
How to use Generative AI with IBM WatsonX
Hello everyone, today we are going to use IBM watsonx.
On July 11th IBM announced IBM watsonx an enterprise-ready AI and data platform where we can train, validate, tune, and deploy generative AI, foundation models, and machine learning capabilities with ease and build AI applications in a fraction of the time with a fraction of the data.
In this blog post we are going to explain how to use Generative AI to summarize, classify, extract, generate and answering questions from a text.

Introduction
AI refers to the ability of computer systems to attempt to mimic the problem solving and decision making capabilities of the human mind. The artificial intelligence has been used in many areas like
- Computer vision
- Data science
- Natural language processing
- Robotics
and many others.
AI models have evolved significantly in the past decade.
- Advanced analytics - Step by step logic and instructions coded by human developers. Very Deterministic.- eg. anomaly detection etc.
- Machine learning - Human crafted features with supervised learning to analyze data for specific task. eg. prediction price, optimization etc.
- Deep learning - Unsupervised learning where AI is fed outcomes and data to create rules and algorithms. eg. Image recognition, autonomous driving etc.
- Foundation models- Unsupervised AI that ingest massive amount of data, to then generate net new human-like text, art, images, video, etc. eg. DALL-e ChatGPT, BERT, T5, LaMDA etc.
When to use Traditional AI Capabilities
- Predictive - Structured data analysis, predictions, forecasting, etc.
- Directed Conversational AI - Deterministic dialog flows for API driven conversational AI.
- Computer Vision AI - Machine Vision for object and anomaly detection.
- Process Automation - Robotic Process Automation, Process reengineering and optimization.
When to use Generative AI capabilities
- Summarization eg. documents such as user manuals, asset notes, financial reports etc.
- Conversation Search, eg. SOPs troubleshooting instructions etc.
- Content creation eg. personas, user stories, synthetic data, generating images, personalized UI, marketing copu, email/ social responses etc.
- Code creation. eg. Code co-pilot, code conversion, create technical documentation, test cases etc.
What you can do with Generative AI
- Question answering- Model responds to question in natural language.
- Generation - Model generate content in natural language.
- Extraction- Model extract entities facts and info, from text.
- Summarize - Model creates summaries of natural language.
- Classification- Models classifies text .eg. sentiment, group, projects etc.
Generative AI
Class of Machine Learning techniques whose purpose is to generate content or data of many kinds such as audio, code, images, text, simulaitons, 3D objects, and videos.
The foundation models
An AI model that can be adapted to a wide range of downstream tasks. Foundation models are typically large-scale (eg. billions of parameters) generative models trained on unlabeled data using self-supervision.
In this blog post, we are going to test watsonx.ai
Step 1 Creation of account
First we need to create our IBM cloud account here
https://www.ibm.com/products/watsonx-ai
You can start you free trial
Step 2. Open Prompt Lab
After you are in, you can open a Prompt Lab

With the Foundation Model Libraries, you can have easy access to IBM propertary and open source Foundation models.
The Prompt Lab you ca experiment with zero/ few-shot learning for enterprises tasks , and with Tunning studio you tailor pre-trained Foundation models for complex downstream tasks on enterprise data.
Step 3 - Select a foundation model
The basis of the generative ai is based on large language model (LLM) which is a type of machine learning model that can perform a variety of natural language processing (NLP) tasks such as generating and classifying text, answering questions in a conversational manner, and translating text from one language to another.
We can select a model that best fits your needs. All models support English text.
