How to Fine-tune Large Language Models
Hello everyone, today we are going to get started with Fine-tuning Large Language Models (LLMs) locally and can be used in the cloud.
Introduction
Currently, there are two common methods to customize our LLMs.
Prompting
- Generic, side project prototypes
- Pros: No data required to get started, smaller upfront cost, no technical knowledge needed, connect data through retrieval (RAG)
- Cons: Much less data fits, forgets data, hallucinations, RAG misses or gets incorrect data
Fine-tuning
- Domain-specific, enterprise, production usage, privacy
- Pros: Nearly unlimited data fits, learn new information, correct incorrect information, less cost if smaller model, use RAG too, reduce hallucinations
- Cons: Need high quality data, upfront compute cost, needs technical knowledge for the data
Fine-tuning usually refers to training further. It can be done with self-supervised unlabeled data or labeled data that you curated. It requires much less data compared to fine-tuning for generative tasks, which is not well defined. Fine-tuning updates the entire model, not just a part of it.
Environment Setup
Local Setup
First, we are going to install our environment with Python 3.10.11. After you have installed Python in your working directory, you can create your virtual environment using the following command:
python -m venv .venv
You’ll notice a new directory in your current working directory with the same name as your virtual environment. Then, activate the virtual environment:
.venv\Scripts\activate.bat
It is convenient to have the latest pip installed:
python -m pip install --upgrade pip
Next, we install Jupyter Notebook, as you can also use it:
pip install ipykernel notebook
Step 3: Setup libraries
Once we have our running environment, we install our kernel:
python -m ipykernel install --user --name LLM --display-name "Python (LLM)"
Then, we will require PyTorch, HuggingFace, and Llama libraries:
pip install datasets==2.14.6 transformers==4.31.0 torch torchvision lamini==2.0.1 ipywidgets python-dotenv sacrebleu sqlitedict omegaconf pycountry rouge_score peft pytablewriter
If we are on Windows, we can use the following command:
pip install transformers[torch]
If we are on Linux, we can use the following command:
pip install accelerate -U
Why Fine-tune All the Parameters?
- LORA (Low Rank Adaptation of LLMs)
- Fewer trainable parameters for GPT3 (1000x less)
- Less GPU memory usage
- Slightly lower accuracy compared to fine-tuning
- Same inference latency
- Train new weights in some layers and freeze main weights
- New weights are rank decomposition matrices of original weights
- Merge with main weights during inference
Fine-tune Large Language Models
We are going to fine tune a simple Large Model to create a custom doctor chatbot assitant. This notebook collect the three passages needed
- Data Preparation
- Traning
- Evaluation
1. Data Preparation for Fine-Tuning Large Language Models
Large language models (LLMs) are trained on massive amounts of text data to understand and generate human-like language. Fine-tuning takes a pre-trained LLM and tailors it for a specific task using a smaller dataset relevant to that task. This section dives into data preparation, a crucial step for successful fine-tuning.
First-time Fine-tuning
To start fine-tuning, we need to identify the tasks by bottom-up engineering of a large LLM. Find tasks that the LLM is doing okay at. Pick one task and gather around 1500 inputs and outputs for that task. Then, fine-tune a small LLM on this data.
import jsonlines
import itertools
import pandas as pd
from pprint import pprint
import datasets
from datasets import load_dataset
import re
dataset = load_dataset("ruslanmv/ai-medical-chatbot")
train_data = dataset["train"]
# For this demo, let's choose the first 1500 dialogues
df = pd.DataFrame(train_data[:1500])
df = df[["Description", "Doctor"]].rename(columns={"Description": "question", "Doctor": "answer"})
# Clean the question and answer columns
df['question'] = df['question'].apply(lambda x: re.sub(r'\s+', ' ', x.strip()))
df['answer'] = df['answer'].apply(lambda x: re.sub(r'\s+', ' ', x.strip()))
# Assuming your DataFrame is named 'df' and the column is named 'df' and the column is named 'question'
df['question'] = df['question'].str.lstrip('Q. ')
df.head()
| question | answer | |
|---|---|---|
| 0 | What does abutment of the nerve root mean? | Hi. I have gone through your query with dilige... |
| 1 | What should I do to reduce my weight gained du... | Hi. You have really done well with the hypothy... |
| 2 | I have started to get lots of acne on my face,... | Hi there Acne has multifactorial etiology. Onl... |
| 3 | Why do I have uncomfortable feeling between th... | Hello. The popping and discomfort what you fel... |
| 4 | My symptoms after intercourse threatns me even... | Hello. The HIV test uses a finger prick blood ... |
What is Instruction Tuning?
