
Diffusion Models in Artificial Intelligence for Generative AI
Dear all, today we are going to discuss the buildings blocks of the Diffusion Models applied to Artificial Intelligence for Generative AI.
We are interested to know how the diffusion works. The achievement of those technologies has been possible thanks to the long scientific works during the History. In this blog post, we are going to build an interesting program in python that will generate images by using the diffusion and recap the theory of the diffusion process like the following
MNIST

Fashion-MNIST

CIFAR
We are going to discuss the Theory and Application of Denoising Diffusion Models.
Introduction
One of the greatest ideas that allows the Artificial Intelligence build images from a text is the Markov chain. Andrey Markov studied Markov processes in the early 20th century, publishing his first paper on the topic in 1906. Important people contributed to his research such Heinri Poincare , Ehrenfest , Andrey Kolmogorov. Kolmogorov was partly inspired by Louis Bachelier’s 1900 work on fluctuations in the stock market as well as Norbert Wiener’s work on Einstein’s model of Brownian movement.
A Markov chain or Markov process is a stochastic model describing a sequence of possible events in which the probability of each event depends only on the state attained in the previous event.
A Markov process is a stochastic process that satisfies the Markov property. In simpler terms, it is a process for which predictions can be made regarding future outcomes based solely on its present state and—most importantly—such predictions are just as good as the ones that could be made knowing the process’s full history. In other words, conditional on the present state of the system, its future and past states are independent.
Diffusion models are a new class of state-of-the-art generative models that generate diverse high-resolution images. They have already attracted a lot of attention after OpenAI, Nvidia , Google and IBM managed to train large-scale models. Example architectures that are based on diffusion models are GLIDE, DALLE-2, Imagen, and the full open-source stable diffusion.
But what is the main principle behind them?
Let us deep dive in the theory in Denoising Diffusion Probabilistic Models.
Denoising Diffusion Probabilistic Models
Diffusion models are fundamentally different from all the previous generative methods. Intuitively, they aim to decompose the image generation process (sampling) in many small “denoising” steps. The intuition behind this is that the model can correct itself over these small steps and gradually produce a good sample. To some extent, this idea of refining the representation has already been used in models like alphafold. But hey, nothing comes at zero-cost. This iterative process makes them slow at sampling, at least compared to GANs. A nice summary of the paper Ho et al., 2020 by the authors is available here.
Diffusion process
The basic idea behind diffusion models is rather simple. They take the input image \(\mathbf{x}_0\) and gradually add Gaussian noise to it through a series of T steps. We will call this the forward process. Notably, this is unrelated to the forward pass of a neural network. If you’d like, this part is necessary to generate the targets for our neural network (the image after applying \(t<T\) noise steps).
Afterward, a neural network is trained to recover the original data by reversing the noising process. By being able to model the reverse process, we can generate new data. This is the so-called reverse diffusion process or, in general, the sampling process of a generative model.
Forward diffusion
Diffusion models can be seen as latent variable models. Latent means that we are referring to a hidden continuous feature space. In such a way, they may look similar to variational autoencoders (VAEs).
In practice, they are formulated using a Markov chain of T steps. Here, a Markov chain means that each step only depends on the previous one, which is a mild assumption. Importantly, we are not constrained to using a specific type of neural network, unlike flow-based models.
Given a data-point \(\textbf{x}_0\) sampled from the real data distribution \(q(x)( \textbf{x}_0 \sim q(x))\),one can define a forward diffusion process by adding noise.
Specifically, at each step of the Markov chain we add Gaussian noise with variance \(\beta_{t}\) to \(\textbf{x}_{t-1}\), producing a new latent variable \(\textbf{x}_{t}\) with distribution \(q(\textbf{x}_t |\textbf{x}_{t-1})\). This diffusion process can be formulated as follows:
\[\begin{equation} q(\mathbf{x}_t \vert \mathbf{x}_{t-1}) = \mathcal{N}(\mathbf{x}_t ;\boldsymbol{\mu}_t=\sqrt{1 - \beta_t} \mathbf{x}_{t-1}, \boldsymbol{\Sigma}_t = \beta_t \mathbf{I}) \nonumber \end{equation}\]Since we are in the multi-dimensional scenario \(\textbf{I}\) is the identity matrix, indicating that each dimension has the same standard deviation \(\beta_t\).
Note that \(q(\mathbf{x}_t \vert \mathbf{x}_{t-1})\) is still a normal distribution, defined by the mean \(\boldsymbol{\mu}\) and the variance \(\boldsymbol{\Sigma}\) where \(\boldsymbol{\mu}_t =\sqrt{1 - \beta_t} \mathbf{x}_{t-1}\) and \(\boldsymbol{\Sigma}_t=\beta_t\mathbf{I}\)
\(\boldsymbol{\Sigma}\) will always be a diagonal matrix of variances (here \(\beta_t\))
Thus, we can go in a closed form from the input data \(\mathbf{x}_0\) to \(\mathbf{x}_{T}\) in a tractable way.
Mathematically, this is the posterior probability and is defined as:
\[q(\mathbf{x}_{1:T} \vert \mathbf{x}_0) = \prod^T_{t=1} q(\mathbf{x}_t \vert \mathbf{x}_{t-1})\]The symbol :: in \(q(\mathbf{x}_{1:T})\)
states that we apply q repeatedly from timestep 1 to T. It’s also called trajectory.
For timestep \(t=500 < T\) we need to apply q 500 times in order to sample \(\mathbf{x}_t\). The reparametrization trick provides a magic remedy to this.
The reparameterization trick: tractable closed-form sampling at any timestep
If we define \(\alpha_t= 1- \beta_t, \bar{\alpha}_t = \prod_{s=0}^t \alpha_s\) where \(\boldsymbol{\epsilon}_{0},..., \epsilon_{t-2}, \epsilon_{t-1} \sim \mathcal{N}(\textbf{0},\mathbf{I})\), one can use the reparameterization trick in a recursive manner to prove that:
\[\begin{aligned} \mathbf{x}_t &=\sqrt{1 - \beta_t} \mathbf{x}_{t-1} + \sqrt{\beta_t}\boldsymbol{\epsilon}_{t-1}\\ &= \sqrt{\alpha_t}\mathbf{x}_{t-2} + \sqrt{1 - \alpha_t}\boldsymbol{\epsilon}_{t-2} \\ &= \dots \\ &= \sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon_0} \end{aligned}\]Note: Since all timestep have the same Gaussian noise we will only use the symbol \(\boldsymbol{\epsilon}\) from now on.
