
Video Speech Generator from YouTube with AI (Text-to-Video Lip-Sync)
Hello everyone, today we are going to build an interesting application that creates video messages from Youtube Videos.
A simple application that replaces the original speech of the video from your input text. The program tries to clone the original voice and replace it with your new speech and the libs of the mouth are synchronized with Machine Learning.
For example, by taking one Youtube Video, like King Charles III like this:
we can transform it into a new video, where you say the following:
I am clonning your voice. Charles!. Machine intelligence is the last invention that humanity will ever need to make.
with this program you got the following results:
The application that we will create will be on hosted on Amazon Web Services (AWS) , in ordering to to perform the calculations
We are going to use SageMaker Notebook to create this application.
There are two versions of this app.
- The notebook version (.ipynb ) that is the extended version that we are going to see first,
- The python version (.py) that is the simplified version.
We are going to discuss the extended version to understand how things were done.
The web app that we want to to create is like this:
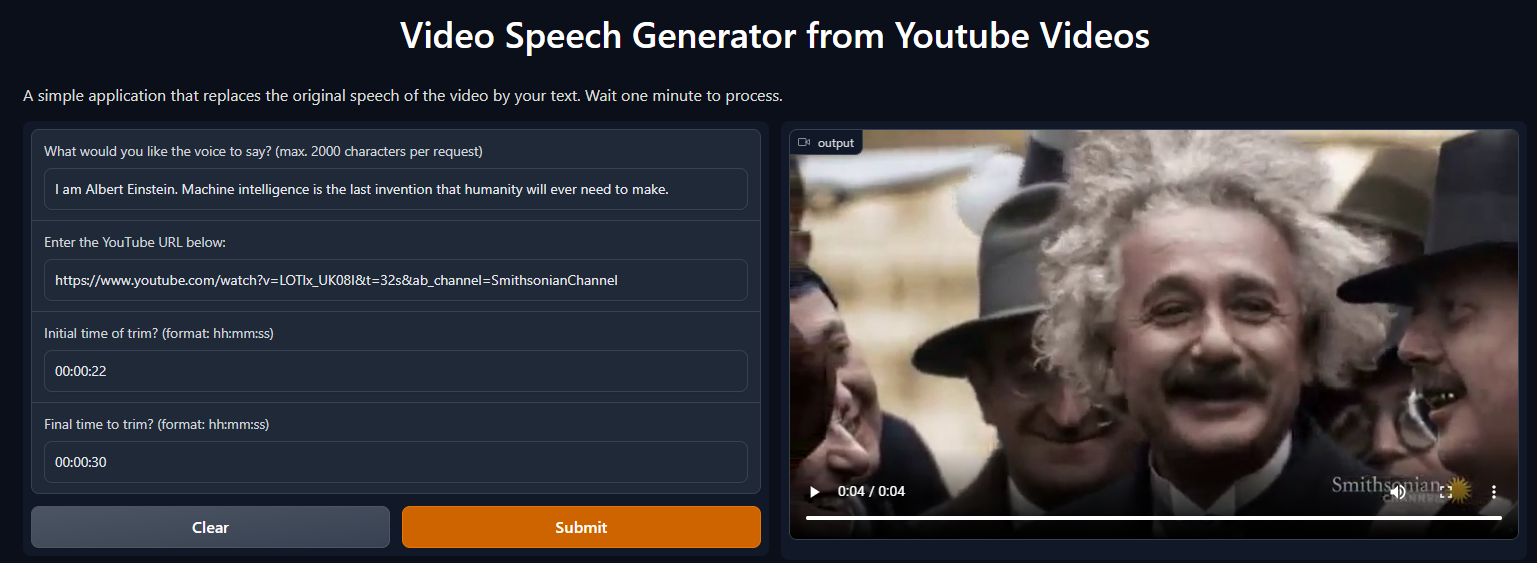
where you can make Albert Einstein speak about machine learning
or even Mark Zuckerberg.
Step 1 - Cloning the repository
You should login to AWS account and create a SageMaker Notebook, as was explained in the previous blog: How-to-run-WebApp-on-SageMaker-Notebook. For this project I have used ml.g4dn.4xlarge instances and we open a new terminal File>New> Terminal.
