How to create Data Warehouse with Redshift

Data Warehouse
In this project, we will acreate a data warehouse by using AWS and build an ETL pipeline for a database hosted on Redshift.
We will need to load data from S3 to staging tables on Redshift and execute SQL statements that create the analytics tables from these staging tables.
Introduction
A music streaming startup, Sparkify, has grown their user base and song database and want to move their processes and data onto the cloud. Their data resides in S3, in a directory of JSON logs on user activity on the app, as well as a directory with JSON metadata on the songs in their app.
As their data engineer, you are tasked with building an ETL pipeline that extracts their data from S3, stages them in Redshift, and transforms data into a set of dimensional tables for their analytics team to continue finding insights in what songs their users are listening to. You’ll be able to test your database and ETL pipeline by running queries given to you by the analytics team from Sparkify and compare your results with their expected results.
The project require five files:
create_table.py is where we create the fact and dimension tables for the star schema in Redshift.
etl.py is where we koad data from S3 into staging tables on Redshift and then process that data into your analytics tables on Redshift.
sql_queries.py is where we define you SQL statements, which will be imported into the two other files above.
create_cluster_redshift.ipynb is where we create the AWS Redshift Cluster by using SDK.
dwh.cfg is the info about the personal account of AWS
Step 1 :Create Table Schemas
Design schemas for your fact and dimension tables Write a SQL CREATE statement for each of these tables in sql_queries.py
Using the song and event datasets, we create a star schema optimized for queries on song play analysis.
The first dataset is a subset of real data from the Million Song Dataset. Each file is in JSON format and contains metadata about a song and the artist of that song. The files are partitioned by the first three letters of each song’s track ID.
The second dataset consists of log files in JSON format generated by this event simulator based on the songs in the dataset above. These simulate app activity logs from an imaginary music streaming app based on configuration settings. The log files in the dataset you’ll be working with are partitioned by year and month.
This includes the following tables.
Fact Table
songplays - records in event data associated with song plays i.e. records with page NextSong songplay_id, start_time, user_id, level, song_id, artist_id, session_id, location, user_agent
Dimension Tables
users - users in the app user_id, first_name, last_name, gender, level songs - songs in music database song_id, title, artist_id, year, duration artists - artists in music database artist_id, name, location, lattitude, longitude time - timestamps of records in songplays broken down into specific units start_time, hour, day, week, month, year, weekday