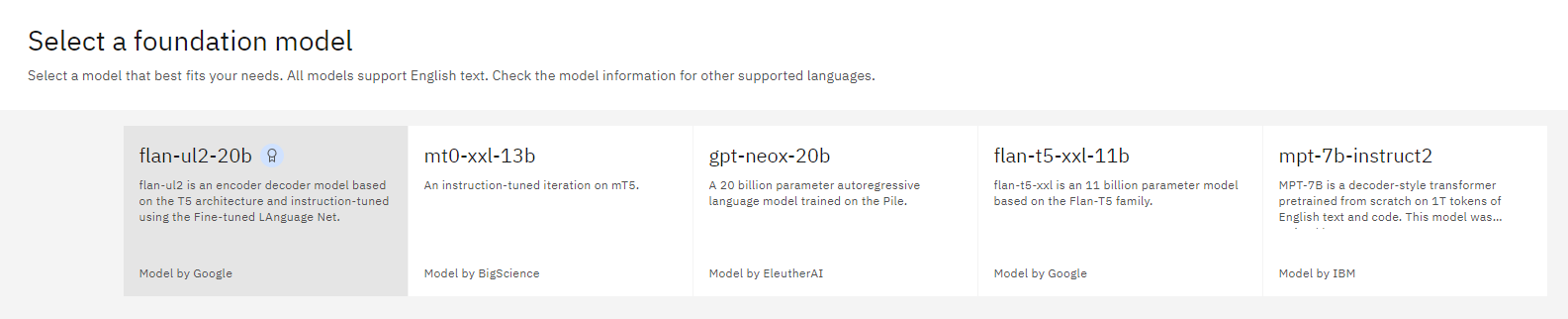
Among available models we have:
-
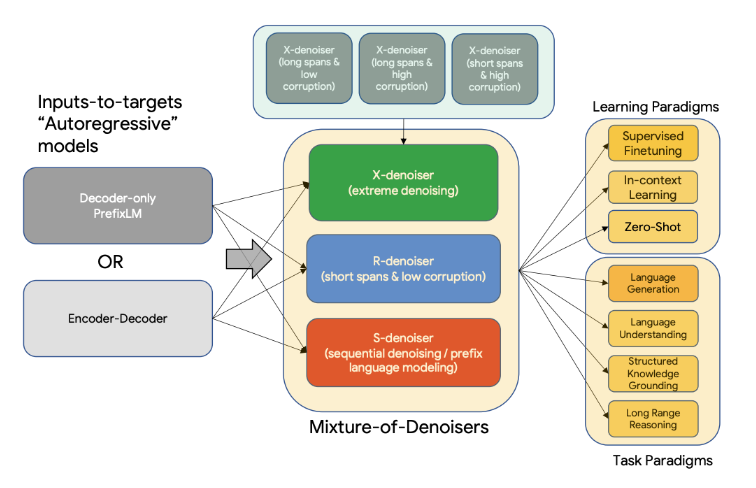
The Flan-UL2 model is an encoder-decoder model based on the T5 architecture. It has 20 billion parameters. It was fine-tuned using the “Flan” prompt tuning and dataset collection. The original UL2 model was only trained with a receptive field of 512, which made it non-ideal for N-shot prompting where N is large. The Flan-UL2 checkpoint uses a receptive field of 2048 which makes it more usable for few-shot in-context learning. For more details, please see sections 3.1.2 of the paper.
-
BLOOMZ & mT0, a family of models capable of following human instructions in dozens of languages zero-shot. We finetune BLOOM & mT5 pretrained multilingual language models on our crosslingual task mixture (xP3) and find our resulting models capable of crosslingual generalization to unseen tasks & languages.
-
GPT-NeoX-20B is a 20 billion parameter autoregressive language model trained on the Pile using the GPT-NeoX library. Its architecture intentionally resembles that of GPT-3, and is almost identical to that of GPT-J- 6B. Its training dataset contains a multitude of English-language texts, reflecting the general-purpose nature of this model. More idetails about model architecture (including how it differs from GPT-3),training procedure, and additional evaluations see this reference.
-
T5, FLAN-T5 is just better at everything. For the same number of parameters, these models have been fine-tuned on more than 1000 additional tasks covering also more languages.
-
MPT-7B-Instruct2 is a retrained version of the orignal MPT-7B-Instruct model is a short-form instruction following decoder-only model.
See model cards for MPT-7B and MPT-7B-Instruct for more information.
In this post we are going to choose the Flan-UL2 model. For other supported languages we have check each models.
Model Parameters
Nucleus sampling is a technique used in large language models to control the randomness and diversity of generated text. It works by sampling from only the most likely tokens in the model’s predicted distribution.
The key parameters are:
- Temperature: Controls randomness, higher values increase diversity.
- Top-p (nucleus): The cumulative probability cutoff for token selection. Lower values mean sampling from a smaller, more top-weighted nucleus.
- Top-k: Sample from the k most likely next tokens at each step. Lower k focuses on higher probability tokens.
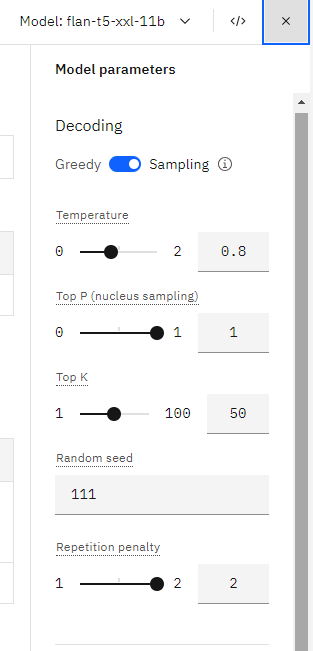
In general:
- Higher temperature will make outputs more random and diverse.
- Lower top-p values reduce diversity and focus on more probable tokens.
- Lower top-k also concentrates sampling on the highest probability tokens for each step.
So temperature increases variety, while top-p and top-k reduce variety and focus samples on the model’s top predictions. You have to balance diversity and relevance when tuning these parameters for different applications.
Step 4 - Choose the sample prompt you want to use.