Then in the terminal, we clone the repository, and type the following
git clone https://github.com/ruslanmv/Video-Speech-Generator-from-Youtube.git
then enter to the directory
cd Video-Speech-Generator-from-Youtube
Step 2 - Environment setup
First, we need to install the environment to this application, which will be VideoMessage, which will be executed on python=3.7.13 and it is required ffmpeg and git-lfs.
To do this task. open a terminal and type:
sh-4.2$ sh install.sh
after it is done, you will get something like
You can open the Video-Message-Generator.ipynb notebook and choose the kernel VideoMessage.
Step 3 - Definition of variables.
In order to begin the construction of the application, we require to manage well the environments of this Cloud Service. We can import the module sys and determine which environment we are using.
import sys ,os
print(sys.prefix)
/home/ec2-user/anaconda3/envs/VideoMessage
However, to install and import modules to our environment from the terminal we should be careful because Sagemaker runs on its own container, and we have to load properly the environment that we have created.
Sagemaker = True
if Sagemaker :
env='source activate python3 && conda activate VideoMessage &&'
else:
env=''
Step 4. Setup of the dependencies
We are going to install the dependencies of our custom program.
We will use the model Wav2Lip to synchronize the speech to the video.
Due to we are going to install it for the first time, we define True otherwise False
is_first_time = True
#Install dependency
# Download pretrained model
# Import the os module
import os
# Get the current working directory
parent_dir = os.getcwd()
print(parent_dir)
if is_first_time:
# Directory
directory = "sample_data"
# Path
path = os.path.join(parent_dir, directory)
print(path)
try:
os.mkdir(path)
print("Directory '% s' created" % directory)
except Exception:
print("Directory '% s'was already created" % directory)
os.system('git clone https://github.com/Rudrabha/Wav2Lip')
os.system('cd Wav2Lip &&{} pip install -r requirements.txt'.format(env))
After the cell was executed, several modules will be installed:
Looking in indexes: https://pypi.org/simple, https://pip.repos.neuron.amazonaws.com
Collecting librosa==0.7.0
Downloading librosa-0.7.0.tar.gz (1.6 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.6/1.6 MB 24.4 MB/s eta 0:00:00
Preparing metadata (setup.py): started
Preparing metadata (setup.py): finished with status 'done'
.
.
.
Successfully built librosa audioread
Installing collected packages: llvmlite, tqdm, threadpoolctl, pycparser, pillow, numpy, joblib, audioread, torch, scipy, opencv-python, opencv-contrib-python, numba, cffi, torchvision, soundfile, scikit-learn, resampy, librosa
Successfully installed audioread-3.0.0 cffi-1.15.1 joblib-1.1.0 librosa-0.7.0 llvmlite-0.31.0 numba-0.48.0 numpy-1.17.1 opencv-contrib-python-4.6.0.66 opencv-python-4.1.0.25 pillow-9.2.0 pycparser-2.21 resampy-0.3.1 scikit-learn-1.0.2 scipy-1.7.3 soundfile-0.10.3.post1 threadpoolctl-3.1.0 torch-1.1.0 torchvision-0.3.0 tqdm-4.45.0
Then we require to download some pre-trained models that use Wav2Lip.
from utils.default_models import ensure_default_models
from pathlib import Path
## Load the models one by one.
print("Preparing the models of Wav2Lip")
ensure_default_models(Path("Wav2Lip"))
Preparing the models of Wav2Lip
Wav2Lip/checkpoints/wav2lip_gan.pth
Wav2Lip/face_detection/detection/sfd/s3fd.pth
After this, we require another program that will synthesize the voice from your text. We are going to use the Coqui-TTS that is needed for the generation of voice.