We create the file sql_queries.py
import configparser
# CONFIG
config = configparser.ConfigParser()
config.read('dwh.cfg')
# DROP TABLES
staging_events_table_drop = "DROP TABLE IF EXISTS stagingevents;"
staging_songs_table_drop = "DROP TABLE IF EXISTS stagingsongs;"
songplay_table_drop = "DROP TABLE IF EXISTS songplays"
user_table_drop = "DROP TABLE IF EXISTS users;"
song_table_drop = "DROP TABLE IF EXISTS songs;"
artist_table_drop = "DROP TABLE IF EXISTS artists;"
time_table_drop = "DROP TABLE IF EXISTS time;"
ARN = config.get('IAM_ROLE', 'ARN')
LOG_DATA = config.get('S3', 'LOG_DATA')
LOG_JSONPATH = config.get('S3', 'LOG_JSONPATH')
SONG_DATA = config.get('S3', 'SONG_DATA')
# CREATE TABLES
staging_events_table_create= ("""CREATE TABLE IF NOT EXISTS stagingevents (
event_id BIGINT IDENTITY(0,1) NOT NULL,
artist VARCHAR NULL,
auth VARCHAR NULL,
firstName VARCHAR NULL,
gender VARCHAR NULL,
itemInSession VARCHAR NULL,
lastName VARCHAR NULL,
length VARCHAR NULL,
level VARCHAR NULL,
location VARCHAR NULL,
method VARCHAR NULL,
page VARCHAR NULL,
registration VARCHAR NULL,
sessionId INTEGER NOT NULL SORTKEY DISTKEY,
song VARCHAR NULL,
status INTEGER NULL,
ts BIGINT NOT NULL,
userAgent VARCHAR NULL,
userId INTEGER NULL);""")
staging_songs_table_create = ("""CREATE TABLE IF NOT EXISTS stagingsongs (
num_songs INTEGER NULL,
artist_id VARCHAR NOT NULL SORTKEY DISTKEY,
artist_latitude VARCHAR NULL,
artist_longitude VARCHAR NULL,
artist_location VARCHAR(500) NULL,
artist_name VARCHAR(500) NULL,
song_id VARCHAR NOT NULL,
title VARCHAR(500) NULL,
duration DECIMAL(9) NULL,
year INTEGER NULL);""")
songplay_table_create = ("""CREATE TABLE IF NOT EXISTS songplays (
songplay_id INTEGER IDENTITY(0,1) NOT NULL SORTKEY,
start_time TIMESTAMP NOT NULL,
user_id VARCHAR(50) NOT NULL DISTKEY,
level VARCHAR(10) NOT NULL,
song_id VARCHAR(40) NOT NULL,
artist_id VARCHAR(50) NOT NULL,
session_id VARCHAR(50) NOT NULL,
location VARCHAR(100) NULL,
user_agent VARCHAR(255) NULL
);""")
user_table_create = (""" CREATE TABLE IF NOT EXISTS users (
user_id INTEGER NOT NULL SORTKEY,
first_name VARCHAR(50) NULL,
last_name VARCHAR(80) NULL,
gender VARCHAR(10) NULL,
level VARCHAR(10) NULL
) diststyle all;""")
song_table_create = ("""CREATE TABLE IF NOT EXISTS songs (
song_id VARCHAR(50) NOT NULL SORTKEY,
title VARCHAR(500) NOT NULL,
artist_id VARCHAR(50) NOT NULL,
year INTEGER NOT NULL,
duration DECIMAL(9) NOT NULL
);""")
artist_table_create = ("""CREATE TABLE IF NOT EXISTS artists (
artist_id VARCHAR(50) NOT NULL SORTKEY,
name VARCHAR(500) NULL,
location VARCHAR(500) NULL,
latitude DECIMAL(9) NULL,
longitude DECIMAL(9) NULL
) diststyle all;""")
time_table_create = ("""CREATE TABLE IF NOT EXISTS time (
start_time TIMESTAMP NOT NULL SORTKEY,
hour SMALLINT NULL,
day SMALLINT NULL,
week SMALLINT NULL,
month SMALLINT NULL,
year SMALLINT NULL,
weekday SMALLINT NULL
) diststyle all;""")
# STAGING TABLES
staging_events_copy = ("""COPY stagingevents FROM {}
