
How to use the parameters in Neural Networks
Today I will discuss about how to adjust the activation shape, activation size, and the number of parameters of the neural networks .
I will use a small test dataset from Genshin Impact videogame where we will apply an AlexNet Network
In ordering to select the appropriate parameters in a simple Neural Network for example in case of a Convolutional Neural Network , we should remember the meaning of all the layers and understand the following parameters:
- Activation Shape
- Activation Size
- Number of Parameters
Analysis of Neural Networks
To build the neural network, we should know the dimensions of the layers that are include in the network.
In this work we will use three types of layers in a convolution
- Convolution (CONV)
- Pooling (POOL)
- Fully connected (FC)
Parameters in Convolution Neural Networks (CNNs)
Let us define several helper functions that allow us understand how the Neural Networks works and use.
Convolution (CONV)
def dim_valid_convolution(inputs, kernel):
'''
input
nh : height
nw : widht
kernel
fh : filter
fw : filter
'''
nh,nw,= inputs
fh,fw = kernel
return (nh-fh) + 1, (nw-fw) + 1
Let us assume that you have an image of dimension 6x6 which you will perform a convolution with a filter (kernel) that has a dimensions of 3x3. Then the valid output dimension of this convolution is 4x4.
This example may be represented as:
inputs = 6 , 6 # nxn image
filters = 3 , 3 # fxf filter
dim_valid_convolution( inputs, filters)
(4, 4)
def dim_same_convolution(inputs, kernel,s,p):
'''
Output size is the same as input size
input
nh : height
nw : widht
kernel
fh : filter
fw : filter
'''
nh,nw,= inputs
fh,fw = kernel
return (nh+2*p-fh) + 1, (nw+2*p-fw) + 1
We choose pad in a way that the output size is the same as the input size
inputs = 6 , 6 # nxn image
filters = 3 , 3 # fxf filter
stride=1.0 #stride s
padding=1.0 # padding s
parameters=dim_same_convolution( inputs, filters,stride,padding)
def check_same(inputs,parameters):
#2D
if len(parameters)==2 :
assert parameters[0] == inputs[0] and parameters[1] ==inputs[1],"It is not same convolution, please fix the stride or padding for the input"+str(inputs)+"and parameters "+str(parameters)
#3D
if len(parameters)==3 :
assert parameters[0][0] == inputs[0] and parameters[0][1] ==inputs[1],"It is not same convolution, please fix the stride or padding for the input"+str(inputs)+"and parameters "+str(parameters)
check_same(inputs,parameters)
Now let us consider another example, we take a image of dimension 7x7 which you will perform an stride convolution with a kernel of 3x3 within stride 2 and padding 0.
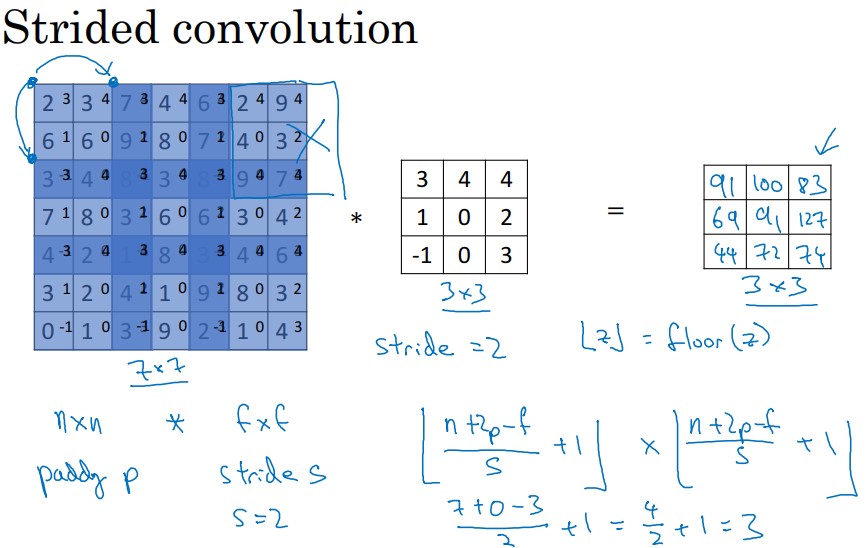
def dim_strided_convolution(inputs, kernel ,s,p):
'''
input = (nh, nw)
nh : height
nw : widht
kernel = (fh, fw)
fh : filter height
fw : filter widht
p : padding
s : stride
'''
nh,nw= inputs
fh,fw= kernel
print("Activation Shape Strided")
return (nh+2*p-fh)/s + 1, (nw+2*p-fw)/s + 1
You can describe this example as
inputs = 7,7 # nxn image
kernel = 3,3 # fxf filter
stride=2.0 #stride s
padding=0.0 # padding s
dim_strided_convolution(inputs, kernel ,stride,padding)
with the allowed results
Activation Shape Strided
(3.0, 3.0)
def dim_rgb_convolution(inputs, kernel,stride,padding,filters):
'''
input = (nh, nw, nc)
where
nh: height
nw: widht
nc: channels
output = (nhl,nwl,ncl)
nhl = (nh+2*p-fw)/s + 1
nwl = (nw+2*p-fh)/s + 1
ncl = filters
where
fw,fh : filter sizes
p : padding
s : stride
ncl : filters
'''
nh,nw,nc = inputs
fh,fw = kernel
s = stride
p = padding
ncl = filters
nhl = (nh+2*p-fw)/s + 1
nwl = (nw+2*p-fh)/s + 1
output = (int(nhl),int(nwl),int(ncl))
print("Activation Shape")
return output
Let us define the number of parameters used in each convolution.
