmentation rules without loading a model.
import spacy
nlp = spacy.load('en_core_web_sm') # or whatever model you have installed
raw_text = sentences[1]
doc = nlp(raw_text)
subtitles = [sent.text.strip() for sent in doc.sents]
subtitles
for example
['Her friends come to her house and help her to prepare the cake']
let us create the subtitles with spacy
import spacy
nlp = spacy.load('en_core_web_sm') # or whatever model you have installed
c = 0
sub_names = []
for k in range(len(generated_images)):
raw_text = sentences[k]
doc = nlp(raw_text)
subtitles = [sent.text.strip() for sent in doc.sents]
sub_names.append(subtitles)
print(subtitles, len(subtitles))
['Once, Laura went to the supermarket to buy the ingredients to make a cake'] 1
['Her friends come to her house and help her to prepare the cake'] 1
['', 'Because today is her birthday, she has friends help her prepare it for her birthday'] 2
["Laura's friends come and help prepare her to make her birthday cake"] 1
NLTK Tokenizer Package Tokenizers divide strings into lists of substrings. For example, If we want to Return a sentence-tokenized copy of text, using NLTK’s recommended sentence tokenizer
from nltk import tokenize
subtitles=tokenize.sent_tokenize(sentences[1], language='english')
subtitles
[' Her friends come to her house and help her to prepare the cake']
We can generate our list of subtitles
from nltk import tokenize
c = 0
sub_names = []
for k in range(len(generated_images)):
subtitles=tokenize.sent_tokenize(sentences[k])
sub_names.append(subtitles)
print(subtitles, len(subtitles))
[' Once, Laura went to the supermarket to buy the ingredients to make a cake'] 1
[' Her friends come to her house and help her to prepare the cake'] 1
[' Because today is her birthday, she has friends help her prepare it for her birthday'] 1
[" Laura's friends come and help prepare her to make her birthday cake"] 1
sub_names[2]
[' Because today is her birthday, she has friends help her prepare it for her birthday']
Step 5 - Adding Subtitles to the Images
from PIL import ImageDraw
# copying image to another image object
image = generated_images[2].copy()
add_subtitle=sub_names[2][0]
display(image)
print(add_subtitle)

Because today is her birthday, she has friends help her prepare it for her birthday
ImageDraw.Draw(
image # Image
).text(
(0, 0), # Coordinates
add_subtitle, # Text
(0, 0, 0) # Color
)
display(image)

We need a program to determine the size of text, a simple alternative can be
!ls /usr/share/fonts/truetype/liberation
LiberationMono-BoldItalic.ttf LiberationSansNarrow-Bold.ttf
LiberationMono-Bold.ttf LiberationSansNarrow-Italic.ttf
LiberationMono-Italic.ttf LiberationSansNarrow-Regular.ttf
LiberationMono-Regular.ttf LiberationSans-Regular.ttf
LiberationSans-BoldItalic.ttf LiberationSerif-BoldItalic.ttf
LiberationSans-Bold.ttf LiberationSerif-Bold.ttf
LiberationSans-Italic.ttf LiberationSerif-Italic.ttf
LiberationSansNarrow-BoldItalic.ttf LiberationSerif-Regular.ttf
from PIL import ImageFont, ImageDraw, Image
#image = Image.open('test.jpg')
image = generated_images[2].copy()
draw = ImageDraw.Draw(image)
txt = sub_names[2][0]
fontsize = 1 # starting font size
W, H = image.size
# portion of image width you want text width to be
blank = Image.new('RGB',(256, 256))
#font = ImageFont.truetype("KeepCalm-Medium.ttf", fontsize)
path_font ="/usr/share/fonts/truetype/liberation/LiberationSans-Bold.ttf"
# use a truetype font
#font = ImageFont.truetype("arial.ttf", fontsize)
font = ImageFont.truetype(path_font, fontsize)
print(image.size)
print(blank.size)
while (font.getsize(txt)[0] < blank.size[0]) and (font.getsize(txt)[1] < blank.size[1]):
# iterate until the text size is just larger than the criteria
fontsize += 1
font = ImageFont.truetype(path_font, fontsize)
# optionally de-increment to be sure it is less than criteria
fontsize -= 1
font = ImageFont.truetype(path_font, fontsize)
w, h = draw.textsize(txt, font=font)
print('final font size',fontsize)
draw.text(((W-w)/2,(H-h)/2), txt, font=font, fill="white") # put the text on the image
display(image)
(256, 256)
(256, 256)
final font size 6