WatsonX may be used for different applications. Let us examine some interesting applications.
Summarization
Let us assume an user case where we have to summarize a discussion from a meeting transcript.
- Meetings transcript summary - It is summarized the discussions
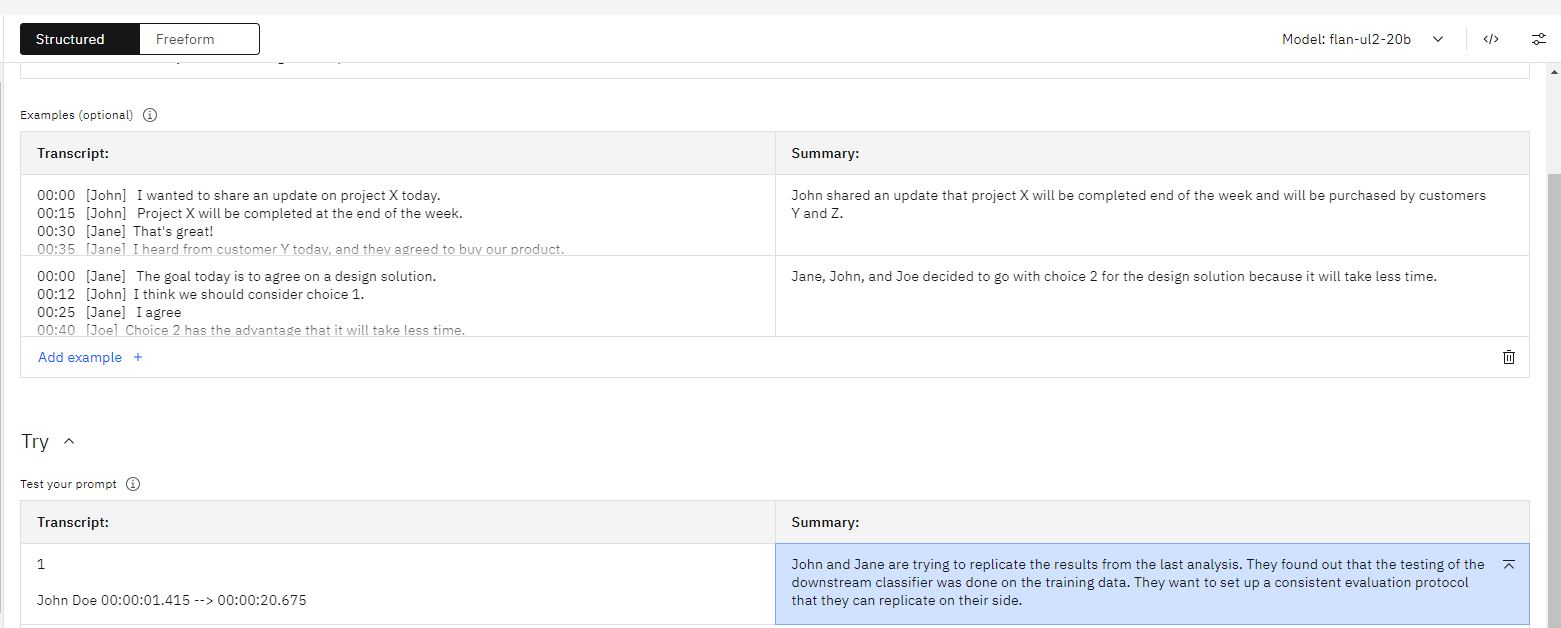
We can choose the sample prompt paste the transcript if you have and just click generate. Here in this example we have used our flan-ul2-20b model.
You have tune this output by changing the parameters of the model.
