
Natural Language Processing with Pycaret and Power BI
PyCaret is a workflow automation tool for supervised and unsupervised machine learning. All modules in PyCaret support data preparation

Natural Language Processing
Natural language processing (NLP) is a subfield of computer science and artificial intelligence that deals with analyzing human language.
Some of the common use cases for NLP in machine learning are:
- Theme discovery and modeling: Capture meaning and themes in text collections and apply advanced modeling techniques like Theme Modeling to group similar documents.
- Sentiment analysis: Identify mood or subjective opinions within large amounts of text, including average sentiment and opinion mining.
- Summary of documents: Automatic generation of synopses of large bodies of text.
- Conversion of speech to text and text to speech: Transformation of voice commands into written text and vice versa.
- Automatic translation: Automatic translation of text or voice from one language to another.
What is Topic Modeling?
Topic Modeling is a type of statistical model that is included in unsupervised machine learning and is used to discover abstract topics in text data. The goal of topic modeling is to automatically find topics in a set of documents.
Some common use cases for theme modeling are:
- Summarize large text data by classifying documents into topics ( the idea is quite similar to clustering ).
- Exploratory data analysis to understand texts
- Function engineering that creates functions for supervised machine learning experiments, such as classification or regression
Various algorithms are used for theme modeling. Some of the most common are latent Dirichlet assignment (LDA ), latent semantic analysis (LSA ), and non-negative matrix factorization ( NMF ).
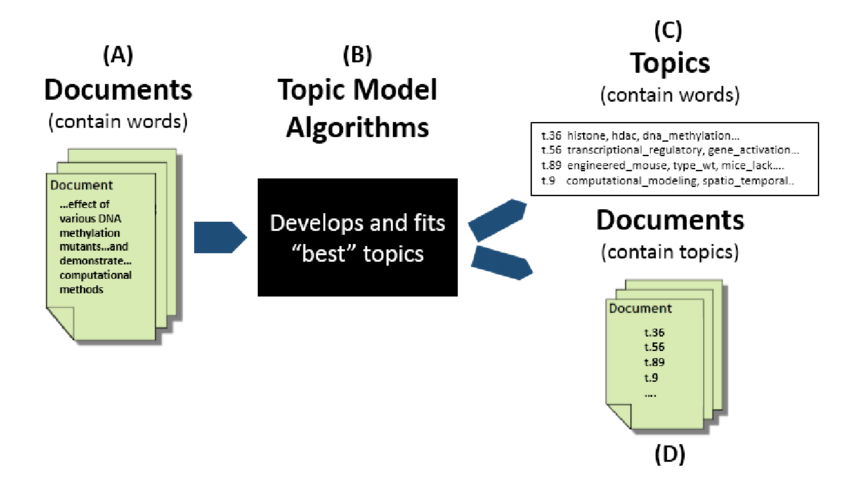
Text pre-processing for theme modeling
To get meaningful results from topic modeling, the text data must be processed before it is fed into the algorithm. This is common with almost all NLP tasks. Text preprocessing is different from the classic preprocessing techniques that are often used in machine learning.
PyCaret automatically preprocesses text data by applying more than 15 techniques, such as elimination of stopwords and stopwords, tokenization, stemming, bi-gram / tri-gram extraction etc.
Common Techniques used in NLP
- Tokenize: separate words from the text into entities called tokens,
- Tagging Part of Speech (PoS ): Classify sentences in verb, noun, adjective, preposition, etc.
- Steeming: get the root of the words
- Bag of words : it is a way of representing the vocabulary that we will use in our model and consists of creating a matrix in which each column is a token and the number of times that token appears will be counted
NLP module in PyCaret
PyCaret’s NLP module (pycaret.nlp) is an unsupervised machine learning module that can be used to analyze text data by creating a topic model to find hidden semantic structure in documents.
PyCaret’s NLP module comes integrated with a wide range of text preprocessing techniques, which is the fundamental step in any NLP problem. Transform raw text into a format that machine learning algorithms can learn from.
In machine learning and natural language processing, a topic model is a type of statistical model for discovering the abstract “topics” that occur in a collection of documents.
Theme modeling is a frequently used text extraction tool for discovering hidden semantic structures in a body of text.
A theme model is created using the create_model () function which takes a required parameter, that is, the model name as a string. This function returns a trained model object.
Setting up the Environment
Before we start using PyCaret’s machine learning capabilities in Power BI we have to create a virtual environment and install pycaret.
Create an anaconda environment
Open Anaconda Prompt from start menu and run the following code:
conda create --name pycaret python=3.8
Install PyCaret
Run the following code in Anaconda Prompt:
conda activate pycaret
pip install pycaret
Some functionality in pycaret.nlp requires an English language model. The language model is not downloaded automatically when you install pycaret. You will need to download this Python command line interface, like Anaconda Prompt.
To download the model, type the following on your command line:
python -m spacy download en_core_web_sm
python -m textblob.download_corpora
Install kernel
then in your terminal type the following commands:
conda install ipykernel
python -m ipykernel install --user --name pycaret --display-name "Python (Pycaret)"
Wee need to find our Anaconda Python interpreter path
Windows
The location of a Python interpreter for a conda environment other than the root conda environment, run
where python
for example in my case I have:
C:\Anaconda3\envs\pycaret\python.exe
macOS and Linux
The location of a Python interpreter for a conda environment other than the root conda environment, run
which python
You copy this path because we will requiere in the next step
Power BI setup
The virtual environment created must be linked with Power BI.