The parameters are defined as :
((shape of width of filter x shape of height filter x number of filters in the previous layer+1) xnumber of filters)
def nparameters_convolution(inputs, kernel,stride,padding,filters):
'''
input = (nh, nw, nc)
where
nh: height
nw: widht
nc: channels
activation_shape = (nhl,nwl,ncl)
nhl = (nh+2*p-fw)/s + 1
nwl = (nw+2*p-fh)/s + 1
ncl = filters
where
fw,fh : filter sizes
p : padding
s : stride
ncl : filters
'''
nh,nw,nc = inputs
fh,fw = kernel
s = stride
p = padding
ncl = filters
#activation shape
nhl = (nh+2*p-fw)/s + 1
nwl = (nw+2*p-fh)/s + 1
activation_shape = (int(nhl),int(nwl),int(ncl))
# activation size
activation_size=int(nhl)*int(nwl)*int(ncl)
# number Parameters
nparameters=((fh*fw*nc)+1)*ncl
print("Activation Shape,", "Activation Size,","# Parameters")
return activation_shape , activation_size, nparameters
inputs = 32,32,3 #nw x nh x nc image
kernel = 5,5 #fw x fw filter
stride = 1.0 #stride s
padding = 0.0 #padding p
filters = 8 #number of filters ncl
nparameters_convolution(inputs, kernel,stride,padding,filters)
Activation Shape, Activation Size, # Parameters
((28, 28, 8), 6272, 608)
For example, let us a consider simple case of the a convolution Neural Network like ConvNet from the Coursera Deep Learning Course

with the following example
inputs = 39,39,3 #nw x nh x nc image
kernel = 3,3 #fw x fw filter
stride = 1.0 #stride s
padding = 0.0 #padding p
filters = 10 #number of filters ncl
dim_rgb_convolution(inputs, kernel,stride,padding,filters)
Activation Shape
(37, 37, 10)
Where the activation size, considering it’s merely the product of width, height and the number of channels in that layer.