- Earnings call summary - Summarize financial highlights from earning call
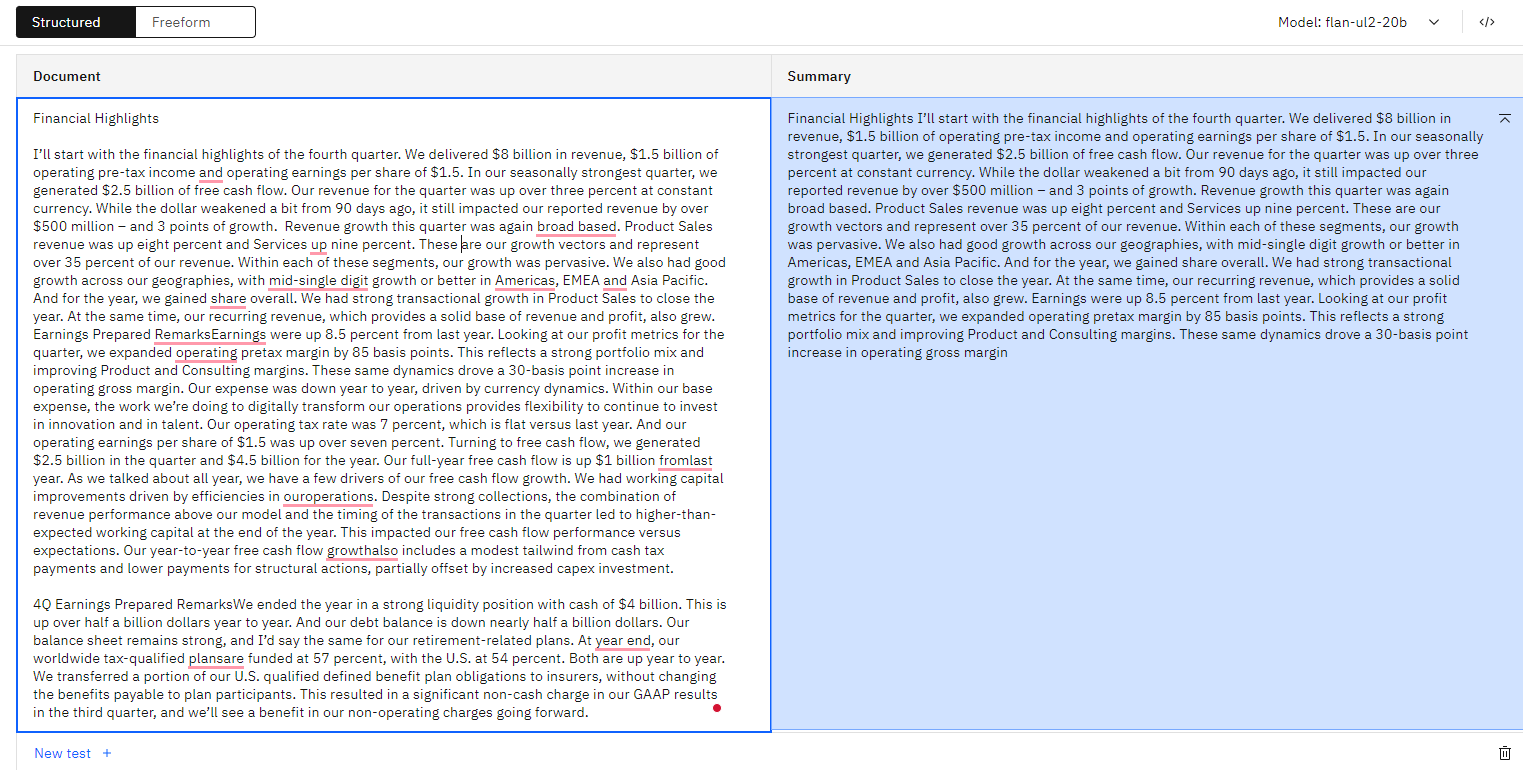
Here as well you can summarize bunch of text into simple paragraphs. Notice that not always the summarization can be perfect but can be a good starting point.
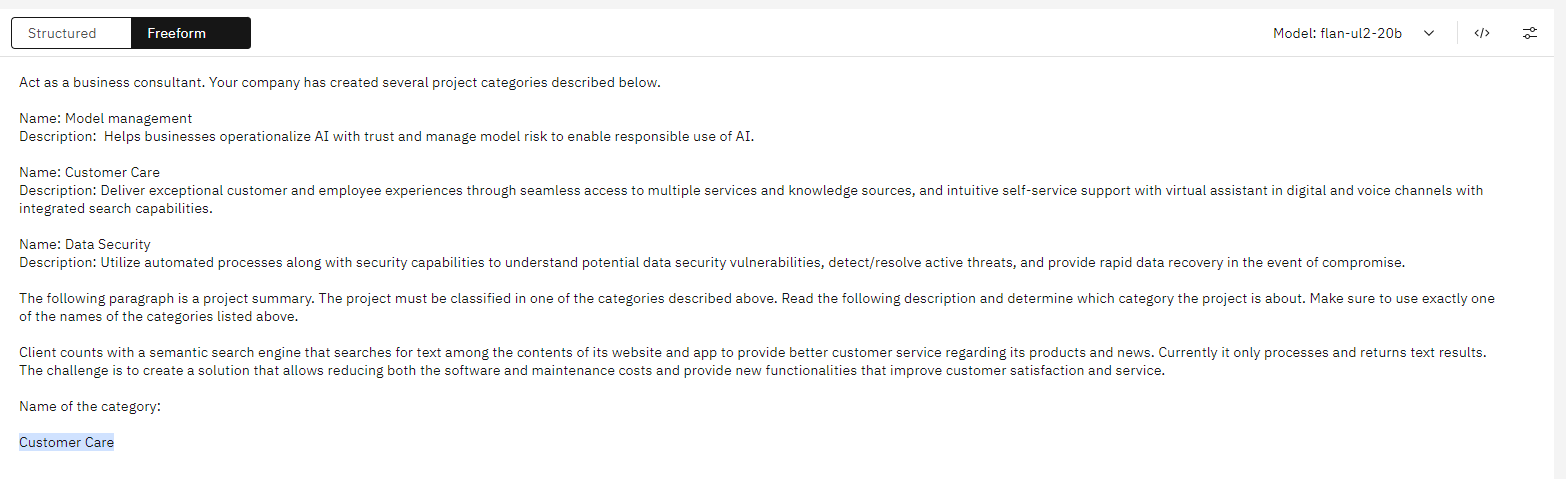
Classification
-
Scenario classification - Classify scenario based on project categories.