Instruction tuning teaches the model to behave more like a chatbot, providing a better user interface for model generation. For example, it turned GPT-3 into ChatGPT, increasing AI adoption from thousands of researchers to millions of people. You can use instruction-following datasets, such as FAWS, customer support conversations, slack messages, etc. If you don’t have QA data, you can convert it to QA by using a prompt template or another LLM. The standard cycle of fine-tuning consists of Data Preparation, Training, and Evaluation.
3. Formatting Your Fine-tuning Data
There are various ways to format your data for fine-tuning. Here, the code demonstrates extracting questions and answers from a JSONL file and combining them into a single text format.
### Various ways of formatting your data
examples = df.to_dict()
text = examples["question"][0] + examples["answer"][0]
text
'What does abutment of the nerve root mean?Hi. I have gone through your query with diligence and would like you to know that I am here to help you. For further information consult a neurologist online -->'
if "question" in examples and "answer" in examples:
text = examples["question"][0] + examples["answer"][0]
elif "instruction" in examples and "response" in examples:
text = examples["instruction"][0] + examples["response"][0]
elif "input" in examples and "output" in examples:
text = examples["input"][0] + examples["output"][0]
else:
text = examples["text"][0]
4. Creating Prompts
Prompts provide context and guide the LLM towards the desired task. The code showcases creating prompts for question-answering tasks with placeholders for questions and answers.
prompt_template_qa = """### Question:
{question}
### Answer:
{answer}"""
question = examples["question"][0]
answer = examples["answer"][0]
text_with_prompt_template = prompt_template_qa.format(question=question, answer=answer)
text_with_prompt_template
'### Question:\nWhat does abutment of the nerve root mean?\n### Answer:\nHi. I have gone through your query with diligence and would like you to know that I am here to help you. For further information consult a neurologist online -->'
prompt_template_q = """{question}"""
5. Saving Your Data
The code demonstrates saving the processed data with questions and answers in JSONL format for compatibility with various tools.
num_examples = len(examples["question"])
finetuning_dataset_text_only = []
finetuning_dataset_question_answer = []
for i in range(num_examples):
question = examples["question"][i]
answer = examples["answer"][i]
text_with_prompt_template_qa = prompt_template_qa.format(question=question, answer=answer)
finetuning_dataset_text_only.append({"text": text_with_prompt_template_qa})
text_with_prompt_template_q = prompt_template_q.format(question=question)
finetuning_dataset_question_answer.append({"question": text_with_prompt_template_q, "answer": answer})
pprint(finetuning_dataset_text_only[0])
{'text': '### Question:\n'
'What does abutment of the nerve root mean?\n'
'### Answer:\n'
'Hi. I have gone through your query with diligence and would like you '
'to know that I am here to help you. For further information consult '
'a neurologist online -->'}
pprint(finetuning_dataset_question_answer[0])
{'answer': 'Hi. I have gone through your query with diligence and would like '
'you to know that I am here to help you. For further information '
'consult a neurologist online -->',
'question': '### Question:\n'
'What does abutment of the nerve root mean?\n'
'### Answer:'}
import os
# Get the current directory
current_directory = os.getcwd()
# Join the folder path
folder_path = os.path.join(current_directory, "content")
# Create the folder if it doesn't exist
if not os.path.exists(folder_path):
os.makedirs(folder_path)
# Create the dataset path
dataset_name = "ai-medical-chatbot_processed.jsonl"
dataset_path = os.path.join(folder_path, dataset_name)
### Common ways of storing your data
with jsonlines.open(dataset_path, 'w') as writer:
writer.write_all(finetuning_dataset_question_answer)
finetuning_dataset_name = "ruslanmv/ai-medical-chatbot"
finetuning_dataset = load_dataset(finetuning_dataset_name)
print(finetuning_dataset)
DatasetDict({
train: Dataset({
features: ['Description', 'Patient', 'Doctor'],
num_rows: 256916
})
})
Training
Large language models (LLMs) are powerhouses of general language understanding, trained on massive text datasets. Fine-tuning takes a pre-trained LLM and tailors it for a specific task using a smaller, relevant dataset. This section delves into the training aspect of fine-tuning.