Thus to produce a sample \(\mathbf{x}_t\)we can use the following distribution:
\[\mathbf{x}_t \sim q(\mathbf{x}_t \vert \mathbf{x}_0) = \mathcal{N}(\mathbf{x}_t; \sqrt{\bar{\alpha}_t} \mathbf{x}_0, (1 - \bar{\alpha}_t)\mathbf{I})\]Since \(\beta_t\) is a hyperparameter, we can precompute \(\alpha_t\) and \(\bar{\alpha}_t\)for all timesteps. This means that we sample noise at any timestep t and get \(\mathbf{x}_t\) in one go. Hence, we can sample our latent variable \(\mathbf{x}_t\) at any arbitrary timestep. This will be our target later on to calculate our tractable objective loss \(L_t\).
Variance schedule
The variance parameter \(\beta_t\) can be fixed to a constant or chosen as a schedule over the T timesteps. In fact, one can define a variance schedule, which can be linear, quadratic, cosine etc. The original DDPM authors utilized a linear schedule increasing from \(\beta_1= 10^{-4}\) to \(\beta_T = 0.02\) Nichol et al. 2021 showed that employing a cosine schedule works even better.
[ ]
Latent samples from linear (top) and cosine (bottom) schedules respectively. Source: Nichol & Dhariwal 2021
]
Latent samples from linear (top) and cosine (bottom) schedules respectively. Source: Nichol & Dhariwal 2021
Reverse diffusion
As \(T \to \infty\) the latent \(x_T\) is nearly an isotropic An isotropic gaussian is,\(\Sigma\) is the covariance matrix.) Gaussian distribution. Therefore if we manage to learn the reverse distribution \(q(\mathbf{x}_{t-1} \vert \mathbf{x}_{t})\), we can sample \(x_T\) from \(\mathcal{N}(0,\mathbf{I})\), run the reverse process and acquire a sample from \(q(x_0)\), generating a novel data point from the original data distribution. The question is how we can model the reverse diffusion process.
Approximating the reverse process with a neural network
In practical terms, we don’t know \(q(\mathbf{x}_{t-1} \vert \mathbf{x}_{t})\). It’s intractable since statistical estimates of \(q(\mathbf{x}_{t-1} \vert \mathbf{x}_{t})\) require computations involving the data distribution.
Instead, we approximate \(q(\mathbf{x}_{t-1} \vert \mathbf{x}_{t})\)with a parameterized model \(p_{\theta}\) (e.g. a neural network). Since \(q(\mathbf{x}_{t-1} \vert \mathbf{x}_{t})\) will also be Gaussian, for small enough \beta_t, we can choose \(p_{\theta}\) to be Gaussian and just parameterize the mean and variance:
\[p_\theta(\mathbf{x}_{t-1} \vert \mathbf{x}_t) = \mathcal{N}(\mathbf{x}_{t-1}; \boldsymbol{\mu}_\theta(\mathbf{x}_t, t), \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t))\]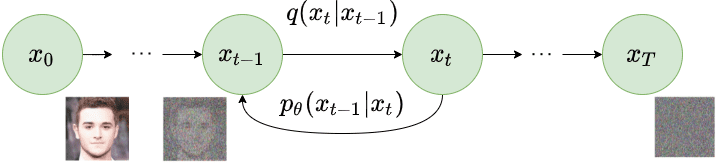
Reverse diffusion process. Image modified by Ho et al. 2020
If we apply the reverse formula for all timesteps \((p_\theta(\mathbf{x}_{0:T})\), also called trajectory), we can go from \(\mathbf{x}_T\) to the data distribution:
\[p_\theta(\mathbf{x}_{0:T}) = p_{\theta}(\mathbf{x}_T) \prod^T_{t=1} p_\theta(\mathbf{x}_{t-1} \vert \mathbf{x}_t)\]By additionally conditioning the model on timestep $t$, it will learn to predict the Gaussian parameters (meaning the mean \(\boldsymbol{\mu}_\theta(\mathbf{x}_t, t)\) and the covariance matrix \(\boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t)\) for each timestep.
But how do we train such a model?
Training a diffusion model
If we take a step back, we can notice that the combination of q and p is very similar to a variational autoencoder (VAE). Thus, we can train it by optimizing the negative log-likelihood of the training data. After a series of calculations, which we won’t analyze here, we can write the evidence lower bound (ELBO) as follows:
\[\begin{aligned} log p(\mathbf{x}) \geq &\mathbb{E}_{q(x_1 \vert x_0)} [log p_{\theta} (\mathbf{x}_0 \vert \mathbf{x}_1)] - \\ &D_{KL}(q(\mathbf{x}_T \vert \mathbf{x}_0) \vert\vert p(\mathbf{x}_T))- \\ &\sum_{t=2}^T \mathbb{E}_{q(\mathbf{x}_t \vert \mathbf{x}_0)} [D_{KL}(q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0) \vert \vert p_{\theta}(\mathbf{x}_{t-1} \vert \mathbf{x}_t)) ] \\ & = L_0 - L_T - \sum_{t=2}^T L_{t-1} \end{aligned}\]Let’s analyze these terms:
- The \(\mathbb{E}_{q(x_1 \vert x_0)} [log p_{\theta} (\mathbf{x}_0 \vert \mathbf{x}_1)]\) term can been as a reconstruction term, similar to the one in the ELBO of a variational autoencoder. In Ho et al 2020 , this term is learned using a separate decoder.
- \(D_{KL}(q(\mathbf{x}_T \vert \mathbf{x}_0) \vert\vert p(\mathbf{x}_T))\) shows how close \(\mathbf{x}_T\) is to the standard Gaussian. Note that the entire term has no trainable parameters so it’s ignored during training.
- The third term \(\sum_{t=2}^T L_{t-1}\), also referred as $L_t$, formulate the difference between the desired denoising steps \(p_{\theta}(\mathbf{x}_{t-1} \vert \mathbf{x}_t))\) and the approximated ones \(q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0)\).
It is evident that through the ELBO, maximizing the likelihood boils down to learning the denoising steps \(L_t\).
Important note: Even though \(q(\mathbf{x}_{t-1} \vert \mathbf{x}_{t})\) is intractable Sohl-Dickstein et al illustrated that by additionally conditioning on \(\textbf{x}_0\) makes it tractable.