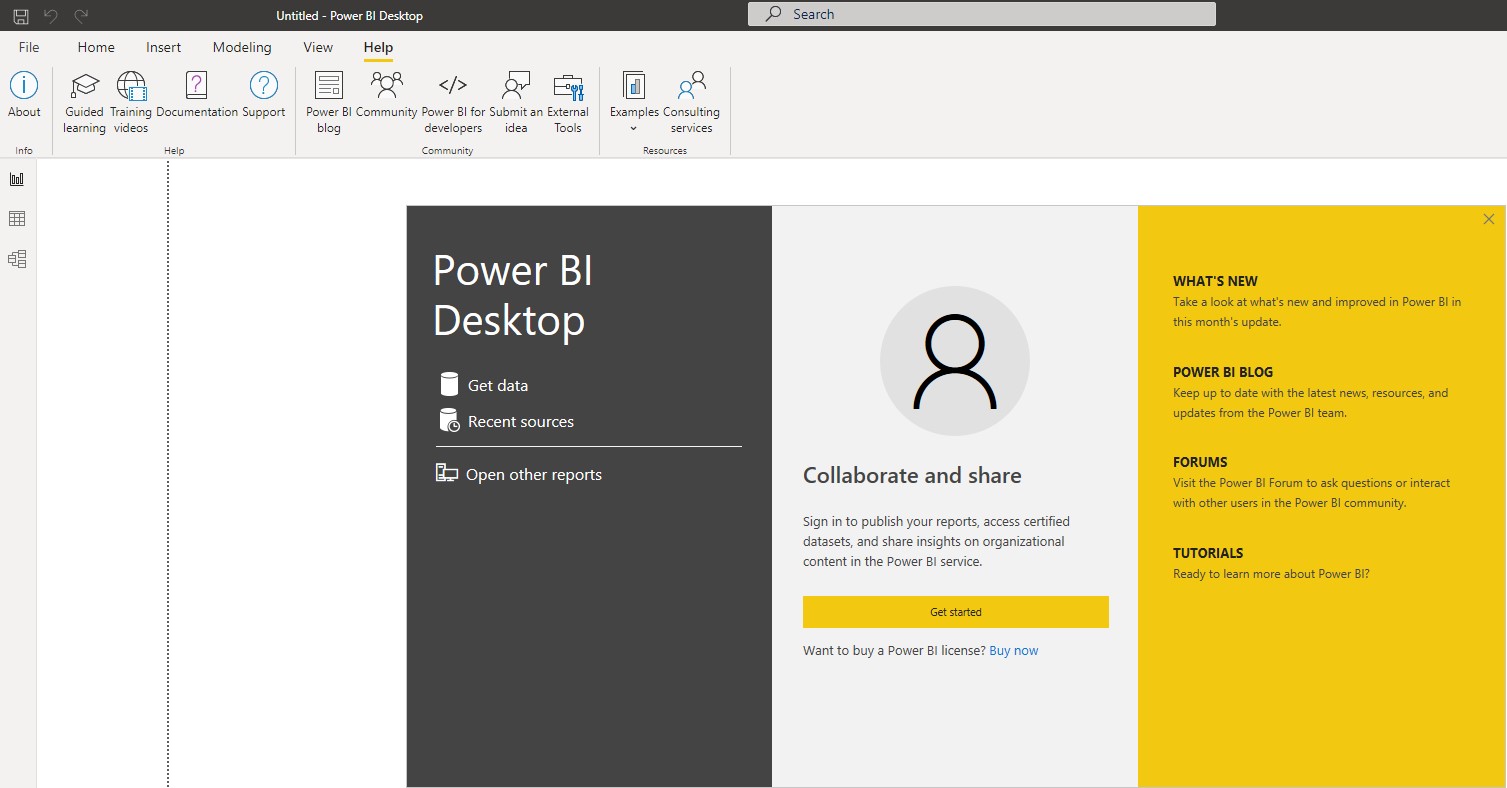
and we go to File → Options
Set Python Directory in Power BI
And we go to the Global → Python scripting and then under Detected Python home directories we choose other
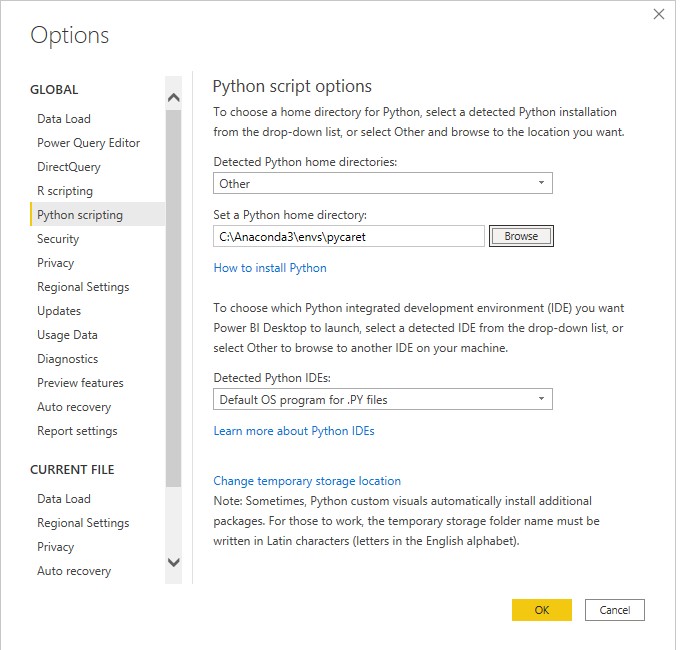
and we select the Anaconda Environment path that we have such in my case is
C:\Anaconda3\envs\pycaret\
Dataset
Kiva Microfunds is a non-profit organization that enables people to lend money to low-income entrepreneurs and students around the world.
We will use the text provided in the personal story to gain insight into the dataset and understand the semantic structure hidden in the text.
The data set contains 6818 samples.
Below is a brief description of the features:
- country: country of the borrower
- in: Personal history of the borrower when he applied for the loan
- gender: gender (M = male, F = female)
- loan_amount: Loan amount approved and disbursed
- Default: Lender type (Lender = personal user registered on Kiva website, Partner = microfinance institution that works with Kiva to find and finance loans)