The input layer’s shape is (37, 37, 10), the activation size of that layer is \(37* 37* 10 = 13690\)
37* 37* 10
13690
inputs = 37,37,10 #nw x nh x nc image
kernel = 5,5 #fw x fw filter
stride = 2.0 #stride s
padding = 0.0 #padding p
filters = 20 #number of filters ncl
dim_rgb_convolution(inputs, kernel,stride,padding,filters)
Activation Shape
(17, 17, 20)
The same happens if we want to calculate the activation size for this convolution. All we have to do is just multiply (17, 17, 20) , i.e 17* 17* 20= 5780
17* 17* 20
5780
inputs = 17,17,20 #nw x nh x nc image
kernel = 5,5 #fw x fw filter
stride = 2.0 #stride s
padding = 0.0 #padding p
filters = 40 #number of filters ncl
dim_rgb_convolution(inputs, kernel,stride,padding,filters)
Activation Shape
(7, 7, 40)
nparameters_convolution(inputs, kernel,stride,padding,filters)
Activation Shape, Activation Size, # Parameters
((7, 7, 40), 1960, 20040)
The number of parameters in a given layer is the count of “learnable” elements for a filter aka parameters for the filter for that layer. Parameters in general are weights that are learnt during training. They are weight matrices that contribute to model’s predictive power, changed during back-propagation process
Pooling (POOL)
In the pooling there are the following Hyperparameters:
-
f: filter size
- s: stride
- Max or average pooling
Given an input with the dimensions
\[n_H \times n_W \times n_C\]Max or pooling is has the following dimensions
\[\frac{n_H+2p-f}{s}+1 \times \frac{n_W+2p-f}{s}+1 \times n_C\]The numbers of channels remains \(n_C\)
def dim_pool(inputs, kernel,stride,padding):
'''
input = (nh, nw, nc)
where
nh: height
nw: widht
nc: channels
activation_shape = (nhl,nwl,ncl)
nhl = (nh+2*p-fw)/s + 1
nwl = (nw+2*p-fh)/s + 1
ncl = nc
where
fw,fh : filter sizes
p : padding
s : stride
'''
nh,nw,nc = inputs
fh,fw = kernel
s = stride
p = padding
ncl = nc
nhl = (nh+2*p-fw)/s + 1
nwl = (nw+2*p-fh)/s + 1
activation_shape = (int(nhl),int(nwl),int(ncl))
# activation size
activation_size=int(nhl)*int(nwl)*int(ncl)
# number Parameters
nparameters=0
print("Activation Shape,", "Activation Size,","# Parameters")
return activation_shape , activation_size, nparameters
inputs = 5,5,5 #nw x nh x nc image
kernel = 3,3 #fw x fw filter
stride = 1.0 #stride s
padding = 0.0 #padding p
dim_pool(inputs, kernel,stride,padding)
Activation Shape, Activation Size, # Parameters
((3, 3, 5), 45, 0)
inputs = 7,7,1000 #nw x nh x nc image
kernel = 2,2 #fw x fw filter
stride = 2.0 #stride s
padding = 0.0 #padding p
dim_pool(inputs, kernel,stride,padding)
Activation Shape, Activation Size, # Parameters
((3, 3, 1000), 9000, 0)
Another example, that we can consider is the LeNet-5
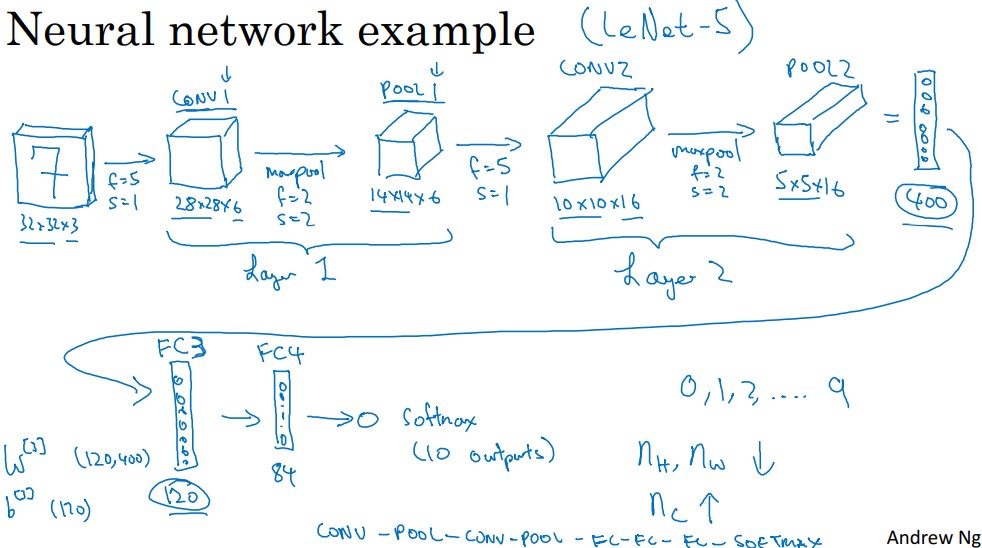
The input layer’s shape is (32, 32, 3), the activation size of that layer is 32 * 32 * 3 = 3072.
CONV 1
inputs =32,32,3 #nw x nh x nc image
kernel = 5,5 #fw x fw filter
stride = 1.0 #stride s
padding = 0.0 #padding p
filters = 8 #6 #number of filters ncl
newinput=dim_rgb_convolution(inputs, kernel,stride,padding,filters)
newinput
Activation Shape
(28, 28, 8)
The activation size for CONV1.