-
Sentiment classification - Classify reviews as positive or negative
Generation
- Marketing email generation - Generate email for marketing campaign
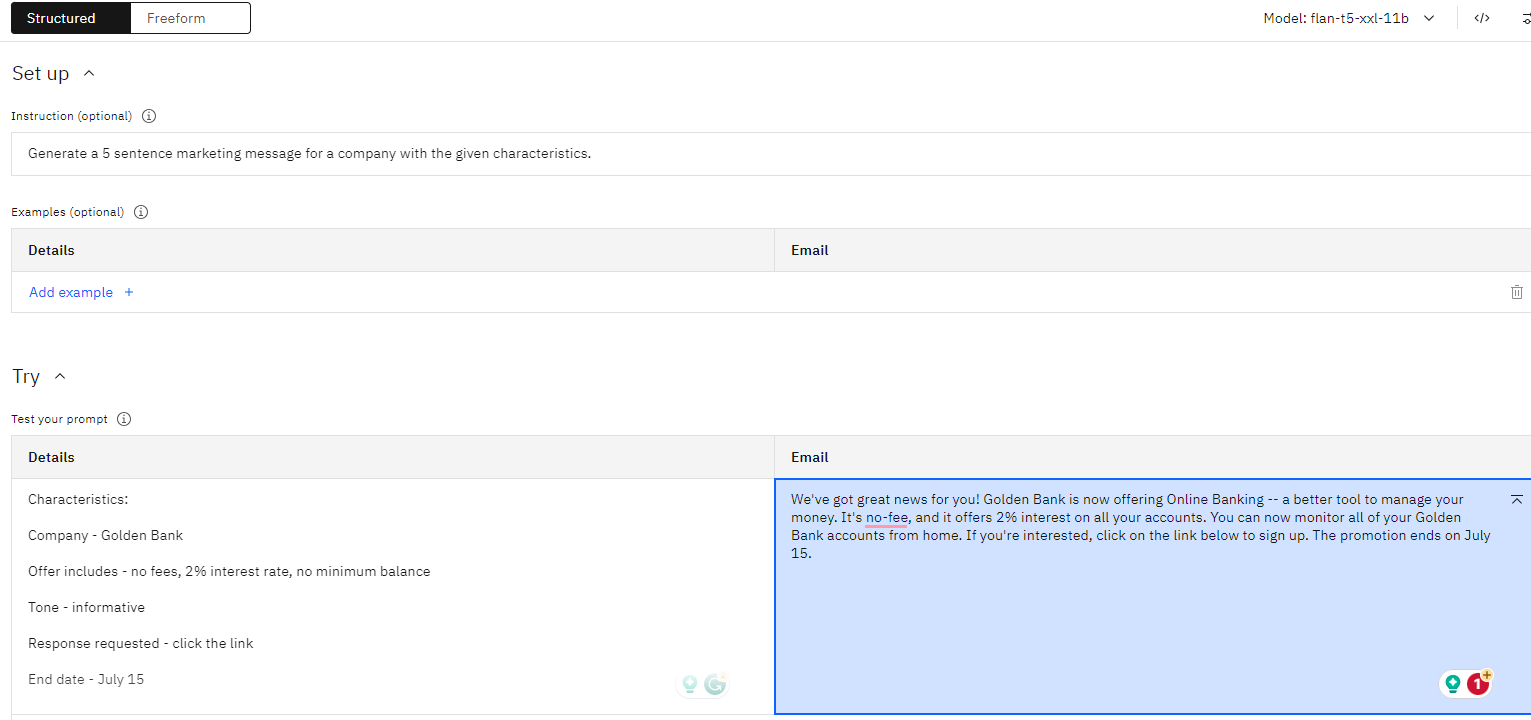
- Thank you note generation - Generate thank you note for workshop attendees.