Intuitively, a painter (our generative model) needs a reference image (\(\textbf{x}_0\)) to slowly draw (reverse diffusion step \(q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0)\) an image.
Thus, we can take a small step backwards, meaning from noise to generate an image, if and only if we have \(\textbf{x}_0\) as a reference.
In other words, we can sample \(\textbf{x}_t\) at noise level \(t\) conditioned on \(\textbf{x}_0\). Since \(\alpha_t= 1- \beta_t\) and \(\bar{\alpha}_t = \prod_{s=0}^t \alpha_s\), we can prove that:
\[\begin{aligned} q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0) &= \mathcal{N}(\mathbf{x}_{t-1}; {\tilde{\boldsymbol{\mu}}}(\mathbf{x}_t, \mathbf{x}_0), {\tilde{\beta}_t} \mathbf{I}) \\ \tilde{\beta}_t &= \frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \cdot \beta_t \\ \tilde{\boldsymbol{\mu}}_t (\mathbf{x}_t, \mathbf{x}_0) &= \frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1 - \bar{\alpha}_t} \mathbf{x_0} + \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} \mathbf{x}_t \end{aligned}\]Note that \(\alpha_t\) and \(\bar{\alpha}_t\) depend only on \(\beta_t\), so they can be precomputed.
This little trick provides us with a fully tractable ELBO. The above property has one more important side effect, as we already saw in the reparameterization trick, we can represent \(\mathbf{x}_0\)as
\(\mathbf{x}_0 = \frac{1}{\sqrt{\bar{\alpha}_t}}(\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t} \boldsymbol{\epsilon}))\),
where \(\boldsymbol{\epsilon} \sim \mathcal{N}(\textbf{0},\mathbf{I})\).
By combining the last two equations, each timestep will now have a mean \(\tilde{\boldsymbol{\mu}}_t\) (our target) that only depends on \(\mathbf{x}_t\):
\[\tilde{\boldsymbol{\mu}}_t (\mathbf{x}_t) = {\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon} ) \Big)}\]Therefore we can use a neural network \(\epsilon_{\theta}(\mathbf{x}_t,t)\) to approximate \(\boldsymbol{\epsilon}\) and consequently the mean:
\[\tilde{\boldsymbol{\mu}_{\theta}}( \mathbf{x}_t,t) = {\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon}_{\theta}(\mathbf{x}_t,t) \Big)}\]Thus, the loss function (the denoising term in the ELBO) can be expressed as:
\[\begin{aligned} L_t &= \mathbb{E}_{\mathbf{x}_0,t,\boldsymbol{\epsilon}}\Big[\frac{1}{2||\boldsymbol{\Sigma}_\theta (x_t,t)||_2^2} ||\tilde{\boldsymbol{\mu}}_t - \boldsymbol{\mu}_\theta(\mathbf{x}_t, t)||_2^2 \Big] \\ &= \mathbb{E}_{\mathbf{x}_0,t,\boldsymbol{\epsilon}}\Big[\frac{\beta_t^2}{2\alpha_t (1 - \bar{\alpha}_t) ||\boldsymbol{\Sigma}_\theta||^2_2} \| \boldsymbol{\epsilon}_{t}- \boldsymbol{\epsilon}_{\theta}(\sqrt{\bar{a}_t} \mathbf{x}_0 + \sqrt{1-\bar{a}_t}\boldsymbol{\epsilon}, t ) ||^2 \Big] \end{aligned}\]This effectively shows us that instead of predicting the mean of the distribution, the model will predict the noise \(\boldsymbol{\epsilon}\) at each timestep t.
Ho et.al 2020 made a few simplifications to the actual loss term as they ignore a weighting term. The simplified version outperforms the full objective:
\[L_t^\text{simple} = \mathbb{E}_{\mathbf{x}_0, t, \boldsymbol{\epsilon}} \Big[\|\boldsymbol{\epsilon}- \boldsymbol{\epsilon}_{\theta}(\sqrt{\bar{a}_t} \mathbf{x}_0 + \sqrt{1-\bar{a}_t} \boldsymbol{\epsilon}, t ) ||^2 \Big]\]The authors found that optimizing the above objective works better than optimizing the original ELBO. The proof for both equations can be found in this excellent post by Lillian Weng or in Luo et al. 2022.
Additionally, Ho et. al 2020 decide to keep the variance fixed and have the network learn only the mean. This was later improved by Nichol et al. 2021, who decide to let the network learn the covariance matrix $(\boldsymbol{\Sigma})$ as well (by modifying $L_t^\text{simple}$, achieving better results.
 Training and sampling algorithms of DDPMs. Source: Ho et al. 2020
Training and sampling algorithms of DDPMs. Source: Ho et al. 2020
Architecture
One thing that we haven’t mentioned so far is what the model’s architecture looks like. Notice that the model’s input and output should be of the same size.
To this end, Ho et al. employed a U-Net. If you are unfamiliar with U-Nets, feel free to check out our past article on the major U-Net architectures. In a few words, a U-Net is a symmetric architecture with input and output of the same spatial size that uses skip connections between encoder and decoder blocks of corresponding feature dimension. Usually, the input image is first downsampled and then upsampled until reaching its initial size.
In the original implementation of DDPMs, the U-Net consists of Wide ResNet blocks, group normalization as well as self-attention blocks.
The diffusion timestep t is specified by adding a sinusoidal position embedding into each residual block. For more details, feel free to visit the official GitHub repository. For a detailed implementation of the diffusion model, check out this awesome post by Hugging Face.