- sector: sector of the borrower
- status: loan status (1-default, 0-repaid)
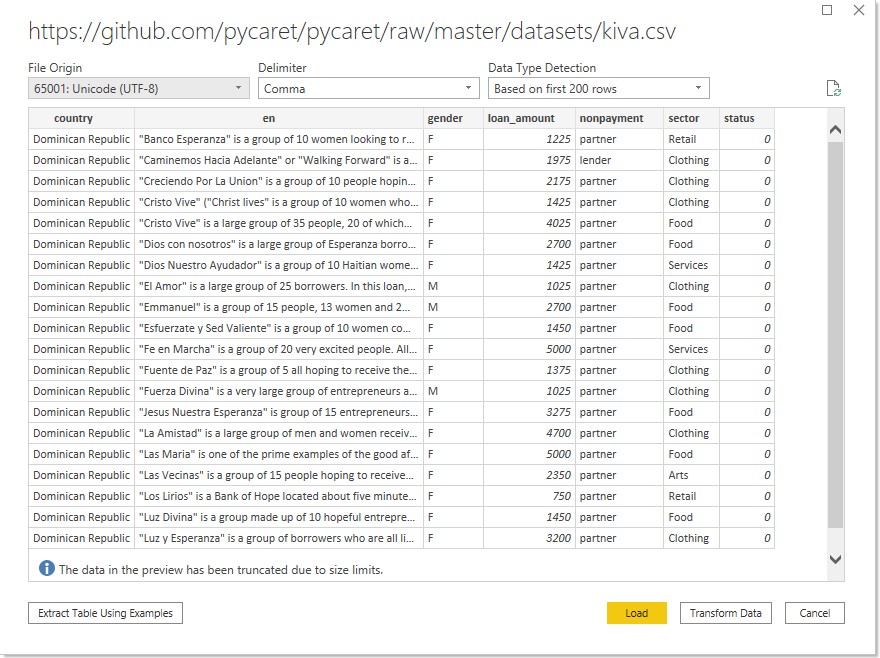
In this tutorial we will use kiva.csv file that is available on PyCaret’s github repository
we can load the data using a web connector
Power BI Desktop → Get Data → From Web
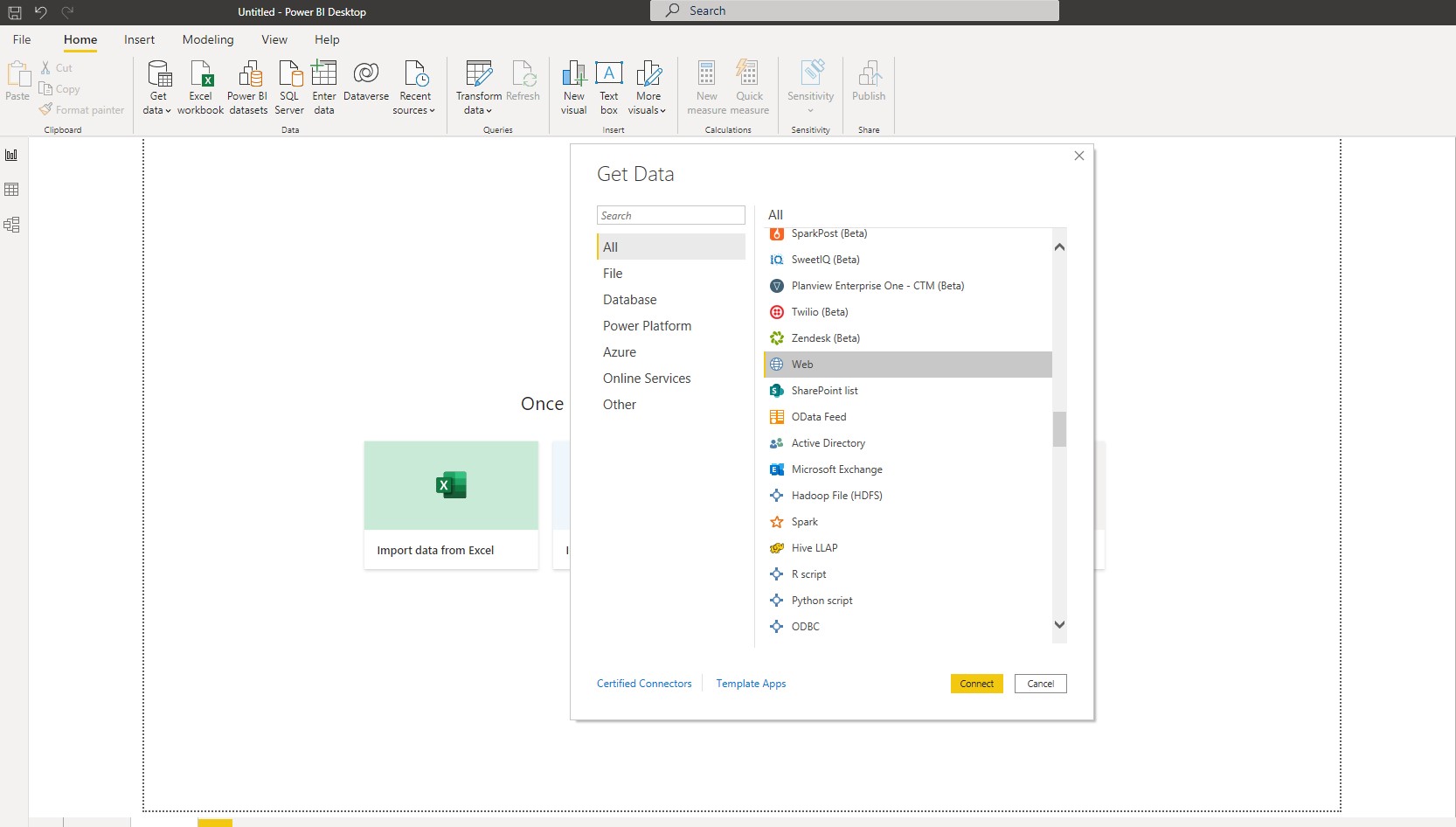
and then we copy the following address
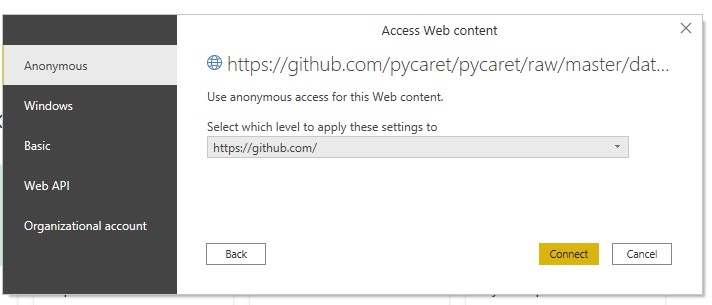
https://github.com/pycaret/pycaret/raw/master/datasets/kiva.csv
and we connect
and the load
we can see that now the dataset is loaded
Python Script with Power Bi
First we go to the Home and then Transform Data and it will be open a new window called Power Query Editor
Then in Power Query Editor → Transform
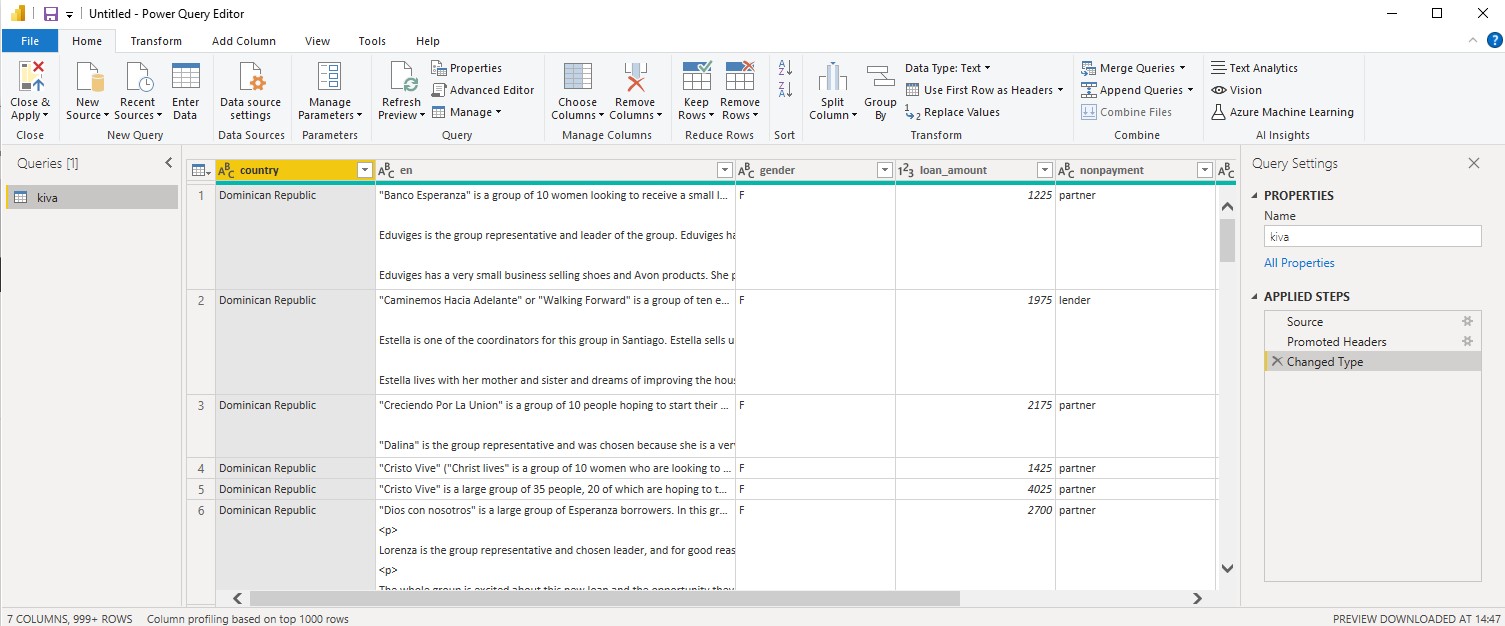
We need to check that all the columns corresponds to the correct type of data
For columns that are text, the type should be text and integers to whole numbers and so on.