28* 28* 8
6272
Parameters CONV1
((fw x fw *nc +1)*ncl)
(((5*5*3)+1)*8)
608
inputs =32,32,3 #nw x nh x nc image
kernel = 5,5 #fw x fw filter
stride = 1.0 #stride s
padding = 0.0 #padding p
filters = 8 #number of filters ncl
nparameters_convolution(inputs, kernel,stride,padding,filters)
Activation Shape, Activation Size, # Parameters
((28, 28, 8), 6272, 608)
POOL 1
inputs = 28, 28, 8 #nw x nh x nc
kernel = 2,2 #fw x fw filter
stride = 2.0 #stride s
padding = 0.0 #padding p
dim_pool(inputs, kernel,stride,padding)
Activation Shape, Activation Size, # Parameters
((14, 14, 8), 1568, 0)
The activation size for POOL1.
14* 14* 8
1568
CONV 2
inputs =14, 14, 8 #nw x nh x nc image
kernel = 5,5 #fw x fw filter
stride = 1.0 #stride s
padding = 0.0 #padding p
filters = 16 #number of filters ncl
newinput=dim_rgb_convolution(inputs, kernel,stride,padding,filters)
newinput
Activation Shape
(10, 10, 16)
The activation size for CONV2.
10*10*16
1600
inputs =14, 14, 8 #nw x nh x nc image
kernel = 5,5 #fw x fw filter
stride = 1.0 #stride s
padding = 0.0 #padding p
filters = 16 #number of filters ncl
nparameters_convolution(inputs, kernel,stride,padding,filters)
Activation Shape, Activation Size, # Parameters
((10, 10, 16), 1600, 3216)
POOL 2
inputs = 10, 10, 16 #nw x nh x nc
kernel = 2,2 #fw x fw filter
stride = 2.0 #stride s
padding = 0.0 #padding p
dim_pool(inputs, kernel,stride,padding)
Activation Shape, Activation Size, # Parameters
((5, 5, 16), 400, 0)
The activation size for POOL2.
5* 5* 16
400
Parameters in general are weights that are learnt during training. They are weight matrices that contribute to model’s predictive power, changed during back-propagation process.
FULLY CONNECTED LAYER
To calculate the learnable parameters here, all we have to do is just multiply the by the shape of width hw, height hw, previous layer’s filters nc and account for all such filters k in the current layer. Don’t forget the bias term for each of the filter.
def nparameters_fully_connected(c , p):
'''
current layer dimension: c
previous layer activation size: p
'''
#activation shape
activation_shape = (c,1)
# activation size
activation_size=c
number=(( c * p)+1 * c)
print("Activation Shape,", "Activation Size,","# Parameters")
return activation_shape, activation_size, number
FC3
nparameters_fully_connected(120 , 400)
Activation Shape, Activation Size, # Parameters
((120, 1), 120, 48120)
FC4
nparameters_fully_connected(84 , 120)
Activation Shape, Activation Size, # Parameters
((84, 1), 84, 10164)
Softmax
nparameters_fully_connected(10 , 84)
Activation Shape, Activation Size, # Parameters
((10, 1), 10, 850)
Up to now we have seen the dimensions of the activation shape, the activation size and the number of parameters. Let us put in practice this knowledge.
How to use AlexNet Network
For this project I will take two differnet models of AlexNet applied to an unknown dataset from the problem given at the MMORPG-AI
The models to analyze are:
- Non adapted model
- Adapted model
The non adapted model is just take the “raw” definition of the AlexNet Network from the standard python code here
The adapted model is the version where we modify the parameters of the non adapted model in according to the Analysis previous done in this blog.