Training an LLM is similar to training a neural network. The process involves:
- Adding the training data
- Calculating loss
- Backpropagating through the model
- Updating weights
- Hyperparameters (Learning Rate, Learning Rate Scheduler)
Training Method
- Load the Base Model: First we load the pre-trained LLM (
EleutherAI/pythia-70min this case). - Define Training Configuration: This sets up details like the pre-trained model name, maximum sequence length, and dataset path.
- Tokenize and Split Data: The data is converted into numerical tokens the model understands and split into training and testing sets.
- Define Training Arguments: These hyperparameters control the training process, including learning rate, number of epochs, and batch size.
- Print Model Details: This displays information about the model’s architecture and memory/compute requirements.
- Initialize Trainer Object: The
Trainerobject fromtransformerssimplifies the training process. - Train the Model: The
trainer.train()method carries out the fine-tuning process on the specified data. - Save the Fine-tuned Model: The trained model is saved for later use.
Note: This is a simplified example.
import datasets
import tempfile
import logging
import random
import config
import os
import yaml
import time
import torch
import transformers
import pandas as pd
import jsonlines
from utilities import *
from transformers import AutoTokenizer
from transformers import AutoModelForCausalLM
from transformers import TrainingArguments
from transformers import AutoModelForCausalLM
from llama import BasicModelRunner
logger = logging.getLogger(__name__)
global_config = None
Load the dataset
# Get the current directory
current_directory = os.getcwd()
# Join the folder path
folder_path = os.path.join(current_directory, "content")
dataset_name = "ai-medical-chatbot_processed.jsonl"
dataset_path = os.path.join(folder_path, dataset_name)
#dataset_path = f"/content/{dataset_name}"
use_hf = False
#dataset_path = "ruslanmv/ai-medical-chatbot"
#use_hf = True
Set up the model, training config, and tokenizer
Fine-tuning involves training the pre-trained LLM on your task-specific dataset. This helps the model adjust its internal parameters and representations to excel at your chosen task. Here’s the Python code showcasing the training process:
model_name = "EleutherAI/pythia-70m"
training_config = {
"model": {
"pretrained_name": model_name,
"max_length" : 2048
},
"datasets": {
"use_hf": use_hf,
"path": dataset_path
},
"verbose": True
}
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
train_dataset, test_dataset = tokenize_and_split_data(training_config, tokenizer)
print(train_dataset)
print(test_dataset)
Load the base model
base_model = AutoModelForCausalLM.from_pretrained(model_name)
device_count = torch.cuda.device_count()
if device_count > 0:
logger.debug("Select GPU device")
device = torch.device("cuda")
else:
logger.debug("Select CPU device")
device = torch.device("cpu")
base_model.to(device)
Define function to carry out inference
def inference_new(text, model, tokenizer, max_input_tokens=1000, max_output_tokens=100):
# Tokenize
input_ids = tokenizer.encode(
text,
return_tensors="pt",
truncation=True,
max_length=max_input_tokens
)
# Generate
device = model.device
attention_mask = torch.ones_like(input_ids) # Create mask with all 1s
# Fix: Mask all padding tokens, including the first element
attention_mask[input_ids == tokenizer.pad_token_id] = 0
generated_tokens_with_prompt = model.generate(
input_ids.to(device),
max_length=max_output_tokens,
attention_mask=attention_mask,
pad_token_id=tokenizer.eos_token_id # Set pad token
)
# Decode
generated_text_with_prompt = tokenizer.batch_decode(generated_tokens_with_prompt, skip_special_tokens=True)
# Strip the prompt
generated_text_answer = generated_text_with_prompt[0][len(text):]
return generated_text_answer
Try the base model
test_text = test_dataset[0]['question']
print("Question input (test):", test_text)
print(f"Correct answer from ai-medical-chatbot: {test_dataset[0]['answer']}")
print("Model's answer: ")
print(inference_new(test_text, base_model, tokenizer))
Question input (test): ### Question:
Will Kalarchikai cure multiple ovarian cysts in PCOD?