However wee need resize the text into two lines
from PIL import Image, ImageDraw, ImageFont
import textwrap
def draw_multiple_line_text(image, text, font, text_color, text_start_height):
'''
From unutbu on [python PIL draw multiline text on image](https://stackoverflow.com/a/7698300/395857)
'''
draw = ImageDraw.Draw(image)
image_width, image_height = image.size
y_text = text_start_height
lines = textwrap.wrap(text, width=40)
for line in lines:
line_width, line_height = font.getsize(line)
draw.text(((image_width - line_width) / 2, y_text),
line, font=font, fill=text_color)
y_text += line_height
def add_text_to_img(text1,image_input):
'''
Testing draw_multiple_line_text
'''
#image_width
#image = Image.new('RGB', (800, 600), color = (0, 0, 0))
image =image_input
fontsize = 13 # starting font size
path_font="/usr/share/fonts/truetype/liberation/LiberationSans-Bold.ttf"
font = ImageFont.truetype(path_font, fontsize)
#text1 = "I try to add text at the bottom of image and actually I've done it, but in case of my text is longer then image width it is cut from both sides, to simplify I would like text to be in multiple lines if it is longer than image width."
#text2 = "You could use textwrap.wrap to break text into a list of strings, each at most width characters long"
text_color = (255,255,0)
text_start_height = 200
draw_multiple_line_text(image, text1, font, text_color, text_start_height)
#draw_multiple_line_text(image, text2, font, text_color, 400)
#image.save('pil_text.png')
return image
#display(image)
image = generated_images[2].copy()
add_subtitle=sub_names[2][0]
result=add_text_to_img(add_subtitle,image)
display(result)
print(add_subtitle)

Because today is her birthday, she has friends help her prepare it for her birthday
text size auto adjust to an image with PIL
generated_images_sub = []
for k in range(len(generated_images)):
image = generated_images[k].copy()
text_to_add=sub_names[k][0]
result=add_text_to_img(text_to_add,image)
generated_images_sub.append(result)
display(result)
print(text_to_add, len(sub_names[k]))

Once, Laura went to the supermarket to buy the ingredients to make a cake 1

Her friends come to her house and help her to prepare the cake 1

Because today is her birthday, she has friends help her prepare it for her birthday 1