Extraction
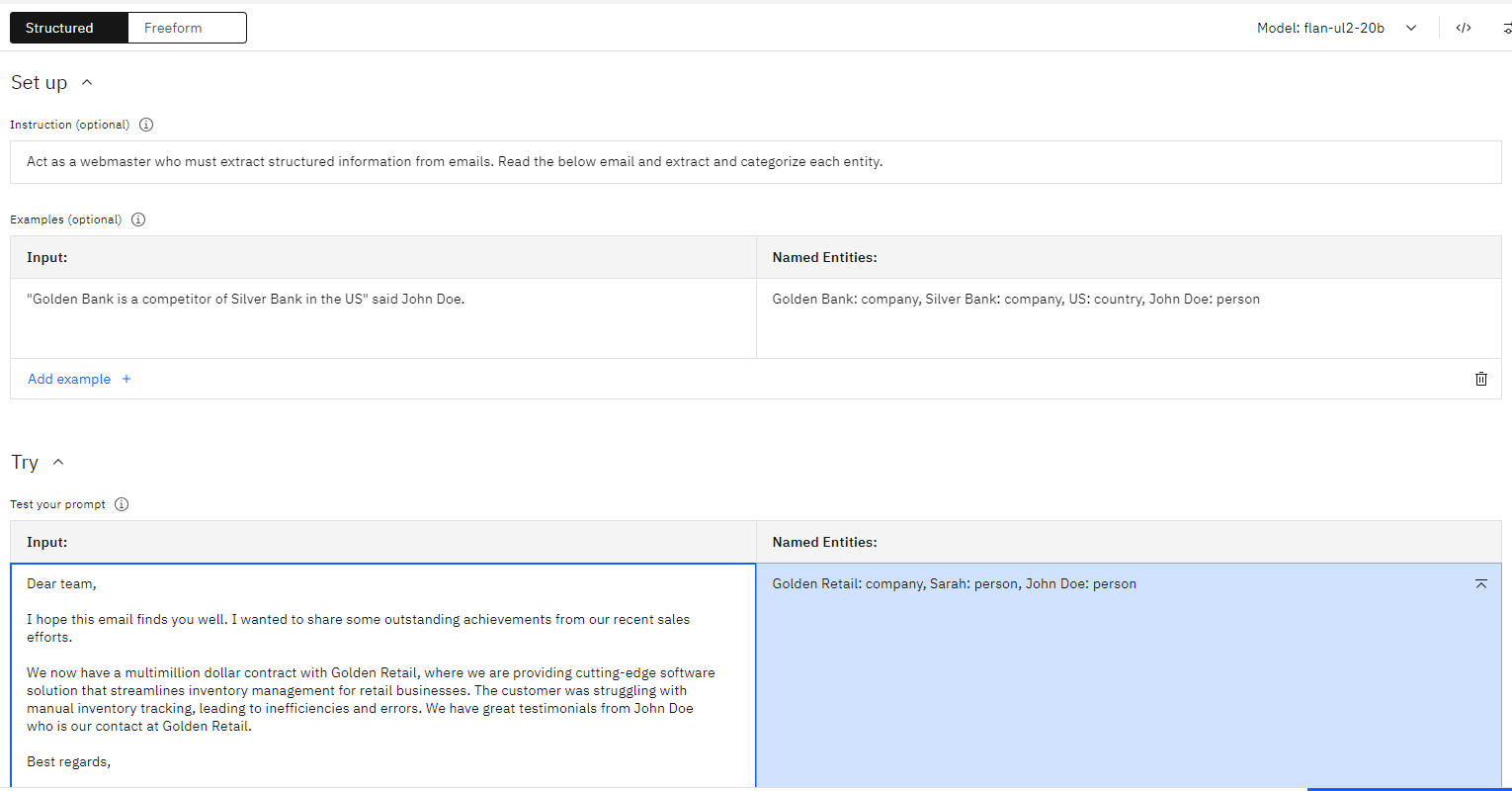
- Name entity extraction - Find and classify entities in unstructured text.