credentials 'aws_iam_role={}'
format as json {}
STATUPDATE ON
region 'us-west-2';
""").format(LOG_DATA, ARN, LOG_JSONPATH)
staging_songs_copy = ("""
COPY stagingsongs FROM {}
credentials 'aws_iam_role={}'
format as json 'auto'
ACCEPTINVCHARS AS '^'
STATUPDATE ON
region 'us-west-2';
""").format(SONG_DATA, ARN)
# FINAL TABLES
songplay_table_insert = ("""INSERT INTO songplays (start_time,
user_id,
level,
song_id,
artist_id,
session_id,
location,
user_agent) SELECT DISTINCT TIMESTAMP 'epoch' + se.ts/1000 \
* INTERVAL '1 second' AS start_time,
se.userId AS user_id,
se.level AS level,
ss.song_id AS song_id,
ss.artist_id AS artist_id,
se.sessionId AS session_id,
se.location AS location,
se.userAgent AS user_agent
FROM stagingevents AS se
JOIN stagingsongs AS ss
ON (se.artist = ss.artist_name)
WHERE se.page = 'NextSong';""")
user_table_insert = ("""INSERT INTO users (user_id,
first_name,
last_name,
gender,
level)
SELECT DISTINCT se.userId AS user_id,
se.firstName AS first_name,
se.lastName AS last_name,
se.gender AS gender,
se.level AS level
FROM stagingevents AS se
WHERE se.page = 'NextSong';""")
song_table_insert = ("""INSERT INTO songs(song_id,
title,
artist_id,
year,
duration)
SELECT DISTINCT ss.song_id AS song_id,
ss.title AS title,
ss.artist_id AS artist_id,
ss.year AS year,
ss.duration AS duration
FROM stagingsongs AS ss;""")
artist_table_insert = ("""INSERT INTO artists (artist_id,
name,
location,
latitude,
longitude)
SELECT DISTINCT ss.artist_id AS artist_id,
ss.artist_name AS name,
ss.artist_location AS location,
ss.artist_latitude AS latitude,
ss.artist_longitude AS longitude
FROM stagingsongs AS ss;
""")
time_table_insert = ("""INSERT INTO time (start_time,
hour,
day,
week,
month,
year,
weekday)
SELECT DISTINCT TIMESTAMP 'epoch' + se.ts/1000 \
* INTERVAL '1 second' AS start_time,
EXTRACT(hour FROM start_time) AS hour,
EXTRACT(day FROM start_time) AS day,
EXTRACT(week FROM start_time) AS week,
EXTRACT(month FROM start_time) AS month,
EXTRACT(year FROM start_time) AS year,
EXTRACT(week FROM start_time) AS weekday
FROM stagingevents AS se
WHERE se.page = 'NextSong';""")
# QUERY LISTS
create_table_queries = [staging_events_table_create, staging_songs_table_create, songplay_table_create, user_table_create, song_table_create, artist_table_create, time_table_create]
drop_table_queries = [staging_events_table_drop, staging_songs_table_drop, songplay_table_drop, user_table_drop, song_table_drop, artist_table_drop, time_table_drop]
copy_table_queries = [staging_events_copy, staging_songs_copy]
insert_table_queries = [songplay_table_insert, user_table_insert, song_table_insert, artist_table_insert, time_table_insert]
Step 2: Create Table Schemas in the Database
We the create_tables.py to connect to the database and create these tables:
import configparser
import psycopg2
from sql_queries import create_table_queries, drop_table_queries
def drop_tables(cur, conn):
"""
Delete pre-existing tables to be able to create them from scratch