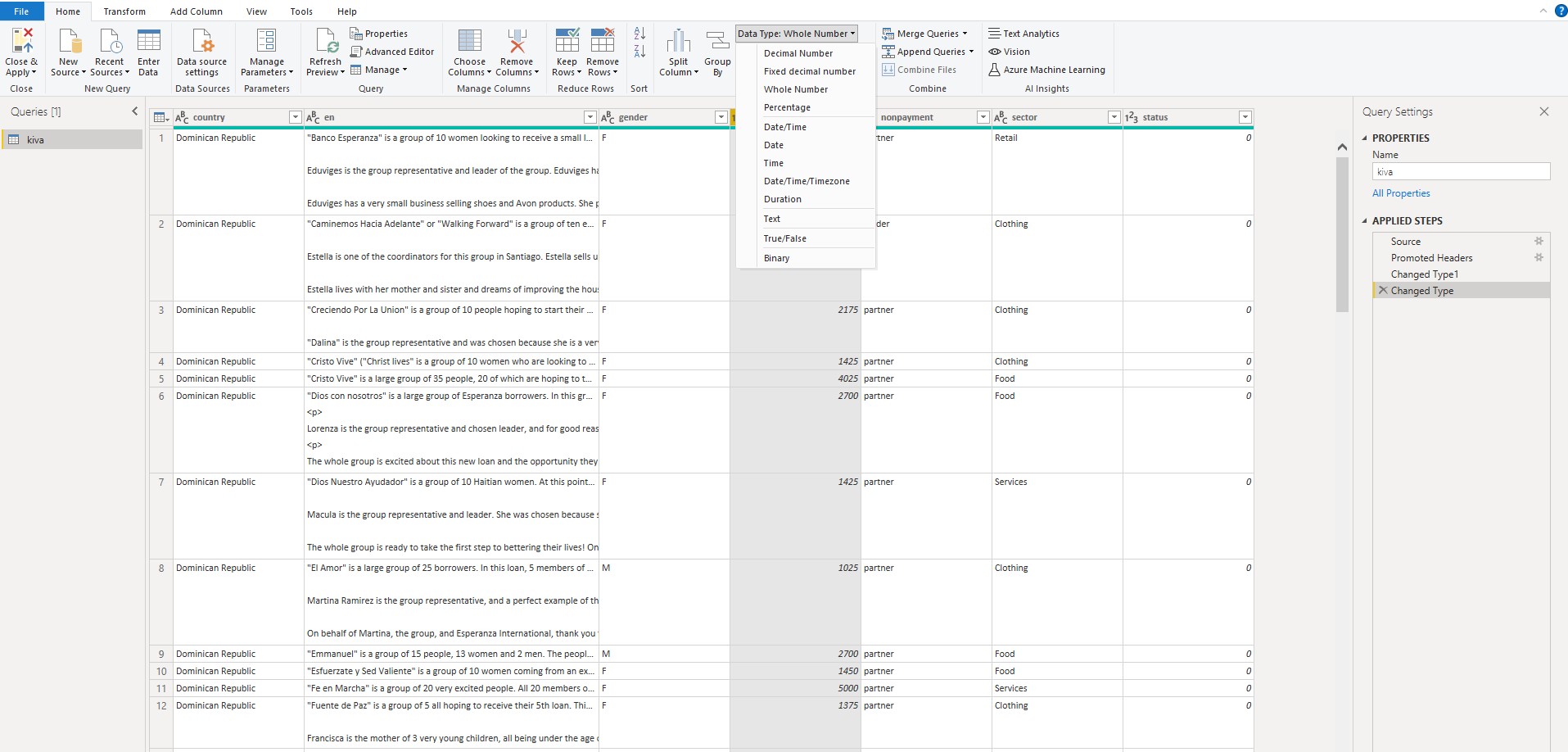
To execute Python script in Power Query Editor
we do Transform → Run python script
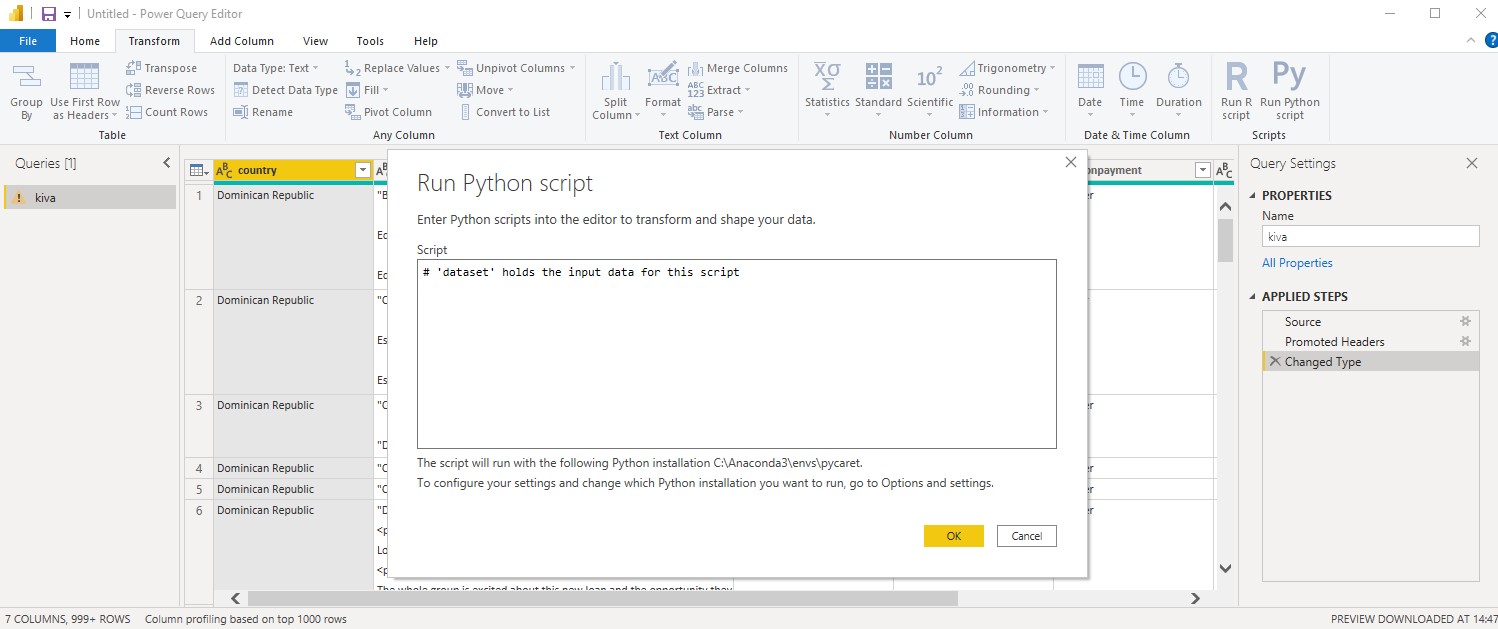
then we insert the following python script
from pycaret.nlp import *
dataset = get_topics(data = dataset, text='en')
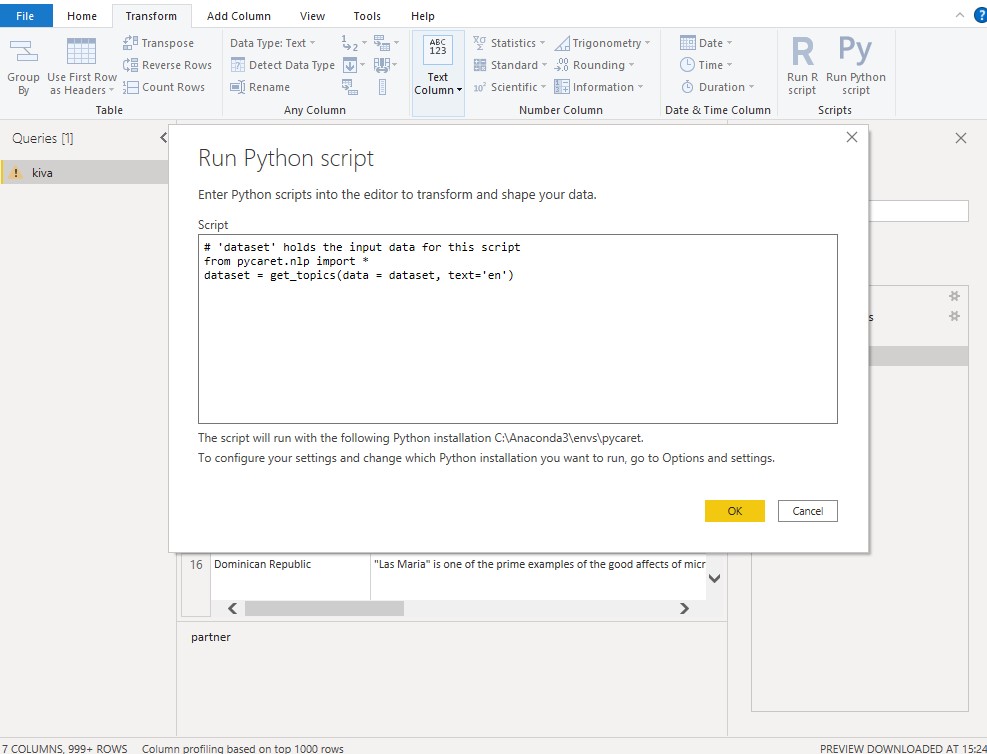
we wait like one minute and we get the following
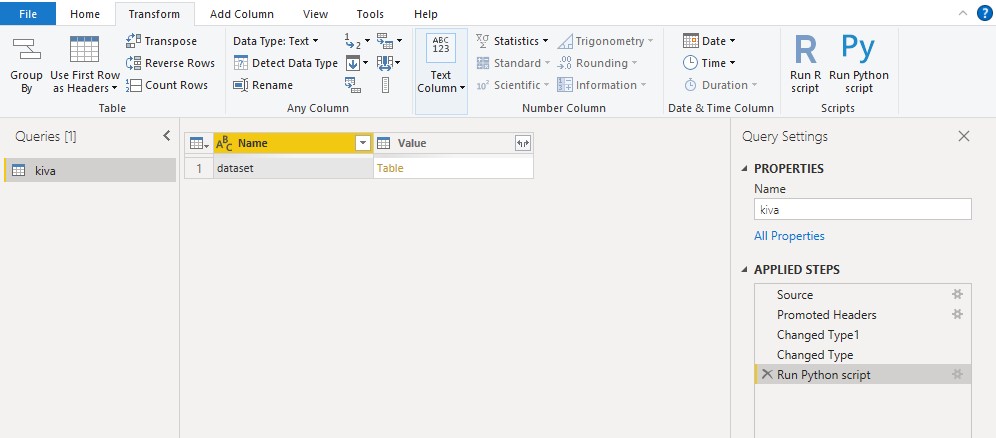
we click on table, and we obtain a
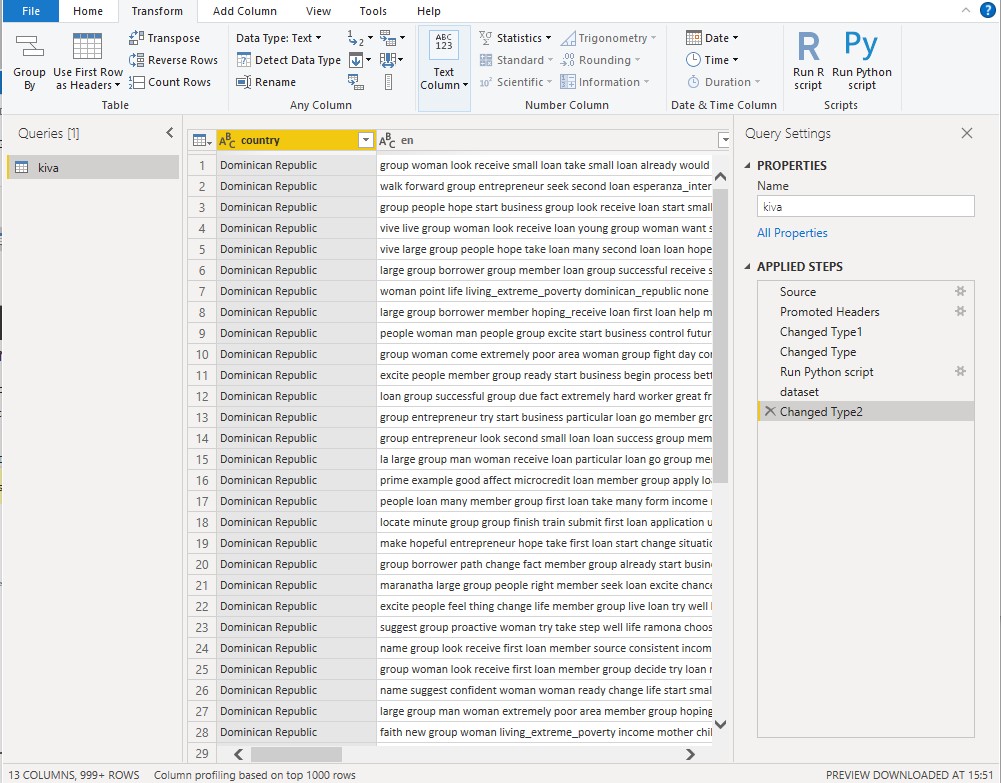
now this new table has new columns, that are
Topic_1, Topic_2, Topic_3, and Dominant_Topic, Perc_Dominant_Topic
Then we select the type of visualization Word Cloud and we select the column en

then we select the pie chart and we select the topic 1 topic 2 topic 3
and also we select the filled map with the countries and dominant topic and finally you get
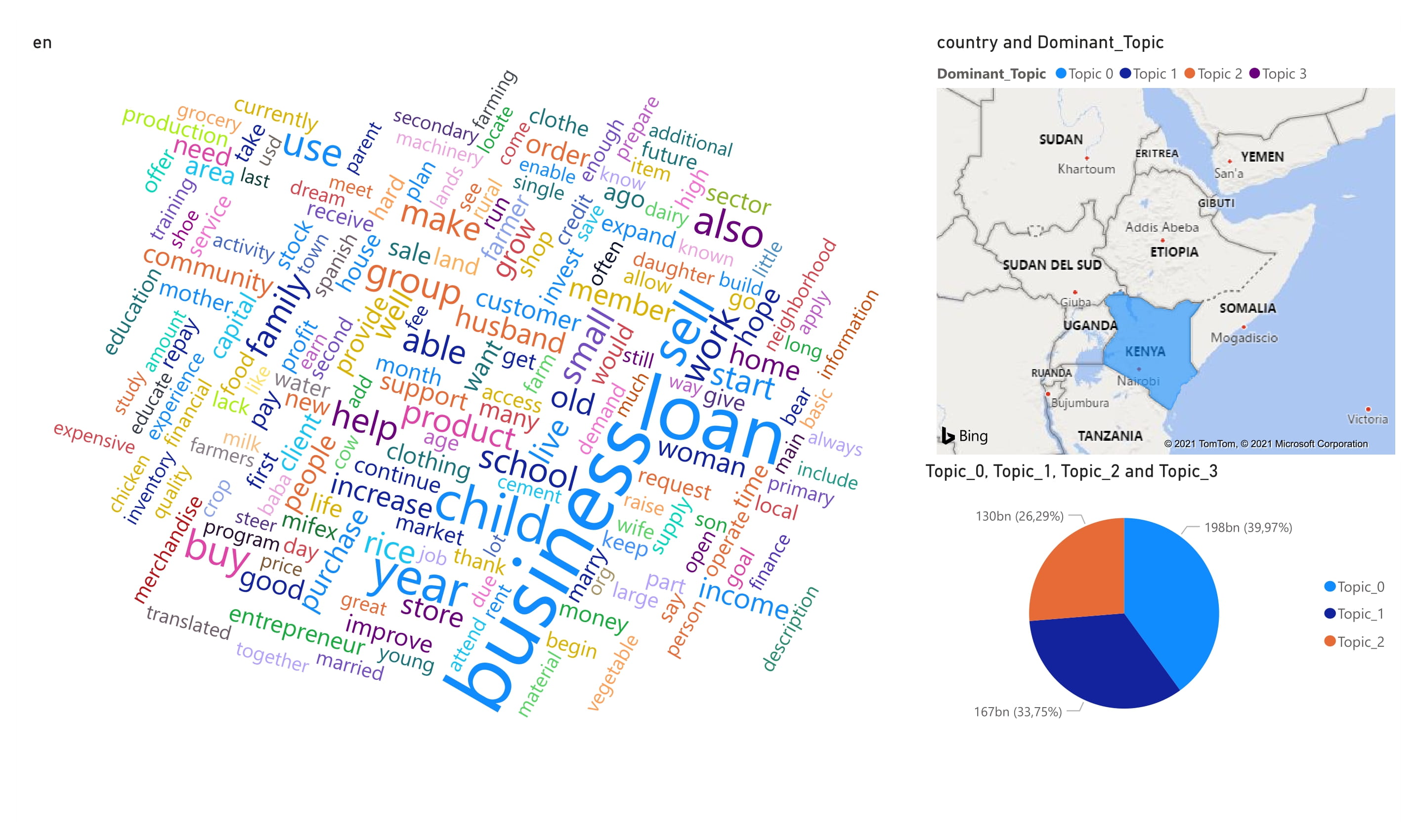
Pycaret with Jupyter Notebook
In the terminal we return back with our environment
conda activate pycaret
jupyter notebook&