### Answer:
Correct answer from ai-medical-chatbot: Hello. I just read your query. See Kalarachi Kai choornam is helpful in amenorrhea. As far as small cysts are concerned they are unmatured eggs which failed to induce menstrual cycle previously, as a result, they got collected in the ovary and they will remain in the ovary. Now, you have got your periods you can start trying for conception. But I advise you to do it under the supervision of a nearby gynecologist because egg size is important while conception and that you can know by ovulation study. Ovulation study is performed under the supervision of a gynecologist. For gall stones, surgical intervention is required generally. Medicine is not of much help.
Model's answer:
The answer is "Yes" and "No"
The answer is "Yes" and "No"
The answer is "Yes" and "No"
The answer is "Yes" and "No"
The answer is "Yes" and "No"
The answer is "Yes" and "No"
The answer is "Yes
Setup training
max_steps = 3
trained_model_name = f"ai_medical_{max_steps}_steps"
output_dir = trained_model_name
training_args = TrainingArguments(
# Learning rate
learning_rate=1.0e-5,
# Number of training epochs
num_train_epochs=10,
# Max steps to train for (each step is a batch of data)
# Overrides num_train_epochs, if not -1
max_steps=max_steps,
# Batch size for training
per_device_train_batch_size=1,
# Directory to save model checkpoints
output_dir=output_dir,
# Other arguments
overwrite_output_dir=False, # Overwrite the content of the output directory
disable_tqdm=False, # Disable progress bars
eval_steps=120, # Number of update steps between two evaluations
save_steps=120, # After # steps model is saved
warmup_steps=1, # Number of warmup steps for learning rate scheduler
per_device_eval_batch_size=1, # Batch size for evaluation
evaluation_strategy="steps",
logging_strategy="steps",
logging_steps=1,
optim="adafactor",
gradient_accumulation_steps = 4,
gradient_checkpointing=False,
# Parameters for early stopping
load_best_model_at_end=True,
save_total_limit=1,
metric_for_best_model="eval_loss",
greater_is_better=False
)
model_flops = (
base_model.floating_point_ops(
{
"input_ids": torch.zeros(
(1, training_config["model"]["max_length"])
)
}
)
* training_args.gradient_accumulation_steps
)
print(base_model)
print("Memory footprint", base_model.get_memory_footprint() / 1e9, "GB")
print("Flops", model_flops / 1e9, "GFLOPs")
GPTNeoXForCausalLM(
(gpt_neox): GPTNeoXModel(
(embed_in): Embedding(50304, 512)
(emb_dropout): Dropout(p=0.0, inplace=False)
(layers): ModuleList(
(0-5): 6 x GPTNeoXLayer(
(input_layernorm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(post_attention_layernorm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(post_attention_dropout): Dropout(p=0.0, inplace=False)
(post_mlp_dropout): Dropout(p=0.0, inplace=False)
(attention): GPTNeoXAttention(
(rotary_emb): GPTNeoXRotaryEmbedding()
(query_key_value): Linear(in_features=512, out_features=1536, bias=True)
(dense): Linear(in_features=512, out_features=512, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(mlp): GPTNeoXMLP(
(dense_h_to_4h): Linear(in_features=512, out_features=2048, bias=True)
(dense_4h_to_h): Linear(in_features=2048, out_features=512, bias=True)
(act): GELUActivation()
)
)
)
(final_layer_norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(embed_out): Linear(in_features=512, out_features=50304, bias=False)
)
Memory footprint 0.30687256 GB
Flops 2195.667812352 GFLOPs
trainer = Trainer(
model=base_model,
model_flops=model_flops,
total_steps=max_steps,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
)
Train a few steps
class MetricsCollector(TrainerCallback):
"""
Callback to collect metrics during training.
This callback stores all the logs it receives during training in a list
called `metrics`. This list can then be used to plot training loss, learning rate,
and other metrics.
"""
def __init__(self):
super().__init__()
self.metrics = []
def on_log(self, args, state, control, logs=None, **kwargs):
"""
Stores the logs received during training.
This method is called whenever the trainer logs information. It simply
appends the entire `logs` dictionary to the `metrics` list.