Laura's friends come and help prepare her to make her birthday cake 1
Step 5.1 - Creation of the Video
c = 0
file_names = []
for img in generated_images_sub:
f_name = 'img_'+str(c)+'.jpg'
file_names.append(f_name)
img = img.save(f_name)
c+=1
print(file_names)
clips = [ImageClip(m).set_duration(3)
for m in file_names]
concat_clip = concatenate_videoclips(clips, method="compose")
concat_clip.write_videofile("result.mp4", fps=24)
['img_0.jpg', 'img_1.jpg', 'img_2.jpg', 'img_3.jpg']
[MoviePy] >>>> Building video result.mp4
[MoviePy] Writing video result.mp4
100%|█████████▉| 288/289 [00:00<00:00, 372.99it/s]
[MoviePy] Done.
[MoviePy] >>>> Video ready: result.mp4
Step 6 - Creation of the Video
from IPython.display import HTML
from base64 import b64encode
import os
# Input video path
save_path = "result.mp4"
# Compressed video path
compressed_path = "result_compressed.mp4"
os.system(f"ffmpeg -i {save_path} -vcodec libx264 {compressed_path}")
# Show video
mp4 = open(compressed_path,'rb').read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
HTML("""
<video width=400 controls>
<source src="%s" type="video/mp4">
</video>
""" % data_url)
Now is time to add sound to our video that we have been created,.. we will use the gTTs.
gTTS (Google Text-to-Speech), a Python library and CLI tool to interface with Google Translate text-to-speech API.
Step 7 - Creation of audio
# Import the required module for text
# to speech conversion
from gtts import gTTS
from IPython.display import Audio
from IPython.display import display
# The text that you want to convert to audio
mytext = sub_names[1][0]
# Language in which you want to convert
language = 'en'
# Passing the text and language to the engine,
# here we have marked slow=False. Which tells
# the module that the converted audio should
# have a high speed
myobj = gTTS(text=mytext, lang=language, slow=False)
# Saving the converted audio in a mp3 file named
sound_file="audio.mp3"
myobj.save(sound_file)
from mutagen.mp3 import MP3
audio = MP3("audio.mp3")
print(audio.info.length)
4.584
wn = Audio(sound_file, autoplay=True) ##
display(wn)##
from mutagen.mp3 import MP3
c = 0
mp3_names = []
mp3_lengths = []
for k in range(len(generated_images)):
text_to_add=sub_names[k][0]
print(text_to_add)
f_name = 'audio_'+str(c)+'.mp3'
mp3_names.append(f_name)
# The text that you want to convert to audio
mytext = text_to_add
# Language in which you want to convert
language = 'en'
# Passing the text and language to the engine,
# here we have marked slow=False. Which tells
# the module that the converted audio should
# have a high speed
myobj = gTTS(text=mytext, lang=language, slow=False)
# Saving the converted audio in a mp3 file named
sound_file=f_name
myobj.save(sound_file)
audio = MP3(sound_file)
duration=audio.info.length
mp3_lengths.append(duration)
print(audio.info.length)
c+=1
print(mp3_names)
print(mp3_lengths)
Once, Laura went to the supermarket to buy the ingredients to make a cake
5.856
Her friends come to her house and help her to prepare the cake
4.584
Because today is her birthday, she has friends help her prepare it for her birthday
6.12
Laura's friends come and help prepare her to make her birthday cake
4.968
['audio_0.mp3', 'audio_1.mp3', 'audio_2.mp3', 'audio_3.mp3']
[5.856, 4.584, 6.12, 4.968]
wn = Audio(mp3_names[0], autoplay=True) ##
display(wn)##
Step 8 - Merge audio files
from pydub import AudioSegment
from os import getcwd
import glob
cwd = (getcwd()).replace(chr(92), '/')
#export_path = f'{cwd}/result.mp3'
export_path ='result.mp3'
MP3_FILES = glob.glob(pathname=f'{cwd}/*.mp3', recursive=True)
mp3_names
['audio_0.mp3', 'audio_1.mp3', 'audio_2.mp3', 'audio_3.mp3']
silence = AudioSegment.silent(duration=500)
full_audio = AudioSegment.empty() # this will accumulate the entire mp3 audios
for n, mp3_file in enumerate(mp3_names):
mp3_file = mp3_file.replace(chr(92), '/')
print(n, mp3_file)
# Load the current mp3 into `audio_segment`
audio_segment = AudioSegment.from_mp3(mp3_file)