In the jupyter notebook we write
Load Dataset
from pycaret.datasets import get_data
data = get_data('kiva')
| country | en | gender | loan_amount | nonpayment | sector | status | |
|---|---|---|---|---|---|---|---|
| 0 | Dominican Republic | "Banco Esperanza" is a group of 10 women looki... | F | 1225 | partner | Retail | 0 |
| 1 | Dominican Republic | "Caminemos Hacia Adelante" or "Walking Forward... | F | 1975 | lender | Clothing | 0 |
| 2 | Dominican Republic | "Creciendo Por La Union" is a group of 10 peop... | F | 2175 | partner | Clothing | 0 |
| 3 | Dominican Republic | "Cristo Vive" ("Christ lives" is a group of 10... | F | 1425 | partner | Clothing | 0 |
| 4 | Dominican Republic | "Cristo Vive" is a large group of 35 people, 2... | F | 4025 | partner | Food | 0 |
#check the shape of data
data.shape
(6818, 7)
# sampling the data to select only 1000 documents
data = data.sample(1000, random_state=786).reset_index(drop=True)
data.shape
(1000, 7)
Initialization of the environment
from pycaret.nlp import *
exp_nlp101 = setup(data = data, target = 'en', session_id = 123)
| Description | Value |
|---|---|
| session_id | 123 |
| Documents | 1000 |
| Vocab Size | 5302 |
| Custom Stopwords | False |
Creation of the Model
models()
| Name | Reference | |
|---|---|---|
| ID | ||
| lda | Latent Dirichlet Allocation | gensim/models/ldamodel |
| lsi | Latent Semantic Indexing | gensim/models/lsimodel |
| hdp | Hierarchical Dirichlet Process | gensim/models/hdpmodel |
| rp | Random Projections | gensim/models/rpmodel |
| nmf | Non-Negative Matrix Factorization | sklearn.decomposition.NMF |
where we have the following information
- session_id: A pseduo-random number distributed as a seed in all functions for later reproducibility. If no
session_idis passed, a random number is automatically generated and distributed to all functions. In this experiment, session_id is set to123for later reproducibility. - Documents: Number of documents (or samples in the dataset if the data frame is passed).