Args:
args: Arguments passed to the trainer.
state: State of the trainer.
control: Control object for the trainer.
logs: Dictionary containing the logged metrics. (optional)
**kwargs: Additional keyword arguments.
"""
#print("Available logs:", logs) # Print the logs dictionary to see its keys for debugging
self.metrics.append(logs)
import matplotlib.pyplot as plt
def plot_loss(metrics):
"""
Plots the training loss from the collected metrics.
This function iterates through the `metrics` list and extracts the `loss` value
from each dictionary. It then filters out any entries where `loss` is missing
and plots the remaining values.
Args:
metrics: List of dictionaries containing training logs.
"""
losses = [m.get('loss', None) for m in metrics] # Use .get() to handle missing keys
non_none_losses = [loss for loss in losses if loss is not None]
plt.plot(non_none_losses)
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.title('Training Loss')
plt.show()
def plot_learning_rate(metrics):
"""
Plots the learning rate from the collected metrics.
This function follows the same logic as `plot_loss` to extract and plot the
learning rate values from the `metrics` list, handling missing entries.
Args:
metrics: List of dictionaries containing training logs.
"""
learning_rates = [m.get('learning_rate', None) for m in metrics]
non_none_learning_rates = [lr for lr in learning_rates if lr is not None]
plt.plot(non_none_learning_rates)
plt.xlabel('Iteration')
plt.ylabel('Learning Rate')
plt.title('Learning Rate')
plt.show()
metrics_collector = MetricsCollector()
trainer.add_callback(metrics_collector)
training_output = trainer.train()
plot_loss(metrics_collector.metrics)
plot_learning_rate(metrics_collector.metrics)
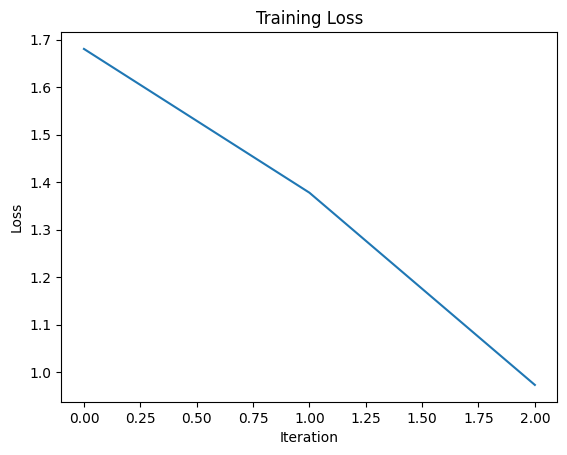
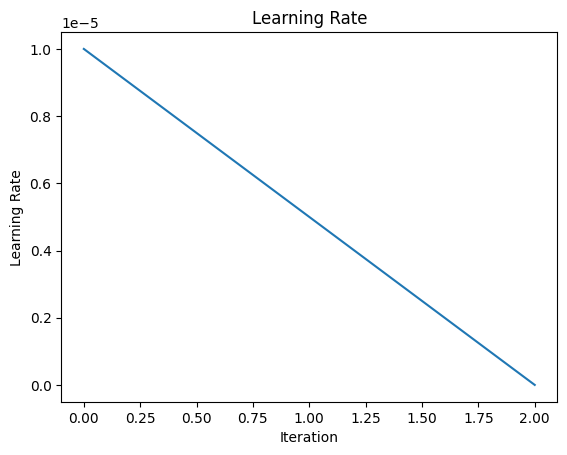
Loss vs Iteration: Ideal Shape and Expectations
Desired Shape:
The ideal loss curve for training depicts a downward trend, indicating the model’s improvement in minimizing the loss function over iterations. This signifies the model is learning the patterns in the data and making better predictions.
Expected Behavior:
- Initial Rapid Decrease: Early iterations often show a steep decline as the model grasps basic patterns.
- Gradual Descent: As the model encounters more complex relationships, the decrease becomes slower and steadier.
- Plateau (Optional): In some cases, the loss may reach a plateau, indicating the model has achieved its optimal performance with the current hyperparameters.
Warning Signs:
- Stagnation: If the loss remains flat from the beginning, the model might not be learning effectively. This could be due to factors like insufficient data, inappropriate model architecture, or high learning rate.
- Oscillation: Erratic fluctuations can indicate the model is overfitting to the training data. Techniques like regularization or reducing learning rate can help.