"""
print('Droping tables')
for query in drop_table_queries:
cur.execute(query)
conn.commit()
def create_tables(cur, conn):
"""
Create staging and dimensional tables declared on sql_queries script
"""
for query in create_table_queries:
cur.execute(query)
conn.commit()
def main():
"""
Set up the database tables, create needed tables with the appropriate columns and constricts
"""
config = configparser.ConfigParser()
config.read('dwh.cfg')
conn = psycopg2.connect("host={} dbname={} user={} password={} port={}".format(*config['CLUSTER'].values()))
cur = conn.cursor()
print('Connected to the cluster')
drop_tables(cur, conn)
create_tables(cur, conn)
conn.close()
if __name__ == "__main__":
main()
Step 3: Creating Redshift Cluster using the AWS python SDK
We create the cluster by using the python SDK create_cluster_redshift.ipynb
#pip install boto3
import pandas as pd
import boto3
import json
Creation of the user on AWS.
First we need create a new IAM user in our AWS account Give it AdministratorAccess from existing policies. Copy the access key and secret Add to the the dwh.cfg file, the following:
[AWS]
KEY= YOUR_AWS_KEY
SECRET= YOUR_AWS_SECRET
[CLUSTER]
HOST=dwhcluster.XXXXX.us-west-2.redshift.amazonaws.com
DB_NAME=dwh
DB_USER=dwhuser
DB_PASSWORD=dwhPassword00
DB_PORT=5439
[IAM_ROLE]
ARN=arn:aws:iam::XXXXXXXX:role/dwhRedshiftRole
[S3]
LOG_DATA='s3://udacity-dend/log_data'
LOG_JSONPATH='s3://udacity-dend/log_json_path.json'
SONG_DATA='s3://udacity-dend/song_data'
[AWS]
KEY=
SECRET=
[DWH]
DWH_CLUSTER_TYPE=multi-node
DWH_NUM_NODES=4
DWH_NODE_TYPE=dc2.large
DWH_IAM_ROLE_NAME=dwhRedshiftRole
DWH_CLUSTER_IDENTIFIER=dwhCluster
DWH_DB=dwh
DWH_DB_USER=dwhuser
DWH_DB_PASSWORD=dwhPassword00
DWH_PORT=5439
Load info from a file
import configparser
config = configparser.ConfigParser()
config.read_file(open('dwh.cfg'))
KEY = config.get('AWS','KEY')
SECRET = config.get('AWS','SECRET')
DWH_CLUSTER_TYPE = config.get("DWH","DWH_CLUSTER_TYPE")
DWH_NUM_NODES = config.get("DWH","DWH_NUM_NODES")
DWH_NODE_TYPE = config.get("DWH","DWH_NODE_TYPE")
DWH_CLUSTER_IDENTIFIER = config.get("DWH","DWH_CLUSTER_IDENTIFIER")
DWH_DB = config.get("DWH","DWH_DB")
DWH_DB_USER = config.get("DWH","DWH_DB_USER")
DWH_DB_PASSWORD = config.get("DWH","DWH_DB_PASSWORD")
DWH_PORT = config.get("DWH","DWH_PORT")
DWH_IAM_ROLE_NAME = config.get("DWH", "DWH_IAM_ROLE_NAME")
(DWH_DB_USER, DWH_DB_PASSWORD, DWH_DB)
pd.DataFrame({"Param":
["KEY","DWH_CLUSTER_TYPE", "DWH_NUM_NODES", "DWH_NODE_TYPE", "DWH_CLUSTER_IDENTIFIER", "DWH_DB", "DWH_DB_USER", "DWH_DB_PASSWORD", "DWH_PORT", "DWH_IAM_ROLE_NAME"],
"Value":
[KEY, DWH_CLUSTER_TYPE, DWH_NUM_NODES, DWH_NODE_TYPE, DWH_CLUSTER_IDENTIFIER, DWH_DB, DWH_DB_USER, DWH_DB_PASSWORD, DWH_PORT, DWH_IAM_ROLE_NAME]
})
| Param | Value | |
|---|---|---|
| 0 | KEY | |
| 1 | DWH_CLUSTER_TYPE | multi-node |
| 2 | DWH_NUM_NODES | 4 |
| 3 | DWH_NODE_TYPE | dc2.large |
| 4 | DWH_CLUSTER_IDENTIFIER | dwhCluster |
| 5 | DWH_DB | dwh |
| 6 | DWH_DB_USER | dwhuser |