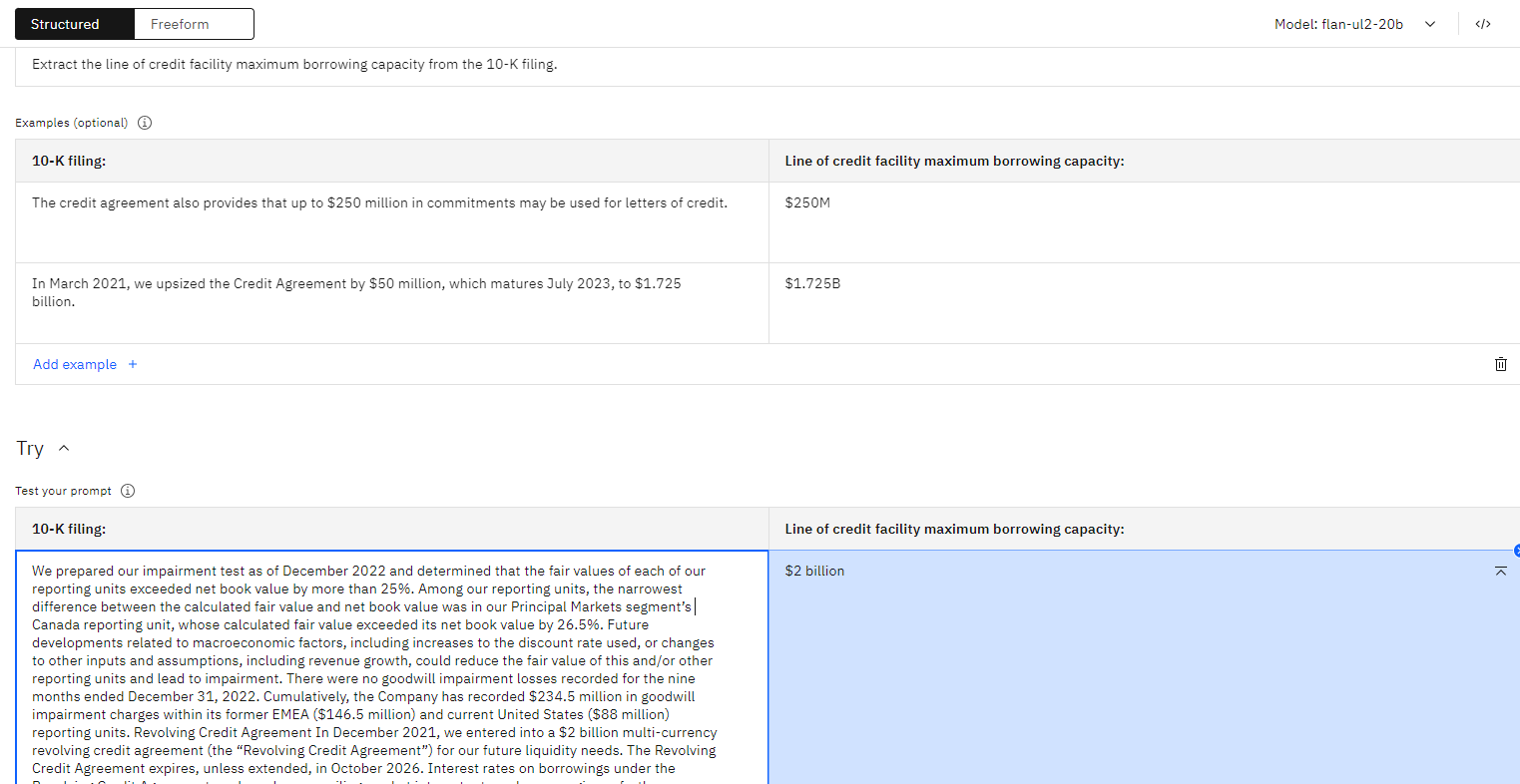
- Fact extraction - Extract information from K sentences.
Question answering
- Questions about an article - Answer questions about a body of text.
Important to know
AI hallucinations
- An AI hallucination is when a large language model (LLM) generates false information They occur because LLMs have no understanding of the underlying reality that language describes. LLMs use statistics to generate language that is grammatically and semantically correct within the context of the prompt.
- When a foundation model generates off-topic, repetitive, or incorrect content or fabricates details, that behavior is sometimes called hallucination. Off-topic hallucinations can happen because of pseudo-randomness in the decoding of the generated output. In the best cases, that randomness can result in wonderfully creative output. But it can also result in nonsense output that is not useful. Hallucinations involving fabricating details can happen when a model is prompted to generate text, but the model doesn’t have enough related text to draw upon (in the prompt, for example) to generate a result that contains the correct details.
Reducing the risk of hallucinations
- Choose a model with pretraining and fine-tuning that matches the domain and task you are performing.
- Provide context in your prompt. Instructing a foundation model to generate text on a subject that is not common in its pretraining data and for which no context has been provided in the prompt increases the likelihood of hallucinations.
- Specify conservative values for the Min tokens and Max tokens parameters and specify one or more stop sequences. Forcing a response that is longer than a model would naturally produce for a given prompt by specifying a high value for the Min tokens parameter increases the likelihood of hallucinations.
- To reduce the risk of off-topic hallucination with use cases that don’t require much creativity in the generated output, use greedy decoding or specify conservative values for the temperature, top-p, and top-k parameters with sampling decoding.
- To reduce repetitive text in the generated output, try increasing the repetition penalty parameter.
- If you are using greedy decoding and you see repetitive text in the generated output, and if some creativity is acceptable for your use case, use sampling decoding with moderately low values for the temperature, top-p, and top-k parameters.