# Just accumulate the new `audio_segment` + `silence`
full_audio += audio_segment + silence
print('Merging ', n)
# The loop will exit once all files in the list have been used
# Then export
full_audio.export(export_path, format='mp3')
print('\ndone!')
0 audio_0.mp3
Merging 0
1 audio_1.mp3
Merging 1
2 audio_2.mp3
Merging 2
3 audio_3.mp3
Merging 3
done!
wn = Audio(export_path, autoplay=True) ##
display(wn)##
Step 9 - Creation of the video with adjusted times of the sound
c = 0
file_names = []
for img in generated_images_sub:
f_name = 'img_'+str(c)+'.jpg'
file_names.append(f_name)
img = img.save(f_name)
c+=1
print(file_names)
clips=[]
d=0
for m in file_names:
duration=mp3_lengths[d]
print(d,duration)
clips.append(ImageClip(m).set_duration(duration+0.5))
d+=1
concat_clip = concatenate_videoclips(clips, method="compose")
concat_clip.write_videofile("result_new.mp4", fps=24)
['img_0.jpg', 'img_1.jpg', 'img_2.jpg', 'img_3.jpg']
0 5.856
1 4.584
2 6.12
3 4.968
[MoviePy] >>>> Building video result_new.mp4
[MoviePy] Writing video result_new.mp4
100%|██████████| 565/565 [00:01<00:00, 527.73it/s]
[MoviePy] Done.
[MoviePy] >>>> Video ready: result_new.mp4
from IPython.display import HTML
from base64 import b64encode
import os
# Input video path
save_path = "result_new.mp4"
# Compressed video path
compressed_path = "result_compressed_new.mp4"
os.system(f"ffmpeg -i {save_path} -vcodec libx264 {compressed_path}")
# Show video
mp4 = open(compressed_path,'rb').read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
HTML("""
<video width=400 controls>
<source src="%s" type="video/mp4">
</video>
""" % data_url)
Step 10 - Merge Video + Audio
movie_name = 'result_new.mp4'
export_path='result.mp3'
movie_final= 'result_final.mp4'
# Import everything needed to edit video clips
from moviepy.editor import *
# loading video dsa gfg intro video
clip = VideoFileClip(movie_name)
# getting duration of the video
duration = clip.duration
# printing duration
print("Duration : " + str(duration))
# showing final clip
clip.ipython_display()
Duration : 23.54
100%|██████████| 565/565 [00:00<00:00, 863.88it/s]
def combine_audio(vidname, audname, outname, fps=60):
import moviepy.editor as mpe
my_clip = mpe.VideoFileClip(vidname)
audio_background = mpe.AudioFileClip(audname)
final_clip = my_clip.set_audio(audio_background)
final_clip.write_videofile(outname,fps=fps)
combine_audio(movie_name, export_path, movie_final) # i create a new file
[MoviePy] >>>> Building video result_final.mp4
[MoviePy] Writing audio in result_finalTEMP_MPY_wvf_snd.mp3
100%|██████████| 521/521 [00:00<00:00, 1166.15it/s]
[MoviePy] Done.
[MoviePy] Writing video result_final.mp4
100%|██████████| 1413/1413 [00:02<00:00, 606.32it/s]
[MoviePy] Done.
[MoviePy] >>>> Video ready: result_final.mp4
In ordering to reproduce mp4 on google Collab we use the following codes
from IPython.display import HTML
from base64 import b64encode
import os
def compress_video(input_video):
# Input video path
save_path = input_video
# Compressed video path
compressed_path = save_path .replace(".mp4", "_compressed.mp4")
print(compressed_path)
os.system(f"ffmpeg -i {save_path} -vcodec libx264 {compressed_path}")
# Show video
mp4 = open(compressed_path,'rb').read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
HTML("""
<video width=400 controls>
<source src="%s" type="video/mp4">
</video>
""" % data_url)
compress_video("result_final.mp4")
result_final_compressed.mp4
and finally we show the video
# Show video
mp4 = open('result_final.mp4','rb').read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
HTML("""
<video width=400 controls>
<source src="%s" type="video/mp4">
</video>
""" % data_url)
Great!, let us summarize all the previous steps into a single code here . You can play with this code in Google Collab by download the single code here or the full notebook code here.
Congratulations! You have finished this project.
Leave a comment