if is_first_time:
os.system('git clone https://github.com/Edresson/Coqui-TTS -b multilingual-torchaudio-SE TTS')
os.system('{} pip install -q -e TTS/'.format(env))
os.system('{} pip install -q torchaudio==0.9.0'.format(env))
os.system('{} pip install -q youtube-dl'.format(env))
os.system('{} pip install ffmpeg-python'.format(env))
os.system('{} pip install gradio==3.0.4'.format(env))
os.system('{} pip install pytube==12.1.0'.format(env))
then we load the repositories
#this code for recording audio
from IPython.display import HTML, Audio
from base64 import b64decode
import numpy as np
from scipy.io.wavfile import read as wav_read
import io
import ffmpeg
from pytube import YouTube
import random
from subprocess import call
import os
from IPython.display import HTML
from base64 import b64encode
from IPython.display import clear_output
from datetime import datetime
If the previous modules are loaded, then we have completed the first part of the setup of dependencies.
Step 5. Definition de modules used in this program
To manage all the information that contains our web application we require to create some helper functions,
def showVideo(path):
mp4 = open(str(path),'rb').read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
return HTML("""
<video width=700 controls>
<source src="%s" type="video/mp4">
</video>
""" % data_url)
def time_between(t1, t2):
FMT = '%H:%M:%S'
t1 = datetime.strptime(t1, FMT)
t2 = datetime.strptime(t2, FMT)
delta = t2 - t1
return str(delta)
In order to check that works
time_between("00:00:01","00:00:10" )
the result is ok.
'0:00:09'
The next step is to create the module to download videos from YouTube, I have defined two versions, one given by pytube and the other youtube-dl
def download_video(url):
print("Downloading...")
local_file = (
YouTube(url)
.streams.filter(progressive=True, file_extension="mp4")
.first()
.download(filename="youtube{}.mp4".format(random.randint(0, 10000)))
)
print("Downloaded")
return local_file
def download_youtube(url):
#Select a Youtube Video
#find youtube video id
from urllib import parse as urlparse
url_data = urlparse.urlparse(url)
query = urlparse.parse_qs(url_data.query)
YOUTUBE_ID = query["v"][0]
url_download ="https://www.youtube.com/watch?v={}".format(YOUTUBE_ID)
# download the youtube with the given ID
os.system("{} youtube-dl -f mp4 --output youtube.mp4 '{}'".format(env,url_download))
the difference is that youtube-dl takes too much time and can be used to download YouTube videos with higher quality but I prefer, for now, better performance. We can test both modules.
if is_first_time:
URL = 'https://www.youtube.com/watch?v=xw5dvItD5zY'
#URL = 'https://www.youtube.com/watch?v=uIaY0l5qV0c'
#download_youtube(URL)
download_video(URL)
Downloading...
Downloaded
Then we need to define some modules to clean our files.
def cleanup():
import pathlib
import glob
types = ('*.mp4','*.mp3', '*.wav') # the tuple of file types
#Finding mp4 and wave files
junks = []
for files in types:
junks.extend(glob.glob(files))
try:
# Deleting those files
for junk in junks:
print("Deleting",junk)
# Setting the path for the file to delete
file = pathlib.Path(junk)
# Calling the unlink method on the path
file.unlink()
except Exception:
print("I cannot delete the file because it is being used by another process")
def clean_data():
# importing all necessary libraries
import sys, os
# initial directory
home_dir = os.getcwd()
# some non existing directory
fd = 'sample_data/'
# Join various path components
path_to_clean=os.path.join(home_dir,fd)
print("Path to clean:",path_to_clean)
# trying to insert to false directory
try:
os.chdir(path_to_clean)
print("Inside to clean", os.getcwd())
cleanup()
# Caching the exception
except:
print("Something wrong with specified\
directory. Exception- ", sys.exc_info())
# handling with finally
finally:
print("Restoring the path")
os.chdir(home_dir)
print("Current directory is-", os.getcwd())
The next step is to define a program that will trim the YouTube videos.