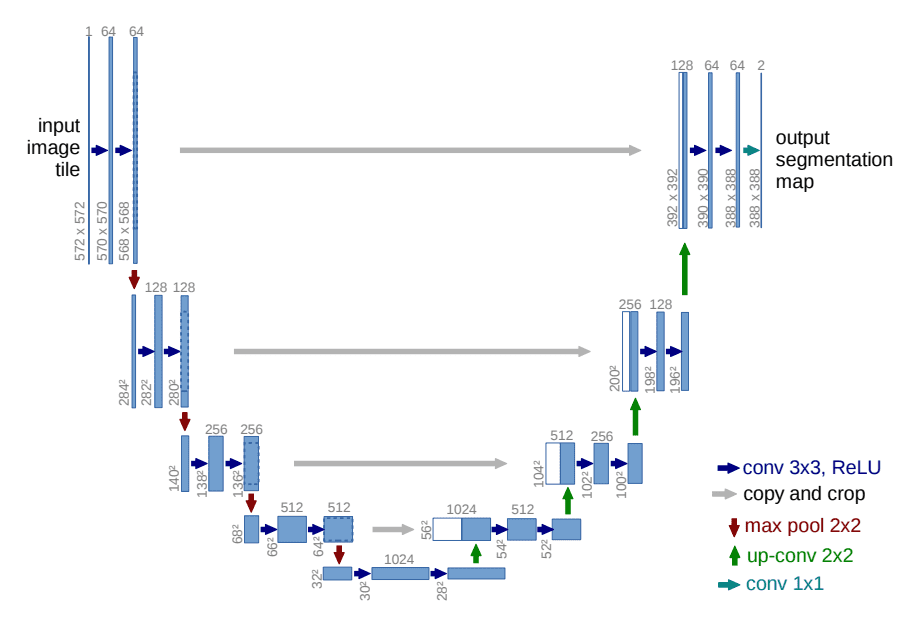
The U-Net architecture. Source: Ronneberger et al.
Conditional Image Generation: Guided Diffusion
A crucial aspect of image generation is conditioning the sampling process to manipulate the generated samples. Here, this is also referred to as guided diffusion. There have even been methods that incorporate image embeddings into the diffusion in order to guide the generation.
Mathematically, guidance refers to conditioning a prior data distribution \(p(x)\) with a condition \(y\), i.e. the class label or an image/text embedding, resulting in p(x|y).
To turn a diffusion model \(p_\theta\) into a conditional diffusion model, we can add conditioning information \(y\) at each diffusion step.
\[p_\theta(x_{0:T} \vert y) = p_\theta(x_T) \prod^T_{t=1} p_\theta(x_{t-1} \vert x_t, y)\]The fact that the conditioning is being seen at each timestep may be a good justification for the excellent samples from a text prompt. In general, guided diffusion models aim to learn
\(\nabla \log p_\theta(x_t \vert y)\).
So using the Bayes rule, we can write:
\[\begin{align*} \nabla_{x_{t}} \log p_\theta(x_t \vert y) &= \nabla_{x_{t}} \log (\frac{p_\theta(y \vert x_t) p_\theta(x_t) }{p_\theta(y)}) \\ &= \nabla_{x_{t}} log p_\theta(x_t) + \nabla_{x_{t}} log (p_\theta( y \vert x_t )) \end{align*}\]\(p_\theta(y)\) is removed since the gradient operator \(\nabla_{x_{t}}\) refers only to \(x_{t}\), so no gradient for \(y\). Moreover remember that \(\log(a b)= \log(a) + \log(b)\). And by adding a guidance scalar term \(s\), we have:
\[\nabla \log p_\theta(x_t \vert y) = \nabla \log p_\theta(x_t) + s \cdot \nabla \log (p_\theta( y \vert x_t ))\]Using this formulation, let’s make a distinction between classifier and classifier-free guidance. Next, we will present two family of methods aiming at injecting label information.
Classifier guidance
Sohl-Dickstein et al. and later Dhariwal and Nichol showed that we can use a second model, a classifier \(f_\phi(y \vert x_t, t)\), to guide the diffusion toward the target class \(y\) during training. To achieve that, we can train a classifier \(f_\phi(y \vert x_t, t)\) on the noisy image \(x_t\) to predict its class \(y\).
Then we can use the gradients \(\nabla \log (f_\phi( y \vert x_t ))\) to guide the diffusion. How?
We can build a class-conditional diffusion model with mean \(\mu_\theta (x_t|y)\) and variance \(\Sigma_\theta (x_t|y)\). Since \(p_\theta \sim \mathcal{N}(\mu_{\theta}, \Sigma_{\theta})\), we can show using the guidance formulation from the previous section that the mean is perturbed by the gradients of \(\log f_\phi(y|x_t)\) of class \(y\), resulting in: \(\hat{\mu}(x_t |y) =\mu_\theta(x_t |y) + s \cdot \boldsymbol{\Sigma}_\theta(x_t |y) \nabla_{x_t} logf_\phi(y \vert x_t, t)\)
In the famous GLIDE paper by Nichol et al, the authors expanded on this idea and use CLIP embeddings to guide the diffusion. CLIP as proposed by Saharia et al., consists of an image encoder g and a text encoder h. It produces an image and text embeddings g(x_t) and h(c), respectively, wherein c is the text caption.
Therefore, we can perturb the gradients with their dot product:
\[\hat{\mu}(x_t |c) =\mu(x_t |c) + s \cdot \boldsymbol{\Sigma}_\theta(x_t |c) \nabla_{x_t} g(x_t) \cdot h(c)\]As a result, they manage to “steer” the generation process toward a user-defined text caption.

Algorithm of classifier guided diffusion sampling. Source: Dhariwal & Nichol 2021
Classifier-free guidance
Using the same formulation as before we can define a classifier-free guided diffusion model as:
\[\nabla \log p(\mathbf{x}_t \vert y) =s \cdot \nabla log(p(\mathbf{x}_t \vert y)) + (1-s) \cdot \nabla log p(\mathbf{x}_t)\]Guidance can be achieved without a second classifier model as proposed by Ho & Salimans. Instead of training a separate classifier, the authors trained a conditional diffusion model
\[\epsilon_\theta (x_t|y)\]together with an unconditional model with simply y=0.
In fact, they use the exact same neural network. During training, they randomly set the class \(y\) to 0, so that the model is exposed to both the conditional and unconditional setup:
\[\begin{aligned} \hat{\epsilon}_\theta(x_t |y) & = s \cdot \epsilon_\theta(x_t |y) + (1-s) \cdot \epsilon_\theta(x_t |0) \\ &= \epsilon_\theta(x_t |0) + s \cdot (\epsilon_\theta(x_t |y) -\epsilon_\theta(x_t |0) ) \end{aligned}\]Note that this can also be used to “inject” text embeddings as we showed in classifier guidance.
This admittedly “weird” process has two major advantages:
- It uses only a single model to guide the diffusion.
- It simplifies guidance when conditioning on information that is difficult to predict with a classifier (such as text embeddings).
Imagen as proposed by Saharia et al. relies heavily on classifier-free guidance, as they find that it is a key contributor to generating samples with strong image-text alignment.