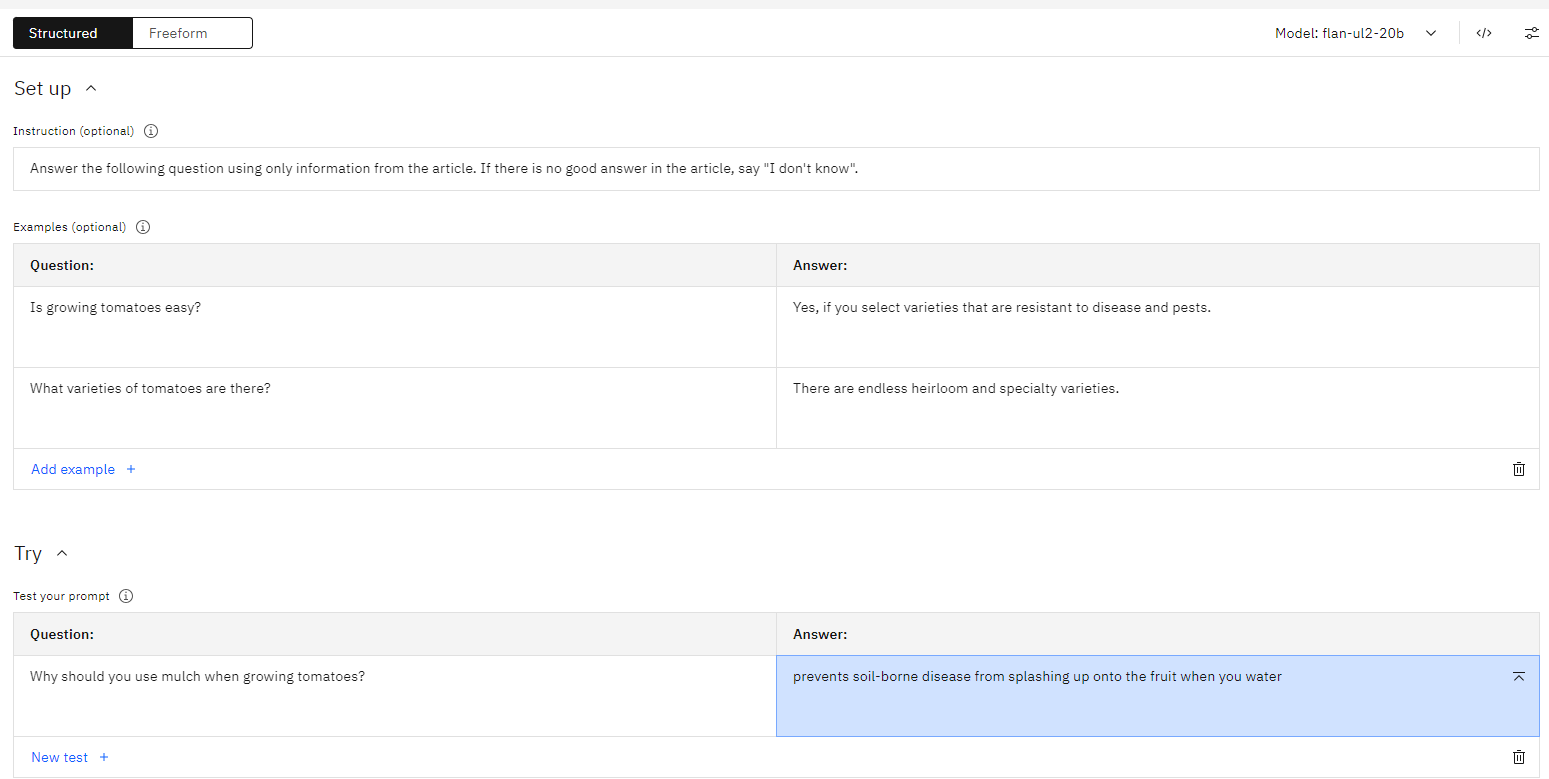
- In your prompt, instruct the model what to do in the case it has no confident or high-probability answer. For example, in a question-answering scenario, you could include the instruction: “If the answer is not in the article, say ‘I don’t know.’”
Bias
- During pretraining, a foundation model learns the statistical probability that certain words follow other words based on how those words appear in the training data. Any bias in the training data will be trained into the model. For example, if the training data more frequently refers to doctors as men and nurses as women, that bias will be reflected in the statistical relationships between those words in the model, and so the model will generate output that more frequently refers to doctors as men and nurses as women. Sometimes, people believe algorithms can be more fair and unbiased than humans because the algorithms are “just using math to reach decisions.” But bias in training data will be reflected in content generated by foundation models trained on that data.
Reducing the risk of bias in generated output
It is very difficult to debias output generated by a foundation model pretrained on biased data. However, you might improve results by including content in your prompt to counter bias which might apply to your use case. For example, instead of instructing a model to “list heart attack symptoms” you might instruct the model to “list heart attack symptoms, including symptoms common for men and symptoms common for women.”
Congratulations! We have tested Generative AI with IBM WatsonX.
Leave a comment