- Vocabulary size: Vocabulary size in the corpus after applying all the preprocessing of the text, such as stopword removal, extraction of bigrams / trigrams, stemming, etc.
Note that all text preprocessing steps are done automatically when you run setup (). These steps are essential to perform any NLP experiment.
The setup () function prepares the ready-to-use corpus and dictionary for theme models that you can create using the create_model () function. Another way to pass the text is as a list, in which case the target parameter is not needed.
lda = create_model('lda')
print(lda)
LdaModel(num_terms=5302, num_topics=4, decay=0.5, chunksize=100)
We have created the Latent Dirichlet Assignment (LDA) model with a single word, that is, create_model (). Notice that the num_topics parameter is set to 4, which is a default value taken when you do not pass the num_topics parameter in create_model () .
In the following example, we will create an LDA model with 6 themes and also set the multi_core parameter to True. When multi_core is set to True, Latent Dirichlet Allocation (LDA) uses all CPU cores to parallelize and speed up model training.
lda2 = create_model('lda', num_topics = 6, multi_core = True)
print(lda2)
LdaModel(num_terms=5302, num_topics=6, decay=0.5, chunksize=100)
Model assignation
Now that we have created a theme model, we would like to assign the theme proportions to our dataset (6818 documents / samples) to analyze the results. We will achieve this using the ʻassign_model () `function. See an example below:
lda_results = assign_model(lda)
lda_results.head()
| country | en | gender | loan_amount | nonpayment | sector | status | Topic_0 | Topic_1 | Topic_2 | Topic_3 | Dominant_Topic | Perc_Dominant_Topic | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Kenya | praxide marry child primary school train tailo... | F | 75 | partner | Services | 0 | 0.871802 | 0.000354 | 0.001464 | 0.126379 | Topic 0 | 0.87 |
| 1 | Kenya | gynaecology practitioner run reproductive year... | M | 1200 | partner | Health | 0 | 0.984097 | 0.000325 | 0.001341 | 0.014237 | Topic 0 | 0.98 |
| 2 | Dominican Republic | live san_cristobal child boy girl range year o... | F | 150 | partner | Clothing | 0 | 0.070113 | 0.000361 | 0.001493 | 0.928032 | Topic 3 | 0.93 |
| 3 | Kenya | phanice marry child daughter secondary school ... | F | 150 | lender | Services | 1 | 0.727180 | 0.000391 | 0.001616 | 0.270813 | Topic 0 | 0.73 |
| 4 | Kenya | fredrice nzioka kilonzo year old hotel operate... | F | 300 | lender | Food | 1 | 0.463812 | 0.000355 | 0.208921 | 0.326911 | Topic 0 | 0.46 |
Notice how 6 additional columns are now added to the data frame. ʻEn is the text after all the preprocessing. Topic_0 … Topic_3 are the proportions of the topics and represent the distribution of topics for each document. Dominant_Topic is the topic number with the highest proportion and Perc_Dominant_Topic` is the percentage of dominant topic over 1 (only shown when the models are stochastic, that is, the sum of all the proportions is equal to 1).
Visualization of the Model
The plot_model () function can be used to parse the general corpus or just specific topics extracted through the topic model. So the plot_model () function can also work without passing any trained model objects. See examples below:
Frequency Distribution of Entire Corpus
plot_model()
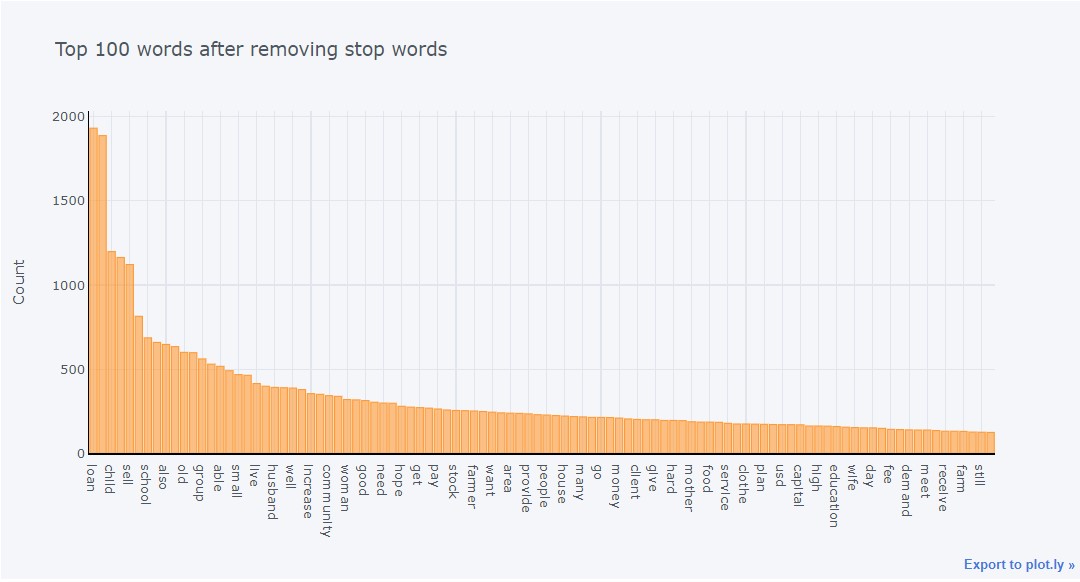
Top 100 Bigrams on Entire Corpus
plot_model(plot = 'bigram')

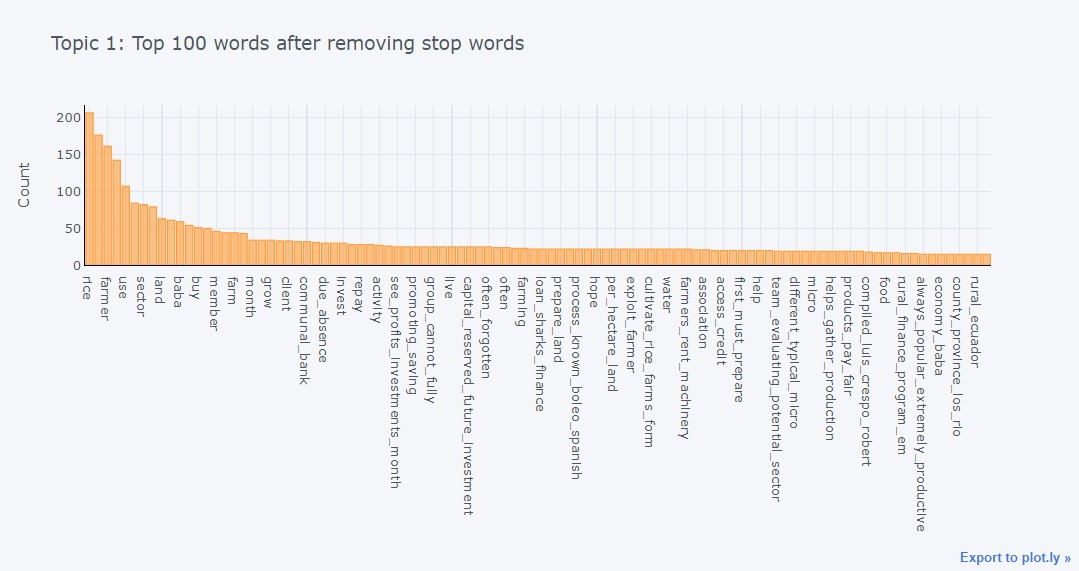
Frequency Distribution of Topic 1
plot_model () can also be used to parse the same plots for specific topics. To generate topic-level plots, the function requires the trained model object to be passed inside plot_model (). In the following example, we will generate a frequency distribution on Topic 1 only as defined in the topic_num parameter.