Scaling up diffusion models
You might be asking what is the problem with these models. Well, it’s computationally very expensive to scale these U-nets into high-resolution images. This brings us to two methods for scaling up diffusion models to higher resolutions: cascade diffusion models and latent diffusion models.
Cascade diffusion models
Ho et al. 2021 introduced cascade diffusion models in an effort to produce high-fidelity images. A cascade diffusion model consists of a pipeline of many sequential diffusion models that generate images of increasing resolution. Each model generates a sample with superior quality than the previous one by successively upsampling the image and adding higher resolution details. To generate an image, we sample sequentially from each diffusion model.
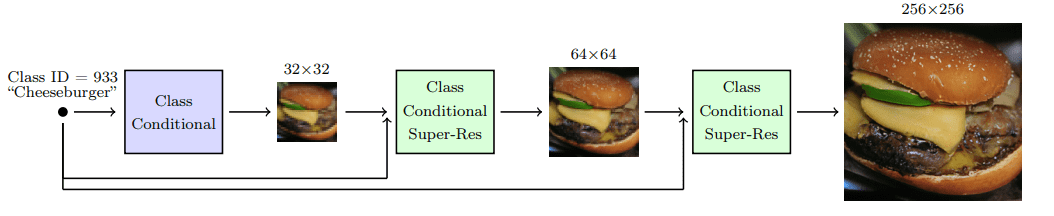 Cascade diffusion model pipeline. Source: Ho & Saharia et al.
Cascade diffusion model pipeline. Source: Ho & Saharia et al.
To acquire good results with cascaded architectures, strong data augmentations on the input of each super-resolution model are crucial. Why? Because it alleviates compounding error from the previous cascaded models, as well as due to a train-test mismatch.
It was found that gaussian blurring is a critical transformation toward achieving high fidelity. They refer to this technique as conditioning augmentation.
Stable diffusion: Latent diffusion models
Latent diffusion models are based on a rather simple idea: instead of applying the diffusion process directly on a high-dimensional input, we project the input into a smaller latent space and apply the diffusion there.
In more detail, Rombach et al. proposed to use an encoder network to encode the input into a latent representation i.e. \(\mathbf{z}_t = g(\mathbf{x}_t)\).
The intuition behind this decision is to lower the computational demands of training diffusion models by processing the input in a lower dimensional space. Afterward, a standard diffusion model (U-Net)is applied to generate new data, which are upsampled by a decoder network.
If the loss for a typical diffusion model (DM) is formulated as:
\[L_{DM} = \mathbb{E}_{\mathbf{x}, t, \boldsymbol{\epsilon}} \Big[\| \boldsymbol{\epsilon}- \boldsymbol{\epsilon}_{\theta}( \mathbf{x}_t, t ) ||^2 \Big]\]then given an encoder \mathcal{E}E and a latent representation $z$, the loss for a latent diffusion model (LDM) is:
\[L_{LDM} = \mathbb{E}_{ \mathcal{E}(\mathbf{x}), t, \boldsymbol{\epsilon}} \Big[\| \boldsymbol{\epsilon}- \boldsymbol{\epsilon}_{\theta}( \mathbf{z}_t, t ) ||^2 \Big]\]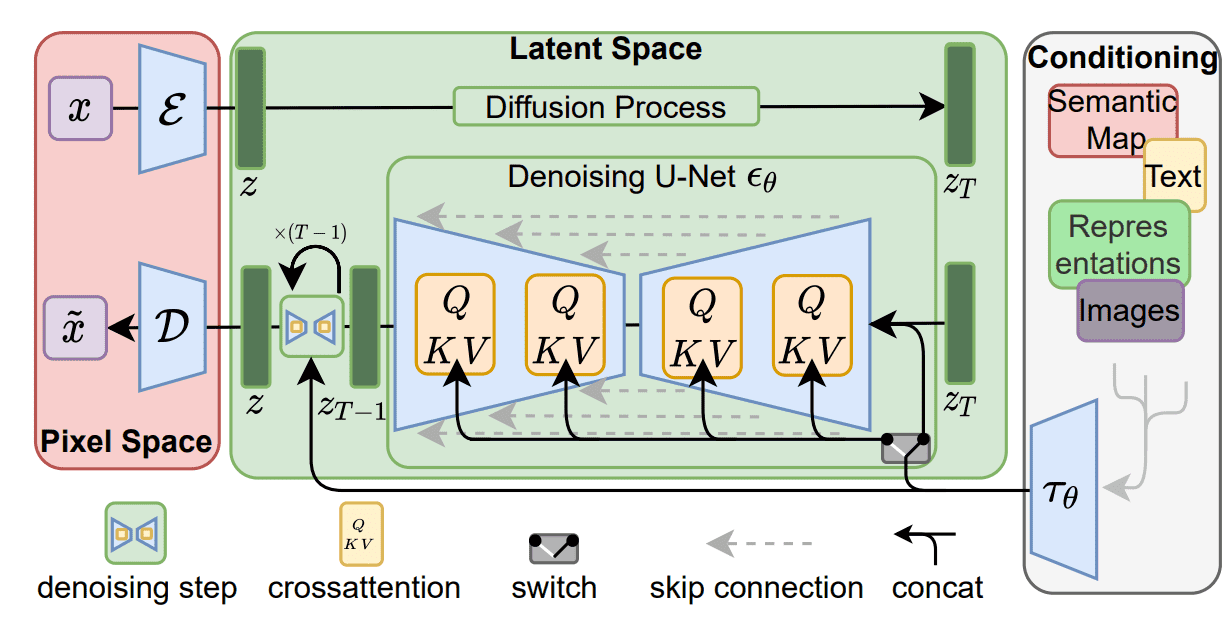 Latent diffusion models. Source: Rombach et al
Latent diffusion models. Source: Rombach et al
Score-based generative models
Around the same time as the DDPM paper, Song and Ermon proposed a different type of generative model that appears to have many similarities with diffusion models. Score-based models tackle generative learning using score matching and Langevin dynamics.
\[\mathbf{x}_t=\mathbf{x}_{t-1}+\frac{\delta}{2} \nabla_{\mathbf{x}} \log p\left(\mathbf{x}_{t-1}\right)+\sqrt{\delta} \boldsymbol{\epsilon}, \quad \text { where } \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})\]Score-matching refers to the process of modeling the gradient of the log probability density function, also known as the score function. Langevin dynamics is an iterative process that can draw samples from a distribution using only its score function.
where \(\delta\) is the step size.