def youtube_trim(url,start,end):
#cancel previous youtube
cleanup()
#download youtube
#download_youtube(url) # with youtube-dl (slow)
input_videos=download_video(url)
# Get the current working directory
parent_dir = os.getcwd()
# Trim the video (start, end) seconds
start = start
end = end
#Note: the trimmed video must have face on all frames
interval = time_between(start, end)
trimmed_video= parent_dir+'/sample_data/input_video.mp4'
trimmed_audio= parent_dir+'/sample_data/input_audio.mp3'
#delete trimmed if already exits
clean_data()
# cut the video
call(["ffmpeg","-y","-i",input_videos,"-ss", start,"-t",interval,"-async","1",trimmed_video])
# cut the audio
call(["ffmpeg","-i",trimmed_video, "-q:a", "0", "-map","a",trimmed_audio])
#Preview trimmed video
print("Trimmed Video+Audio")
return trimmed_video, trimmed_audio
Step 7- Simple check of pandas and NumPy versions
print("In our enviroment")
os.system('{} pip show pandas numpy'.format(env))
In our enviroment
Name: pandas
Version: 1.3.5
Summary: Powerful data structures for data analysis, time series, and statistics
Home-page: https://pandas.pydata.org
Author: The Pandas Development Team
Author-email: [email protected]
License: BSD-3-Clause
Location: /home/ec2-user/anaconda3/envs/VideoMessage/lib/python3.7/site-packages
Requires: numpy, python-dateutil, pytz
Required-by: gradio, TTS
---
Name: numpy
Version: 1.19.5
Summary: NumPy is the fundamental package for array computing with Python.
Home-page: https://www.numpy.org
Author: Travis E. Oliphant et al.
Author-email:
License: BSD
Location: /home/ec2-user/anaconda3/envs/VideoMessage/lib/python3.7/site-packages
Requires:
Required-by: gradio, librosa, matplotlib, numba, opencv-contrib-python, opencv-python, pandas, resampy, scikit-learn, scipy, tensorboardX, torchvision, TTS, umap-learn
I need to select a custom version of OpenCV.
if is_first_time:
os.system('{} pip install opencv-contrib-python-headless==4.1.2.30'.format(env))
Step 8 - Libraries for voice recognition
We need to clone the voice from the YouTube clip, in order to reproduce the most real possible speech.
import sys
VOICE_PATH = "utils/"
# add libraries into environment
sys.path.append(VOICE_PATH) # set this if VOICE is not installed globally
Finally, we will import the last dependency with the following ::
from utils.voice import *
If was imported, then we have loaded all the essential modules required to run this program. The next step is the creation of the main program .
Step 9 - Video creation
In this part, we extract the trimmed audio and video, from the trimmed audio we extract the embeddings of the original sound, and decode and encode the sound by using our input text. Then from this new sound spectrum, we detect all the faces of the trimmed video clip, and then replaced it with a new mouth that is synchronized with the new sound spectrum. In a few words, we replace the original sound speech with the cloned voice in the new video.
def create_video(Text,Voicetoclone):
out_audio=greet(Text,Voicetoclone)
current_dir=os.getcwd()
clonned_audio = os.path.join(current_dir, out_audio)
#Start Crunching and Preview Output
#Note: Only change these, if you have to
pad_top = 0#@param {type:"integer"}
pad_bottom = 10#@param {type:"integer"}
pad_left = 0#@param {type:"integer"}
pad_right = 0#@param {type:"integer"}
rescaleFactor = 1#@param {type:"integer"}
nosmooth = False #@param {type:"boolean"}
out_name ="result_voice.mp4"
out_file="../"+out_name
if nosmooth == False:
is_command_ok = os.system('{} cd Wav2Lip && python inference.py --checkpoint_path checkpoints/wav2lip_gan.pth --face "../sample_data/input_video.mp4" --audio "../out/clonned_audio.wav" --outfile {} --pads {} {} {} {} --resize_factor {}'.format(env,out_file,pad_top ,pad_bottom ,pad_left ,pad_right ,rescaleFactor))
else:
is_command_ok = os.system('{} cd Wav2Lip && python inference.py --checkpoint_path checkpoints/wav2lip_gan.pth --face "../sample_data/input_video.mp4" --audio "../out/clonned_audio.wav" --outfile {} --pads {} {} {} {} --resize_factor {} --nosmooth'.format(env,out_file,pad_top ,pad_bottom ,pad_left ,pad_right ,rescaleFactor))
if is_command_ok > 0:
print("Error : Ensure the video contains a face in all the frames.")