Learning Rate vs Iteration: Ideal Behavior and Expectations
Desired Behavior:
The learning rate can be adjusted throughout training using a learning rate schedule. Here are some common approaches:
- Constant Learning Rate: A simple approach, but may not be optimal for all scenarios.
- Step Decay: Learning rate is reduced by a fixed amount at specific intervals (epochs).
- Exponential Decay: Learning rate decreases exponentially over time.
- Warm Restarts: Learning rate is periodically increased to a higher value, allowing the model to escape local minima.
General Expectations:
- The learning rate should be high enough for the model to learn effectively initially.
- A gradual decrease in learning rate helps the model converge to a minimum more precisely.
- Choosing the right learning rate schedule depends on the specific problem and dataset.
Warning Signs:
- Too High Learning Rate: Can lead to large oscillations or divergence in the loss curve.
- Too Low Learning Rate: Slows down training significantly and may prevent the model from reaching optimal performance.
By monitoring both loss and learning rate curves, you can gain valuable insights into the training process and adjust hyperparameters for better results.
Additional Tips:
- Use validation loss to track generalization performance and avoid overfitting.
- Experiment with different learning rate schedules to find the best fit for your problem.
- Consider techniques like early stopping to prevent overfitting when the validation loss starts to increase.
Save model locally
save_dir = f'{output_dir}/final'
trainer.save_model(save_dir)
print("Saved model to:", save_dir)
Saved model to: ai_medical_3_steps/final
finetuned_slightly_model = AutoModelForCausalLM.from_pretrained(save_dir, local_files_only=True)
finetuned_slightly_model.to(device)
Run slightly trained model
test_question = test_dataset[0]['question']
print("Question input (test):", test_question)
print("Finetuned slightly model's answer: ")
print(inference_new(test_question, finetuned_slightly_model, tokenizer))
Question input (test): ### Question:
Will Kalarchikai cure multiple ovarian cysts in PCOD?
### Answer:
Finetuned slightly model's answer:
Hi. Kalarikai is a good medicine for ovarian cysts. It is a good medicine for ovarian cysts. But, it is not a good medicine for ovarian cysts. But, it is not a good medicine for ovarian cysts. But, it is not a good medicine for ovarian cysts. But, it is not a good medicine for ovarian cysts. But, it is not a good medicine
test_answer = test_dataset[0]['answer']
print("Target answer output (test):", test_answer)
Target answer output (test): Hello. I just read your query. See Kalarachi Kai choornam is helpful in amenorrhea. As far as small cysts are concerned they are unmatured eggs which failed to induce menstrual cycle previously, as a result, they got collected in the ovary and they will remain in the ovary. Now, you have got your periods you can start trying for conception. But I advise you to do it under the supervision of a nearby gynecologist because egg size is important while conception and that you can know by ovulation study. Ovulation study is performed under the supervision of a gynecologist. For gall stones, surgical intervention is required generally. Medicine is not of much help.
Explore moderation using small model
First, try the non-finetuned base model:
base_tokenizer = AutoTokenizer.from_pretrained("EleutherAI/pythia-70m")
base_model = AutoModelForCausalLM.from_pretrained("EleutherAI/pythia-70m")
print(inference_new("What do you think of Mars?", base_model, base_tokenizer))
I think I’m going to go to the next page.
I think I’m going to go to the next page.
I think I’m going to go to the next page.
I think I’m going to go to the next page.
I think I’m going to go to the next page.
I think I’m going to go to the next page.