| 7 | DWH_DB_PASSWORD | dwhPassword |
| 8 | DWH_PORT | 5439 |
| 9 | DWH_IAM_ROLE_NAME | dwhRedshiftRole |
Create clients for EC2, S3, IAM, and Redshift
import boto3
ec2 = boto3.resource('ec2',
region_name="us-west-2",
aws_access_key_id=KEY,
aws_secret_access_key=SECRET
)
s3 = boto3.resource('s3',
region_name="us-west-2",
aws_access_key_id=KEY,
aws_secret_access_key=SECRET
)
iam = boto3.client('iam',aws_access_key_id=KEY,
aws_secret_access_key=SECRET,
region_name='us-west-2'
)
redshift = boto3.client('redshift',
region_name="us-west-2",
aws_access_key_id=KEY,
aws_secret_access_key=SECRET
)
Check out the sample data sources on S3
sampleDbBucket = s3.Bucket("awssampledbuswest2")
for obj in sampleDbBucket.objects.filter(Prefix="ssbgz"):
print (obj)
s3.ObjectSummary(bucket_name='awssampledbuswest2', key='ssbgz/')
s3.ObjectSummary(bucket_name='awssampledbuswest2', key='ssbgz/customer0002_part_00.gz')
s3.ObjectSummary(bucket_name='awssampledbuswest2', key='ssbgz/dwdate.tbl.gz')
s3.ObjectSummary(bucket_name='awssampledbuswest2', key='ssbgz/lineorder0000_part_00.gz')
s3.ObjectSummary(bucket_name='awssampledbuswest2', key='ssbgz/lineorder0001_part_00.gz')
s3.ObjectSummary(bucket_name='awssampledbuswest2', key='ssbgz/lineorder0002_part_00.gz')
s3.ObjectSummary(bucket_name='awssampledbuswest2', key='ssbgz/lineorder0003_part_00.gz')
s3.ObjectSummary(bucket_name='awssampledbuswest2', key='ssbgz/lineorder0004_part_00.gz')
s3.ObjectSummary(bucket_name='awssampledbuswest2', key='ssbgz/lineorder0005_part_00.gz')
s3.ObjectSummary(bucket_name='awssampledbuswest2', key='ssbgz/lineorder0006_part_00.gz')
s3.ObjectSummary(bucket_name='awssampledbuswest2', key='ssbgz/lineorder0007_part_00.gz')
s3.ObjectSummary(bucket_name='awssampledbuswest2', key='ssbgz/part0000_part_00.gz')
s3.ObjectSummary(bucket_name='awssampledbuswest2', key='ssbgz/part0001_part_00.gz')
s3.ObjectSummary(bucket_name='awssampledbuswest2', key='ssbgz/part0002_part_00.gz')
s3.ObjectSummary(bucket_name='awssampledbuswest2', key='ssbgz/part0003_part_00.gz')
s3.ObjectSummary(bucket_name='awssampledbuswest2', key='ssbgz/supplier.tbl_0000_part_00.gz')
s3.ObjectSummary(bucket_name='awssampledbuswest2', key='ssbgz/supplier0001_part_00.gz')
s3.ObjectSummary(bucket_name='awssampledbuswest2', key='ssbgz/supplier0002_part_00.gz')
s3.ObjectSummary(bucket_name='awssampledbuswest2', key='ssbgz/supplier0003_part_00.gz')
IAM ROLE
- Create an IAM Role that makes Redshift able to access S3 bucket (ReadOnly)
# TODO: Create the IAM role
try:
print('1.1 Creating a new IAM Role')
dwhRole = iam.create_role(
Path='/',
RoleName=DWH_IAM_ROLE_NAME,
Description='Allows Redshift clusters to call AWS services on your behalf.',
AssumeRolePolicyDocument=json.dumps({
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "redshift.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}),
)
except Exception as e:
print(e)
1.1 Creating a new IAM Role
# TODO: Attach Policy
print('1.2 Attaching Policy')