Let us first load the libraries that we need to begin the discussion
#Importing Gamepad library
from mmorpg import *
The important part is this:
# We define the size of the pictures
WIDTH = 480
HEIGHT = 270
We load the data of the project
#We load the images of the gameplay
x_training_data=pd.read_pickle('data/dfx-0.pkl')
#We load the inputs of the of the gameplay
y_training_data=pd.read_pickle('data/dfy-0.pkl')
X_train, X_valid, y_train, y_valid = train_test_split(x_training_data, y_training_data, test_size=0.2, random_state=6)
# Train Image part ( 4 Dimensional)
X_image = np.array([df_to_numpy_image(X_train,i) for i in X_train.index])
X=X_image.reshape(-1,WIDTH,HEIGHT,3)
#Train Input part ( 1 Dimensional )
Y = [df_to_numpy_input(y_train,i) for i in y_train.index]
# Test Image part ( 4 Dimensional)
test_image = np.array([df_to_numpy_image(X_valid,i) for i in X_valid.index])
test_x=test_image.reshape(-1,WIDTH,HEIGHT,3)
## Test Input part( 1 Dimensional )
test_y = [df_to_numpy_input(y_valid,i) for i in y_valid.index]
Alexnet Model - Non adapted model
We define the standard AlexNet non adapted
LR = 1e-3
MODEL_NAME = 'mmorpg-{}-{}.model'.format(LR, 'alexnet-non-adapted')
def alexnet(width, height, lr, output=29):
# Building 'AlexNet' #line
network = input_data(shape=[None, width, height, 3]) #0
network = conv_2d(network, 96, 11, strides=4, activation='relu') #1
network = max_pool_2d(network, 3, strides=2) #2
network = local_response_normalization(network) #3
network = conv_2d(network, 256, 5, activation='relu') #4
network = max_pool_2d(network, 3, strides=2) #5
network = local_response_normalization(network) #6
network = conv_2d(network, 384, 3, activation='relu') #7
network = conv_2d(network, 384, 3, activation='relu') #8
network = conv_2d(network, 256, 3, activation='relu') #9
network = max_pool_2d(network, 3, strides=2) #10
network = local_response_normalization(network) #11
network = fully_connected(network, 4096, activation='tanh') #12
network = dropout(network, 0.5) #13
network = fully_connected(network, 4096, activation='tanh') #14
network = dropout(network, 0.5) #15
network = fully_connected(network, 29, activation='softmax') #16
network = regression(network, optimizer='momentum', #17
loss='categorical_crossentropy',
learning_rate=0.001)
# Training
model = tflearn.DNN(network, checkpoint_path='model_alexnet',
max_checkpoints=1, tensorboard_verbose=2, tensorboard_dir='log')
return model
model = alexnet(WIDTH, HEIGHT, LR, output=29)
We train the model
model.fit(X, Y, n_epoch=5, validation_set=0.1, shuffle=True,
show_metric=True, batch_size=64, snapshot_step=200,
snapshot_epoch=False, run_id=MODEL_NAME)
Training Step: 15 | total loss: [1m[32m1.97406[0m[0m | time: 21.022s