plot_model(lda, plot = 'frequency', topic_num = 'Topic 1')
Topic Distribution
plot_model(lda, plot = 'topic_distribution')
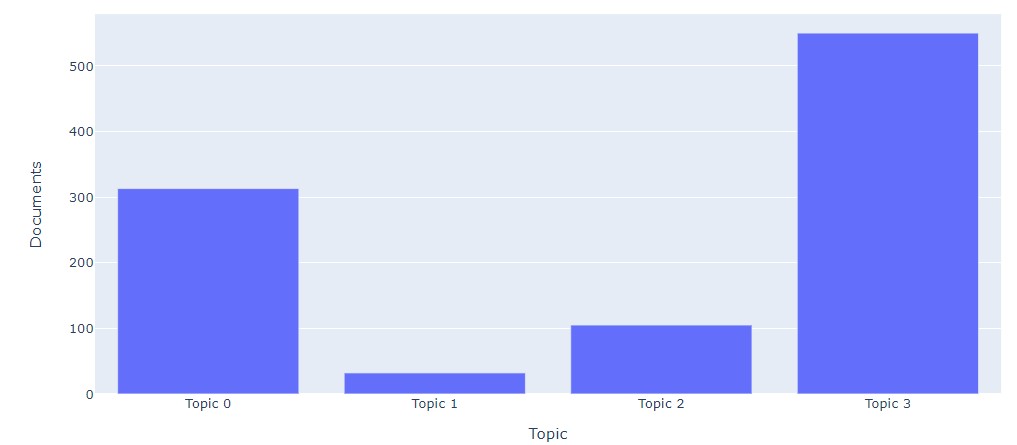
Each document is a distribution of topics and not a single topic.
Although, if the task is to categorize the document into specific topics, it would not be wrong to use the ratio of topics with the highest value to categorize the document into one topic. In the chart above, each document is ranked on a topic using the highest proportion of topic weights. We can see that most of the documents are in “Topic 3” and only a few are in “Topic 1”. If you hover your mouse over these bars, you will get a basic idea of the topics in this topic by looking at the keywords.
For example, if you evaluate “Topic 2”, you will see keywords like “farmer”, “rice”, “land”, which probably means that loan applicants in this category belong to agricultural loans. However, if you hover over Topic 0 and Topic 3, you will notice that many repetitions and keywords overlap in all topics, such as the word “loan” and “business” that appear in both the ` Topic 0 as in Topic 3`
T-distributed Stochastic Neighbor Embedding (t-SNE)
plot_model(lda, plot = 'tsne')
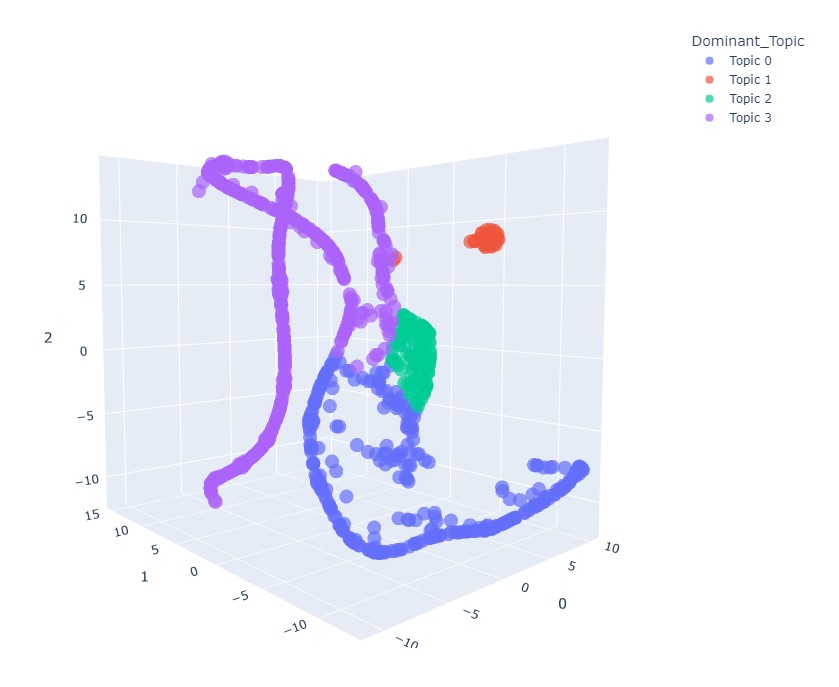
T-distributed stochastic neighbor embedding (t-SNE) is a nonlinear dimensionality reduction technique well suited for embedding high-dimensional data for display in two- or three-dimensional low-dimensional space.
Uniform Manifold Approximation and Projection Plot
plot_model(lda, plot = 'umap')
![]()
UMAP (Uniform Manifold Approximation and Projection) is a novel multi-learning technique for dimensionality reduction. It is similar to tSNE and PCA in purpose, as they are all dimensionality reduction techniques for 2d / 3d projections. UMAP is built from a theoretical framework based on Riemannian geometry and algebraic topology.
Evaluation of the Model
Another way to analyze model performance is to use the ʻevaluate_model () function which displays a user interface for all available graphics for a given model. It uses the plot_model () function internally. See the example below where we have generated a sentiment polarity plot for Topic 3 using the LDA model stored in the variable lda.
evaluate_model(lda)
interactive(children=(ToggleButtons(description='Plot Type:', icons=('',), options=(('Frequency Plot', 'freque…
Save model
As you delve deeper into natural language processing, you will learn that topic model training time increases exponentially as the size of the corpus increases. As such, if you want to continue your experiment or analysis at a later time, you do not need to repeat the entire experiment and retrain your model. PyCaret’s built-in save_model () function allows you to save the model for later use.
save_model(lda,'Final LDA Model')
Model Succesfully Saved
Load model
To load a model saved at a future date in the same environment or in a different one, we would use PyCaret’s load_model () function.
saved_lda = load_model('Final LDA Model')
Model Sucessfully Loaded
print(saved_lda)
You can download the notebook here
Congratulations! We have practiced Pycaret with Power BI
Leave a comment