out_file="./demo/tryagain1.mp4"
return out_file
else:
print("OK")
#clear_output()
print("Creation of Video done")
return out_name
Step 10 - Test trimmed video
Now that we have finished writing all the pieces of the program, let’s choose one example video, from The King’s Speech: King Charles III, we trim the video,
URL = 'https://www.youtube.com/watch?v=xw5dvItD5zY'
#Testing first time
trimmed_video, trimmed_audio=youtube_trim(URL,"00:00:01","00:00:10")
showVideo(trimmed_video)
Trimmed Video+Audio
size= 165kB time=00:00:09.01 bitrate= 150.2kbits/s speed=76.7x
video:0kB audio:165kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.210846%
Step 11 - Add text + cloned voice + lib motion
From the trimmed video The King’s Speech: King Charles III we process everything together.
Text=' I am clonning your voice. Charles!. Machine intelligence is the last invention that humanity will ever need to make.'
Voicetoclone=trimmed_audio
print(Voicetoclone)
#Testing first time
outvideo=create_video(Text,Voicetoclone)
#Preview output video
print("Final Video Preview")
final_video= parent_dir+'/'+outvideo
print("Dowload this video from", final_video)
showVideo(final_video)
During its creation, it was created the synthesized sound
/home/ec2-user/SageMaker/VideoMessageGen/sample_data/input_audio.mp3
path url
/home/ec2-user/SageMaker/VideoMessageGen/sample_data/input_audio.mp3
> text: I am clonning your voice. Charles!. Machine intelligence is the last invention that humanity will ever need to make.
Generated Audio
in the following path:
> Saving output to out/clonned_audio.wav
then it was created the video
Using cuda for inference.
Reading video frames...
Number of frames available for inference: 225
(80, 605)
Length of mel chunks: 186
Load checkpoint from: checkpoints/wav2lip_gan.pth
Model loaded
OK
Creation of Video done
Final Video Preview
Dowload this video from /home/ec2-user/SageMaker/VideoMessageGen/result_voice.mp4
Step 12 - Creation of modules for the quality control
Here we create the modules needed for the web application.
def time_format_check(input1):
timeformat = "%H:%M:%S"
try:
validtime = datetime.strptime(input1, timeformat)
print("The time format is valid", input1)
#Do your logic with validtime, which is a valid format
return False
except ValueError:
print("The time {} has not valid format hh:mm:ss".format(input1))
return True
We need to count the time in seconds, so we define the following
def to_seconds(datetime_obj):
from datetime import datetime
time =datetime_obj
date_time = datetime.strptime(time, "%H:%M:%S")
a_timedelta = date_time - datetime(1900, 1, 1)
seconds = a_timedelta.total_seconds()
return seconds
and finally, we require to define the YouTube URL validator
def validate_youtube(url):
#This creates a youtube objet
try:
yt = YouTube(url)
except Exception:
print("Hi there URL seems invalid")
return True, 0
#This will return the length of the video in sec as an int
video_length = yt.length
if video_length > 600:
print("Your video is larger than 10 minutes")
return True, video_length
else:
print("Your video is less than 10 minutes")
return False, video_length
Step 13 - Creation of the main module
The following function give us the the final video.