Suppose that we have a probability density \(p(x)\) and that we define the score function to be \(\nabla_x \log p(x)\). We can then train a neural network \(s_{\theta}\) to estimate \(\nabla_x \log p(x)\) without estimating \(p(x)\) first. The training objective can be formulated as follows:
\[\mathbb{E}_{p(\mathbf{x})}[\| \nabla_\mathbf{x} \log p(\mathbf{x}) - \mathbf{s}_\theta(\mathbf{x}) \|_2^2] = \int p(\mathbf{x}) \| \nabla_\mathbf{x} \log p(\mathbf{x}) - \mathbf{s}_\theta(\mathbf{x}) \|_2^2 \mathrm{d}\mathbf{x}\]Then by using Langevin dynamics, we can directly sample from \(p(x)\) using the approximated score function.
In case you missed it, guided diffusion models use this formulation of score-based models as they learn directly \(\nabla_x \log p(x)\). Of course, they don’t rely on Langevin dynamics.
Adding noise to score-based models: Noise Conditional Score Networks (NCSN)
The problem so far: the estimated score functions are usually inaccurate in low-density regions, where few data points are available. As a result, the quality of data sampled using Langevin dynamics is not good.
Their solution was to perturb the data points with noise and train score-based models on the noisy data points instead. As a matter of fact, they used multiple scales of Gaussian noise perturbations. Thus, adding noise is the key to make both DDPM and score based models work.
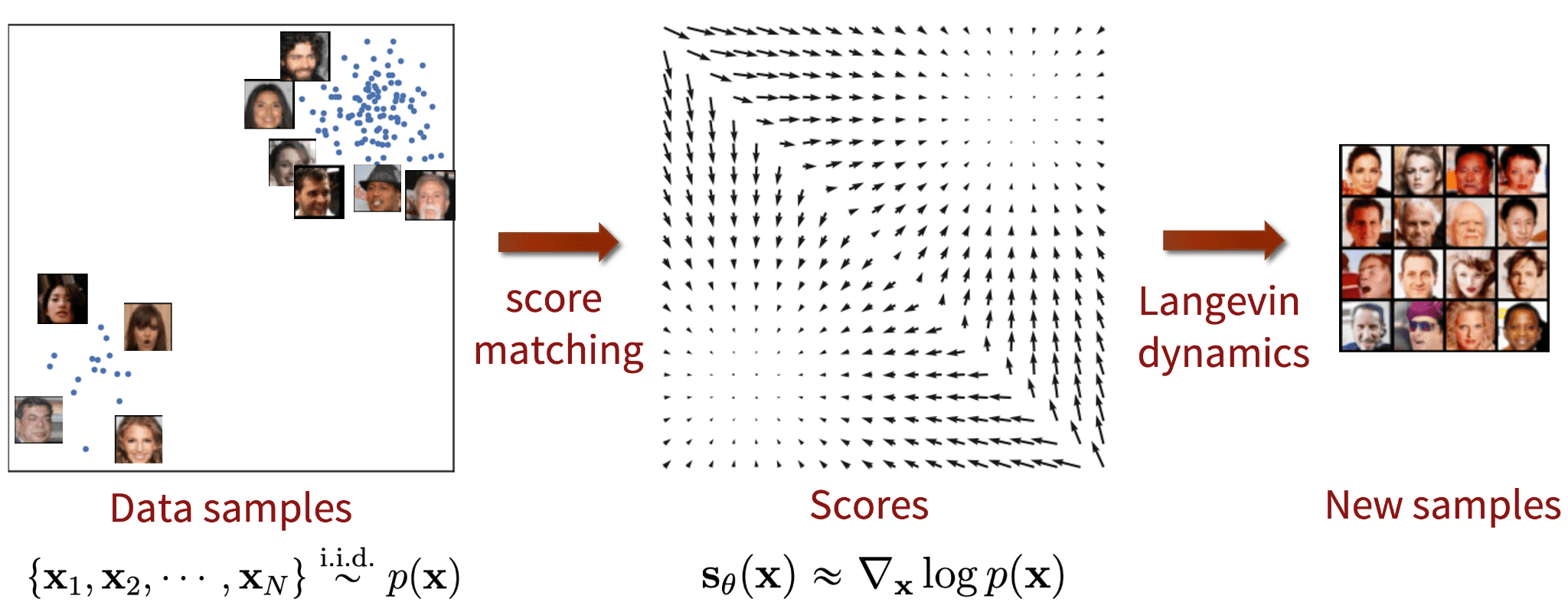 Score-based generative modeling with score matching + Langevin dynamics. Source: Generative Modeling by Estimating Gradients of the Data Distribution
Score-based generative modeling with score matching + Langevin dynamics. Source: Generative Modeling by Estimating Gradients of the Data Distribution
Mathematically, given the data distribution \(p(x)\), we perturb with Gaussian noise \(\mathcal{N}(\textbf{0}, \sigma_i^2 I)\) to obtain a noise-perturbed distribution:
\[p_{\sigma_i}(\mathbf{x}) = \int p(\mathbf{y}) \mathcal{N}(\mathbf{x}; \mathbf{y}, \sigma_i^2 I) \mathrm{d} \mathbf{y}\]Then we train a network \(s_\theta(\mathbf{x},i)\), known as Noise Conditional Score-Based Network (NCSN) to estimate the score function \(\nabla_\mathbf{x} \log d_{\sigma_i}(\mathbf{x})\). The training objective is a weighted sum of Fisher divergences for all noise scales.
\[\sum_{i=1}^L \lambda(i) \mathbb{E}_{p_{\sigma_i}(\mathbf{x})}[\| \nabla_\mathbf{x} \log p_{\sigma_i}(\mathbf{x}) - \mathbf{s}_\theta(\mathbf{x}, i) \|_2^2]\]Score-based generative modeling through stochastic differential equations (SDE)
Song et al. 2021 explored the connection of score-based models with diffusion models. In an effort to encapsulate both NSCNs and DDPMs under the same umbrella, they proposed the following:
Instead of perturbing data with a finite number of noise distributions, we use a continuum of distributions that evolve over time according to a diffusion process. This process is modeled by a prescribed stochastic differential equation (SDE) that does not depend on the data and has no trainable parameters. By reversing the process, we can generate new samples.