iam.attach_role_policy(RoleName=DWH_IAM_ROLE_NAME,
PolicyArn="arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess"
)['ResponseMetadata']['HTTPStatusCode']
1.2 Attaching Policy
200
# TODO: Get and print the IAM role ARN
print('1.3 Get the IAM role ARN')
roleArn = iam.get_role(RoleName=DWH_IAM_ROLE_NAME)['Role']['Arn']
print(roleArn)
1.3 Get the IAM role ARN
arn:aws:iam::xxxxxx:role/dwhRedshiftRole
Redshift Cluster
- Create a RedShift Cluster
- For complete arguments to
create_cluster, see docs
try:
response = redshift.create_cluster(
#HW
ClusterType=DWH_CLUSTER_TYPE,
NodeType=DWH_NODE_TYPE,
NumberOfNodes=int(DWH_NUM_NODES),
#Identifiers & Credentials
DBName=DWH_DB,
ClusterIdentifier=DWH_CLUSTER_IDENTIFIER,
MasterUsername=DWH_DB_USER,
MasterUserPassword=DWH_DB_PASSWORD,
#Roles (for s3 access)
IamRoles=[roleArn]
)
except Exception as e:
print(e)
In addition on your console the cluster started to create
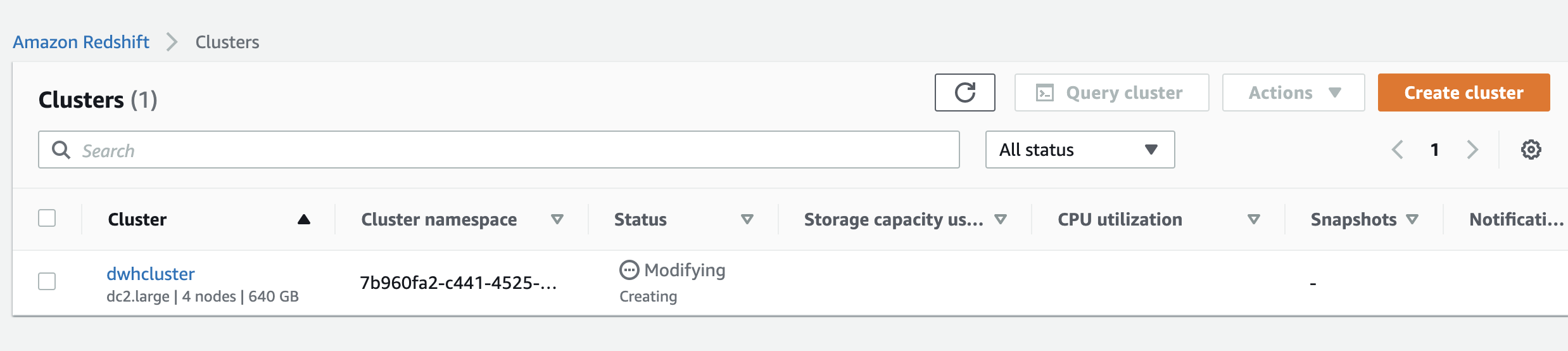
Describe the cluster to see its status
- run this block several times until the cluster status becomes
Available
def prettyRedshiftProps(props):
pd.set_option('display.max_colwidth', -1)
keysToShow = ["ClusterIdentifier", "NodeType", "ClusterStatus", "MasterUsername", "DBName", "Endpoint", "NumberOfNodes", 'VpcId']
x = [(k, v) for k,v in props.items() if k in keysToShow]
return pd.DataFrame(data=x, columns=["Key", "Value"])
myClusterProps = redshift.describe_clusters(ClusterIdentifier=DWH_CLUSTER_IDENTIFIER)['Clusters'][0]
prettyRedshiftProps(myClusterProps)
<ipython-input-19-b26b8a0b1a4c>:2: FutureWarning: Passing a negative integer is deprecated in version 1.0 and will not be supported in future version. Instead, use None to not limit the column width.
pd.set_option('display.max_colwidth', -1)
| Key | Value | |
|---|---|---|
| 0 | ClusterIdentifier | dwhcluster |
| 1 | NodeType | dc2.large |
| 2 | ClusterStatus | available |
| 3 | MasterUsername | dwhuser |
| 4 | DBName | dwh |
| 5 | Endpoint | {'Address': 'dwhcluster.xxxxx.us-west-2.redshift.amazonaws.com', 'Port': 5439} |
| 6 | VpcId | vpc-93bc54eb |
| 7 | NumberOfNodes | 4 |
When is available your server on the web console you have the following:
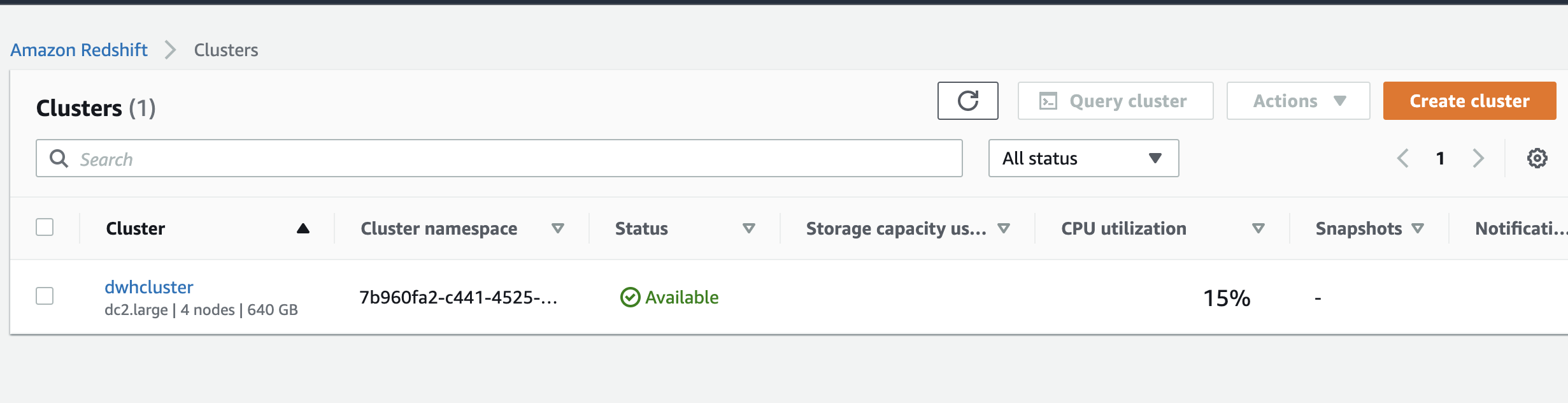
Take note of the cluster endpoint and role ARN
DO NOT RUN THIS unless the cluster status becomes "Available"DWH_ENDPOINT = myClusterProps['Endpoint']['Address']
DWH_ROLE_ARN = myClusterProps['IamRoles'][0]['IamRoleArn']
print("DWH_ENDPOINT :: ", DWH_ENDPOINT)
print("DWH_ROLE_ARN :: ", DWH_ROLE_ARN)
DWH_ENDPOINT :: dwhcluster.xxxxx.us-west-2.redshift.amazonaws.com
DWH_ROLE_ARN :: arn:aws:iam::xxxxx:role/dwhRedshiftRole
Open an incoming TCP port to access the cluster ednpoint
try:
vpc = ec2.Vpc(id=myClusterProps['VpcId'])
defaultSg = list(vpc.security_groups.all())[0]
print(defaultSg)
defaultSg.authorize_ingress(
GroupName=defaultSg.group_name,
CidrIp='0.0.0.0/0',
IpProtocol='TCP',
FromPort=int(DWH_PORT),
ToPort=int(DWH_PORT)
)
except Exception as e:
print(e)