def video_generator(text_to_say,url,initial_time,final_time):
print('Checking the url',url)
check1, video_length = validate_youtube(url)
if check1 is True: return "./demo/tryagain2.mp4"
check2 = validate_time(initial_time,final_time, video_length)
if check2 is True: return "./demo/tryagain0.mp4"
trimmed_video, trimmed_audio=youtube_trim(url,initial_time,final_time)
voicetoclone=trimmed_audio
print(voicetoclone)
outvideo=create_video(text_to_say,voicetoclone)
#Preview output video
print("Final Video Preview")
final_video= parent_dir+'/'+outvideo
print("DONE")
#showVideo(final_video)
return final_video
Creation of the control of the input time
def validate_time(initial_time,final_time,video_length):
is_wrong1=time_format_check(initial_time)
is_wrong2=time_format_check(final_time)
#print(is_wrong1,is_wrong2)
if is_wrong1 is False and is_wrong2 is False:
delta=time_between(initial_time,final_time)
if len(str(delta)) > 8:
print("Final Time is Smaller than Initial Time: t1>t2")
is_wrong = True
return is_wrong
else:
print("OK")
is_wrong=False
if int(to_seconds(delta)) > 300 :
print("The trim is larger than 5 minutes")
is_wrong = True
return is_wrong
elif int(to_seconds(delta)) > video_length :
print("The trim is larger than video lenght")
is_wrong = True
return is_wrong
else:
return is_wrong
else:
print("Your time format is invalid")
is_wrong = True
return is_wrong
For example, given a period between the initial and final time of your trim is larger than your original video, you have to identify this issue,
validate_time("00:00:01","00:05:00", 200)
The time format is valid 00:00:01
The time format is valid 00:05:00
OK
The trim is larger than video lenght
Given an error you will get the following message:
Step 14 - Unit Tests
Unitest of the basic web app.
URL = 'https://www.youtube.com/watch?v=xw5dvItD5zY'
Text=' I am clonning your voice. Charles!. Machine intelligence is the last invention that humanity will ever need to make.'
# No issue
#video_generator(Text,URL,"00:00:01","00:00:10")
validate_youtube(URL)
Your video is less than 10 minutes
# No issue
#video_generator(Text,URL,"00:00:01","00:00:10")
The first case: Initial time > Final time
# Initial time > Final time
video_generator(Text, URL,"00:00:10","00:00:01")
you get
Checking the url https://www.youtube.com/watch?v=xw5dvItD5zY
Your video is less than 10 minutes
The time format is valid 00:00:10
The time format is valid 00:00:01
Final Time is Smaller than Initial Time: t1>t2
'./demo/tryagain0.mp4'
Second case: Trim is larger than video
#Trim is larger than video
video_generator(Text, URL,"00:00:01","00:05:00")
you get
Checking the url https://www.youtube.com/watch?v=xw5dvItD5zY
Your video is less than 10 minutes
The time format is valid 00:00:01
The time format is valid 00:05:00
OK
The trim is larger than video lenght
'./demo/tryagain0.mp4'
Third case: Trim is larger than the limit of 5 min
#Trim is larger than limit of 5 min
video_generator(Text, URL,"00:00:01","00:06:00")
your output
Checking the url https://www.youtube.com/watch?v=xw5dvItD5zY
Your video is less than 10 minutes
The time format is valid 00:00:01
The time format is valid 00:06:00
OK
The trim is larger than 5 minutes
'./demo/tryagain0.mp4'
Given those types of issues the program will show the following error message:
Once we have created all the modules that allow us check if the source video are okay we create the final application with Gradio.
Step 13 - Gradio Web App creation
text_to_say=gr.inputs.Textbox(label='What would you like the voice to say? (max. 2000 characters per request)')
url =gr.inputs.Textbox(label = "Enter the YouTube URL below:")
initial_time = gr.inputs.Textbox(label='Initial time of trim? (format: hh:mm:ss)')
final_time= gr.inputs.Textbox(label='Final time to trim? (format: hh:mm:ss)')
demo=gr.Interface(fn = video_generator,
inputs = [text_to_say,url,initial_time,final_time],
outputs = 'video',
verbose = True,
title = 'Video Speech Generator from Youtube Videos',
description = 'A simple application that replaces the original speech of the video by your text. Wait one minute to process.',
article =
'''<div>
<p style="text-align: center">
All you need to do is to paste the Youtube link and
set the initial time and final time of the real speach.
(The limit of the trim is 5 minutes and not larger than video length)
hit submit, then wait for compiling.
After that click on Play/Pause for listing to the video.
The video is saved in an mp4 format. Ensure the video contains a face in all the frames.