 Score-based generative modeling through stochastic differential equations (SDE). Source: Song et al. 2021
Score-based generative modeling through stochastic differential equations (SDE). Source: Song et al. 2021
We can define the diffusion process \(\{ \mathbf{x}(t) \}_{t\in [0, T]}\) as an SDE in the following form:
\[\mathrm{d}\mathbf{x} = \mathbf{f}(\mathbf{x}, t) \mathrm{d}t + g(t) \mathrm{d} \mathbf{w}\]where \(\mathbf{w}\) is the Wiener process (a.k.a., Brownian motion), \(\mathbf{f}(\cdot, t)\) is a vector-valued function called the drift coefficient of \(\mathbf{x}(t)\), and \(g(\cdot)\) is a scalar function known as the diffusion coefficient of \(\mathbf{x}(t)\). Note that the SDE typically has a unique strong solution.
To make sense of why we use an SDE, here is a tip: the SDE is inspired by the Brownian motion, in which a number of particles move randomly inside a medium. This randomness of the particles’ motion models the continuous noise perturbations on the data.
After perturbing the original data distribution for a sufficiently long time, the perturbed distribution becomes close to a tractable noise distribution. To generate new samples, we need to reverse the diffusion process. The SDE was chosen to have a corresponding reverse SDE in closed form:
\[\mathrm{d}\mathbf{x} = [\mathbf{f}(\mathbf{x}, t) - g^2(t) \nabla_\mathbf{x} \log p_t(\mathbf{x})]\mathrm{d}t + g(t) \mathrm{d} \mathbf{w}\]To compute the reverse SDE, we need to estimate the score function \(\nabla_\mathbf{x} \log p_t(\mathbf{x})\).
This is done using a score-based model \(s_\theta(\mathbf{x},i)\) and Langevin dynamics. The training objective is a continuous combination of Fisher divergences:
\[\mathbb{E}_{t \in \mathcal{U}(0, T)}\mathbb{E}_{p_t(\mathbf{x})}[\lambda(t) \| \nabla_\mathbf{x} \log p_t(\mathbf{x}) - \mathbf{s}_\theta(\mathbf{x}, t) \|_2^2]\]where \(\mathcal{U}(0, T)\) denotes a uniform distribution over the time interval, and $\lambda$ is a positive weighting function. Once we have the score function, we can plug it into the reverse SDE and solve it in order to sample \(\mathbf{x}(0)\) from the original data distribution \(p_0(\mathbf{x})\).
There are a number of options to solve the reverse SDE which we won’t analyze here. Make sure to check the original paper or this excellent blog post by the author.
 Overview of score-based generative modeling through SDEs. Source: Song et al. 2021
Overview of score-based generative modeling through SDEs. Source: Song et al. 2021
Summary
Let’s do a quick sum-up of the main points we learned in this blogpost:
- Diffusion models work by gradually adding gaussian noise through a series of \(T\) steps into the original image, a process known as diffusion.
- To sample new data, we approximate the reverse diffusion process using a neural network.
- The training of the model is based on maximizing the evidence lower bound (ELBO).
- We can condition the diffusion models on image labels or text embeddings in order to “guide” the diffusion process.
- Cascade and Latent diffusion are two approaches to scale up models to high-resolutions.
- Cascade diffusion models are sequential diffusion models that generate images of increasing resolution.
- Latent diffusion models (like stable diffusion) apply the diffusion process on a smaller latent space for computational efficiency using a variational autoencoder for the up and downsampling.
- Score-based models also apply a sequence of noise perturbations to the original image. But they are trained using score-matching and Langevin dynamics. Nonetheless, they end up in a similar objective.
- The diffusion process can be formulated as an SDE. Solving the reverse SDE allows us to generate new samples.
Finally, for more associations between diffusion models and VAE or AE check out these really nice blogs.
Application Example
Step 1. Installation of the libraries.
In this project we require a computer with GPU, for this reason we can work in AWS SageMaker Notebook, then you simply click File>New>Terminal and type
wget https://raw.githubusercontent.com/ruslanmv/Diffusion-Models-in-Machine-Learning/master/setup.sh
and type
sh setup.sh
and skip the next step.
Otherwise if you are working locally, clone the following repository
git clone https://github.com/ruslanmv/Diffusion-Models-in-Machine-Learning.git
then
cd Diffusion-Models-in-Machine-Learning
Step 2. Creation of the environment
You can install miniconda at this link in your personal computer.
we create an environment called diffusion, but you can put the name that you like.
conda create -n diffusion python==3.8 jupyter -y
If you are running anaconda for first time, you should init conda with the shell that you want to work, in this case I choose the cmd.exe
conda init cmd.exe
and then close and open the terminal
conda activate diffusion
then in your terminal type the following commands:
conda install ipykernel -y
python -m ipykernel install --user --name diffusion --display-name "Python (diffusion)"
In this project we are going to use the following libraries:
- PyTorch
- PyTorch-Lightning
- Torchvision
- imageio (for gif generation)
pip install torch pytorch_lightning imageio torchvision
Step 3
Use the provided entry-MNIST.ipynb notebook to train model and sample generated images.
That supports MNIST, Fashion-MNIST and CIFAR datasets.
Then you select the Kernel Python (diffusion)
And you can run the notebook.