I
Now try moderation with finetuned small model
#print(inference_new("What do you think of Mars?", finetuned_longer_model, tokenizer))
print(inference_new("What do you think of Mars?", finetuned_slightly_model, tokenizer))
I’m not sure if you are a good enough person to be a good enough person to be a good enough person to be a good enough person to be a good enough person to be a good enough person to be a good enough person to be a good enough person to be a good enough person to be a good enough person to be a good enough person to be a good enough person to be a good enough person to be a good enough person to be
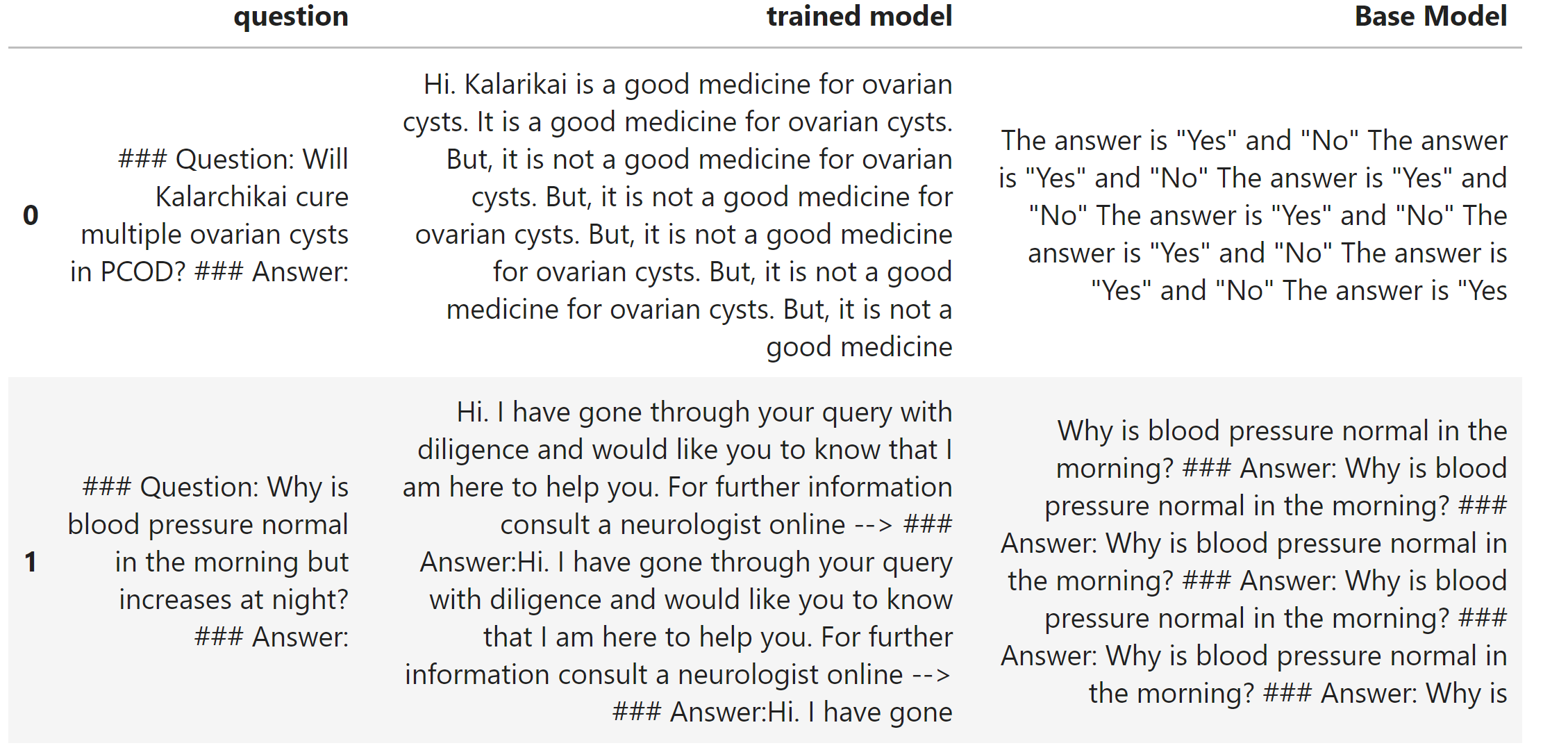
## Comparison
import pandas as pd
# Assuming test_dataset is already loaded
test_questions = [test_dataset[i]['question'] for i in range(len(test_dataset))]
len(test_questions[:10])
# Load the base model and tokenizer
base_tokenizer = AutoTokenizer.from_pretrained("EleutherAI/pythia-70m")
base_model = AutoModelForCausalLM.from_pretrained("EleutherAI/pythia-70m")
# Function to get the model's answer
def get_answer(question, model, tokenizer):
return inference_new(question, model, tokenizer)
from tqdm import tqdm # Import tqdm for progress bar
# Iterate through the test questions and generate answers using both models
results = []
for question in tqdm(test_questions[:10]): #test_questions:
finetuned_answer = get_answer(question, finetuned_slightly_model, tokenizer)
base_answer = get_answer(question, base_model, base_tokenizer)
result = {'question': question, 'trained model': finetuned_answer, 'Base Model': base_answer}
results.append(result)
# Convert the list of dictionaries to a pandas DataFrame
df = pd.DataFrame.from_dict(results)
# Style the DataFrame for better readability
style_df = df.style.set_properties(**{'text-align': 'left'})
style_df = style_df.set_properties(**{"vertical-align": "text-top"})
# Display the DataFrame
style_df
Training Infrastructure
For real training, we need to consider the amount of parameters required to train. Here is a table showing the AWS Instance, GPU, GPU Memory, Max Inference size (#params), and Max training size (#tokens):
| AWS Instance | GPU | GPU Memory | Max Inference size (#params) | Max training size (#tokens) |
| AWS Instance | GPU | GPU Memory | Max Inference size (#params) | Max training size (#tokens) |
|---|---|---|---|---|
| p3.2xlarge | 1 V100 | 16GB | 7B | 1B |
| p3.8xlarge | 4 V100 | 64GB | 7B | 1B |
| p3.16xlarge | 8 V100 | 128GB | 7B | 1B |
| p3dn.24xlarge | 8 V100 | 256GB | 14B | 2B |
| p4d.24xlarge | 8 A100 | 320GB | 18B | 2.5B |
| p4de.24xlarge | 8 A100 | 640GB | 32B | 5B |
The instruction tuned, teaches the model to behave more like a chatbot, better user interface for model generation. For example, turned GPT-3 into ChatGPT, increase AI adoption, from thousandss of reseachers to millions of people.
Evaluation