For more information visit <a href="https://ruslanmv.com/">ruslanmv.com</a>
</p>
</div>''',
enable_queue=True,
examples = [['I am clonning your voice. Charles!. Machine intelligence is the last invention that humanity will ever need to make.',
"https://www.youtube.com/watch?v=xw5dvItD5zY",
"00:00:01","00:00:10"],
['I am clonning your voice. Jim Carrey!. Machine intelligence is the last invention that humanity will ever need to make.',
"https://www.youtube.com/watch?v=uIaY0l5qV0c",
"00:00:29", "00:01:05"],
['I am clonning your voice. Mark Zuckerberg!. Machine intelligence is the last invention that humanity will ever need to make.',
"https://www.youtube.com/watch?v=AYjDIFrY9rc",
"00:00:11", "00:00:44"],
['I am clonning your voice. Ronald Reagan!. Machine intelligence is the last invention that humanity will ever need to make.',
"https://www.youtube.com/watch?v=iuoRDY9c5SQ",
"00:01:03", "00:01:22"],
['I am clonning your voice. Elon Musk!. Machine intelligence is the last invention that humanity will ever need to make.',
"https://www.youtube.com/watch?v=IZ8JQ_1gytg",
"00:00:10", "00:00:43"],
['I am clonning your voice. Hitler!. Machine intelligence is the last invention that humanity will ever need to make.',
"https://www.youtube.com/watch?v=F08wrLyH5cs",
"00:00:15", "00:00:40"],
['I am clonning your voice. Alexandria!. Machine intelligence is the last invention that humanity will ever need to make.',
"https://www.youtube.com/watch?v=Eht6oIkzkew",
"00:00:02", "00:00:30"],
],
allow_flagging=False
)
You can run the following cell and in the text ,you can add the following quote:
I am cloning your voice, Obama!. Just as electricity transformed almost everything 100 years ago, today I actually have a hard time thinking of an industry that I don’t think AI (Artificial Intelligence) will transform in the next several years
and use the link https://www.youtube.com/watch?v=gt9MvcyolTA&ab_channel=TheObamaWhiteHouse and the initial time 00:00:01 and final 00:00:23
demo.launch(share=True)
Running on local URL: http://127.0.0.1:7862/
Running on public URL: https://18966.gradio.app
This share link expires in 72 hours. For free permanent hosting, check out Spaces: https://huggingface.co/spaces
and you will get the following:
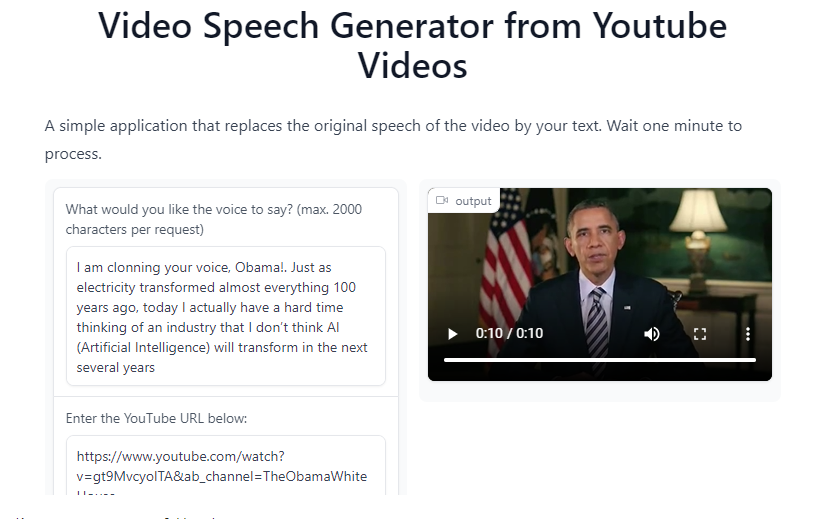
and with Barack Obama
You can try with Ronald Reagan
You can close the server
demo.close()
You can clean the current directory
clean_data()
cleanup()
Step 14 - Shutdown your instance and stop and delete instance
Thank you being here. Don’t forget delete your instance after use.
The python version of this program is hosted the HuggingFace space Tex2Lip
Congratulations! You have created a Web App that creates a Video with Artificial Intelligence with SageMaker.
Related tutorials
FAQ
What does this pipeline produce?
A video where a face speaks your text, generated with AI lip-sync from a source clip.
What else can I build with multimodal AI?
Leave a comment