Denoising Diffusion Probabilistic Models
import torch
from data import DiffSet
import pytorch_lightning as pl
from model import DiffusionModel
from torch.utils.data import DataLoader
import imageio
import glob
!nvidia-smi
Sun Oct 9 12:19:32 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.47.03 Driver Version: 510.47.03 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
| N/A 73C P0 65W / 70W | 4285MiB / 15360MiB | 92% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 12561 C ...envs/diffusion/bin/python 4283MiB |
+-----------------------------------------------------------------------------+
Set model parameters
# Training hyperparameters
diffusion_steps = 1000
#dataset_choice = "CIFAR"
dataset_choice = "MNIST"
#dataset_choice = "Fashion"
max_epoch = 10
batch_size = 128
# Loading parameters
load_model = False
load_version_num = 1
Load dataset and train model
# Code for optionally loading model
pass_version = None
last_checkpoint = None
if load_model:
pass_version = load_version_num
last_checkpoint = glob.glob(
f"./lightning_logs/{dataset_choice}/version_{load_version_num}/checkpoints/*.ckpt"
)[-1]
# Create datasets and data loaders
train_dataset = DiffSet(True, dataset_choice)
val_dataset = DiffSet(False, dataset_choice)
train_loader = DataLoader(train_dataset, batch_size=batch_size, num_workers=4, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, num_workers=4, shuffle=True)
# Create model and trainer
if load_model:
model = DiffusionModel.load_from_checkpoint(last_checkpoint, in_size=train_dataset.size*train_dataset.size, t_range=diffusion_steps, img_depth=train_dataset.depth)
else:
model = DiffusionModel(train_dataset.size*train_dataset.size, diffusion_steps, train_dataset.depth)
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to ./data/MNIST/raw/train-images-idx3-ubyte.gz
100%|██████████| 9912422/9912422 [00:00<00:00, 195221378.17it/s]
Extracting ./data/MNIST/raw/train-images-idx3-ubyte.gz to ./data/MNIST/raw
# Load Trainer model
tb_logger = pl.loggers.TensorBoardLogger(
"lightning_logs/",
name=dataset_choice,
version=pass_version,
)
trainer = pl.Trainer(
max_epochs=max_epoch,
log_every_n_steps=10,
gpus=1,
auto_select_gpus=True,
resume_from_checkpoint=last_checkpoint,
logger=tb_logger
)
/home/ec2-user/anaconda3/envs/diffusion/lib/python3.8/site-packages/pytorch_lightning/trainer/connectors/accelerator_connector.py:447: LightningDeprecationWarning: Setting `Trainer(gpus=1)` is deprecated in v1.7 and will be removed in v2.0. Please use `Trainer(accelerator='gpu', devices=1)` instead.
rank_zero_deprecation(
Auto select gpus: [0]
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
# Train model
trainer.fit(model, train_loader, val_loader)
Missing logger folder: lightning_logs/MNIST
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
--------------------------------------
0 | inc | DoubleConv | 37.7 K
1 | down1 | Down | 295 K
2 | down2 | Down | 1.2 M
3 | down3 | Down | 2.4 M
4 | up1 | Up | 6.2 M
5 | up2 | Up | 1.5 M
6 | up3 | Up | 406 K
7 | outc | OutConv | 65
8 | sa1 | SAWrapper | 395 K
9 | sa2 | SAWrapper | 395 K
10 | sa3 | SAWrapper | 99.6 K
--------------------------------------
12.9 M Trainable params
0 Non-trainable params
12.9 M Total params
51.676 Total estimated model params size (MB)
Epoch 9: 100%|██████████| 548/548 [02:33<00:00, 3.57it/s, loss=0.0211, v_num=0]
Sample from model
gif_shape = [3, 3]
sample_batch_size = gif_shape[0] * gif_shape[1]
n_hold_final = 10
# Generate samples from denoising process
gen_samples = []
x = torch.randn((sample_batch_size, train_dataset.depth, train_dataset.size, train_dataset.size))
sample_steps = torch.arange(model.t_range-1, 0, -1)
for t in sample_steps:
x = model.denoise_sample(x, t)
if t % 50 == 0:
gen_samples.append(x)
for _ in range(n_hold_final):
gen_samples.append(x)
gen_samples = torch.stack(gen_samples, dim=0).moveaxis(2, 4).squeeze(-1)
gen_samples = (gen_samples.clamp(-1, 1) + 1) / 2
# Process samples and save as gif
gen_samples = (gen_samples * 255).type(torch.uint8)
gen_samples = gen_samples.reshape(-1, gif_shape[0], gif_shape[1], train_dataset.size, train_dataset.size, train_dataset.depth)
def stack_samples(gen_samples, stack_dim):
gen_samples = list(torch.split(gen_samples, 1, dim=1))
for i in range(len(gen_samples)):
gen_samples[i] = gen_samples[i].squeeze(1)
return torch.cat(gen_samples, dim=stack_dim)
gen_samples = stack_samples(gen_samples, 2)
gen_samples = stack_samples(gen_samples, 2)
imageio.mimsave(
f"{trainer.logger.log_dir}/pred.gif",
list(gen_samples),
fps=5,
)
from IPython.display import Markdown as md
gif=f"{trainer.logger.log_dir}/pred.gif"
md(""%(gif))
The results for MNIST:

CIFAR:

Fashion-MNIST:

Denoising Diffusion Probabilistic Model, in Pytorch
 </img>
</img>
Implementation of Denoising Diffusion Probabilistic Model in Pytorch. It is a new approach to generative modeling that may have the potential to rival GANs. It uses denoising score matching to estimate the gradient of the data distribution, followed by Langevin sampling to sample from the true distribution.
Install
$ pip install denoising_diffusion_pytorch
Usage
import torch
from denoising_diffusion_pytorch import Unet, GaussianDiffusion
model = Unet(
dim = 64,
dim_mults = (1, 2, 4, 8)
)
diffusion = GaussianDiffusion(
model,
image_size = 128,
timesteps = 1000, # number of steps
loss_type = 'l1' # L1 or L2
)
training_images = torch.randn(8, 3, 128, 128) # images are normalized from 0 to 1
loss = diffusion(training_images)
loss.backward()
# after a lot of training
sampled_images = diffusion.sample(batch_size = 4)
sampled_images.shape # (4, 3, 128, 128)
Or, if you simply want to pass in a folder name and the desired image dimensions, you can use the Trainer class to easily train a model.
from denoising_diffusion_pytorch import Unet, GaussianDiffusion, Trainer
model = Unet(
dim = 64,
dim_mults = (1, 2, 4, 8)
).cuda()
diffusion = GaussianDiffusion(
model,
image_size = 128,
timesteps = 1000, # number of steps
sampling_timesteps = 250, # number of sampling timesteps (using ddim for faster inference [see citation for ddim paper])
loss_type = 'l1' # L1 or L2
).cuda()
trainer = Trainer(
diffusion,
'path/to/your/images',
train_batch_size = 32,
train_lr = 8e-5,
train_num_steps = 700000, # total training steps
gradient_accumulate_every = 2, # gradient accumulation steps
ema_decay = 0.995, # exponential moving average decay
amp = True # turn on mixed precision
)
trainer.train()
Samples and model checkpoints will be logged to ./results periodically.
Troubleshootings
If you want uninstall you enviroment
conda env remove -n diffusion
List all kernels and grap the name of the kernel you want to remove
jupyter kernelspec list
Remove it
jupyter kernelspec remove diffusion
References can be found here.
Congratulations! We have learned Diffusion Models from zero.
Leave a comment