There are several ways to evaluate the results of training, but it requires having good test data that is of high quality, accurate, and generalized, not seen in the training data. Currently, there is an Elo comparison. LLM benchmarks like ARC (a set of grade-school questions) and HellaSwag - MMLU (multitask metrics covering elementary math, US history, computer science, law, and more) can be used. TrufulQA is another benchmark.
Evaluation is essential for assessing the effectiveness of your fine-tuned LLM. Here’s a breakdown of key aspects:
Metrics:
- Exact Match (EM): Compares predicted answers to ground-truth answers on a word-by-word basis, indicating perfect accuracy.
- F1-Score: A harmonic mean of precision (proportion of correct answers) and recall (proportion of ground-truth answers retrieved).
- BLEU Score (for text generation): Measures the similarity between generated text and reference text, considering n-gram matches.
Evaluation Strategies:
- Held-out Test Set: Split your dataset into training, validation, and testing sets. Evaluate on the unseen testing set to gauge generalizability.
- Cross-validation: Divide your data into folds and train on k-1 folds, evaluating on the remaining fold. Repeat for all folds for a more robust estimate.
Beyond the Basics:
- Error Analysis: Identify patterns in incorrect predictions to refine your fine-tuning process or data collection.
- Human Evaluation: Supplement quantitative metrics with human judgment for tasks where subjectivity or nuance is important.
- Bias Detection and Mitigation: Be vigilant of potential biases inherited from training data and fine-tuning settings. Implement strategies like debiasing techniques to address them.
By following these guidelines and continually evaluating your fine-tuned LLMs, you can ensure they excel at the specific tasks you intend them for, ultimately enhancing the value they deliver in your applications.
Error Analysis
Error analysis involves understanding the behavior of the base model before fine-tuning. Categorize errors and iterate on data to fix these problems in the data space.
PEFT Parameter-Efficient Finetuning
PEFT stands for Parameter-Efficient Fine-tuning. It refers to the process of fine-tuning LLMs with fewer trainable parameters, resulting in reduced GPU memory usage and slightly lower accuracy compared to fine-tuning all parameters. PEFT involves training new weights in some layers and freezing main weights. It uses low-rank decomposition matrices of the original weights to make changes. During inference, it merges the new weights with the main weights.
LORA Low Rank Adaptiaion of LLMs
LORA is another approach for adapting LLMs to new, different tasks. It also involves training new weights in some layers and freezing main weights. LORA uses LoRa for adaptation to new tasks.
Conclusion
In this blog post, we have discussed how to fine-tune large language models. We have covered the different methods of customization, environment setup, instruction tuning, training, evaluation, error analysis, training infrastructure, PEFT, LORA, and the importance of fine-tuning all parameters. Fine-tuning large language models can greatly benefit enterprises in improving their language models and achieving better results in various tasks.
Leave a comment