ec2.SecurityGroup(id='xxxxx')
Make sure you can connect to the clusterConnect to the cluster
#pip install ipython-sql
%load_ext sql
conn_string="postgresql://{}:{}@{}:{}/{}".format(DWH_DB_USER, DWH_DB_PASSWORD, DWH_ENDPOINT, DWH_PORT,DWH_DB)
print(conn_string)
%sql $conn_string
postgresql://dwhuser:[email protected]:5439/dwh
Test by running create_tables.py and checking the table schemas in your redshift database. You can use Query Editor in the AWS Redshift console for this.
Step 5: Build ETL Pipeline
We Build ETL Pipeline. We Implement the logic in etl.py to load data from S3 to staging tables on Redshift.
import configparser
import psycopg2
from sql_queries import copy_table_queries, insert_table_queries
def load_staging_tables(cur, conn):
#Load data from files stored in S3 to the staging tables using the queries declared on the sql_queries script
for query in copy_table_queries:
cur.execute(query)
conn.commit()
def insert_tables(cur, conn):
#Select and Transform data from staging tables into the dimensional tables using the queries declared on the sql_queries script
for query in insert_table_queries:
cur.execute(query)
conn.commit()
def main():
#Extract songs metadata and user activity data from S3, transform it using a staging table, and load it into dimensional tables for analysis
config = configparser.ConfigParser()
config.read('dwh.cfg')
conn = psycopg2.connect("host={} dbname={} user={} password={} port={}".format(*config['CLUSTER'].values()))
cur = conn.cursor()
load_staging_tables(cur, conn)
insert_tables(cur, conn)
conn.close()
if __name__ == "__main__":
main()
STEP 6: We create the tables
Test by running etl.py after running create_tables.py and running the analytic queries on your Redshift database to compare your results with the expected results.
%run -i 'create_tables.py'
STEP 7: We execute the ETL
%run -i 'etl.py'
STEP 8: Clean up your resources
We have to delete our redshift cluster when finished.
Please delete your cluster to avoid charges!
#### CAREFUL!!
#-- Uncomment & run to delete the created resources
redshift.delete_cluster( ClusterIdentifier=DWH_CLUSTER_IDENTIFIER, SkipFinalClusterSnapshot=True)
#### CAREFUL!!
myClusterProps = redshift.describe_clusters(ClusterIdentifier=DWH_CLUSTER_IDENTIFIER)['Clusters'][0]
prettyRedshiftProps(myClusterProps)
| Key | Value | |
|---|---|---|
| 0 | ClusterIdentifier | dwhcluster |
| 1 | NodeType | dc2.large |
| 2 | ClusterStatus | deleting |
| 3 | MasterUsername | dwhuser |
| 4 | DBName | dwh |
| 5 | Endpoint | {'Address': 'dwhcluster.xxxxxx.us-west-2.redshift.amazonaws.com', 'Port': 5439} |
| 6 | VpcId | vpc-93bc54eb |
| 7 | NumberOfNodes | 4 |
#### CAREFUL!!
#-- Uncomment & run to delete the created resources
iam.detach_role_policy(RoleName=DWH_IAM_ROLE_NAME, PolicyArn="arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess")
iam.delete_role(RoleName=DWH_IAM_ROLE_NAME)
#### CAREFUL!!
Congratulations we have created a Redshift cluter with and created a database !
Leave a comment