| Momentum | epoch: 005 | loss: 1.97406 - acc: 0.4897 -- iter: 180/180
We have seen that the accuracy is less than 0.5 and the loss near to 2.0 . With the knowledge of the dimensions studied before we will adapt the model in appropiate way to improve the AlexNet model.
Understanding the parameters of AlexNet
The standard AlexNet network may be depicted as the Coursera Deep Learning Course:
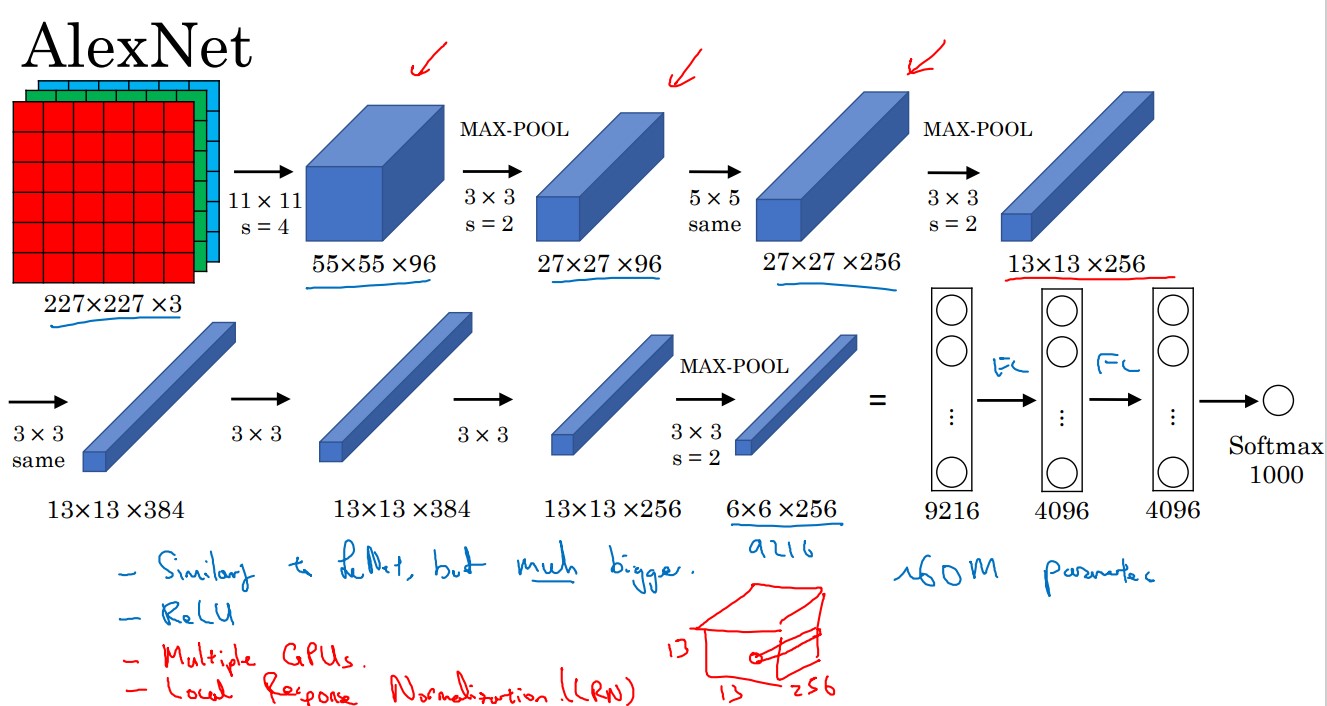
Where we obtain the essential parameters for each of the layers depicted in the previous picture
The inputs of the neural nework in tensorflow is given by
input_data(shape=[None, width, height, 3]) #0
#CONV 1
inputs =227,227,3 #nw x nh x nc image
kernel = 11,11 #fw x fw filter
stride = 4.0 #stride s
padding = 0.0 #padding p
filters = 96 #number of filters ncl
nparameters_convolution(inputs, kernel,stride,padding,filters)
Activation Shape, Activation Size, # Parameters
((55, 55, 96), 290400, 34944)
In TensorFlow this part corresponds to
conv_2d(network, 96, 11, strides=4, activation='relu') #1
#POOL1
inputs = 55, 55, 96 #nw x nh x nc
kernel = 3,3 #fw x fw filter
stride = 2.0 #stride s
padding = 0.0 #padding p
dim_pool(inputs, kernel,stride,padding)
Activation Shape, Activation Size, # Parameters
((27, 27, 96), 69984, 0)
In TensorFlow this part corresponds to
max_pool_2d(network, 3, strides=2) #2
After using a pool we can use a normalization
local_response_normalization(network) #3
#CONVOLUTION SAME 1
inputs =27, 27, 96 #nw x nh x nc image
kernel = 5,5 #fw x fw filter
stride = 1.0 #stride s
padding = 2.0 #padding p
filters = 256 #number of filters ncl
nparameters_convolution(inputs, kernel,stride,padding,filters)
Activation Shape, Activation Size, # Parameters
((27, 27, 256), 186624, 614656)
In TensorFlow this part corresponds to:
conv_2d(network, 256, 5, activation='relu') #4
#POOL2
inputs = 27, 27, 256 #nw x nh x nc
kernel = 3,3 #fw x fw filter
stride = 2.0 #stride s
padding = 0.0 #padding p
dim_pool(inputs, kernel,stride,padding)
Activation Shape, Activation Size, # Parameters
((13, 13, 256), 43264, 0)
In TensorFlow this part corresponds to:
max_pool_2d(network, 3, strides=2) #5
After a pool in we use:
local_response_normalization(network) #6
#CONVOLUTION SAME 2
inputs =13, 13, 256 #nw x nh x nc image
kernel = 3,3 #fw x fw filter
stride = 1.0 #stride s
padding = 1.0 #padding p
filters = 384 #number of filters ncl
nparameters_convolution(inputs, kernel,stride,padding,filters)
Activation Shape, Activation Size, # Parameters
((13, 13, 384), 64896, 885120)
In TensorFlow this part corresponds to:
conv_2d(network, 384, 3, activation='relu') #7
#CONVOLUTION SAME 3
inputs =13, 13, 384 #nw x nh x nc image
kernel = 3,3 #fw x fw filter
stride = 1.0 #stride s
padding = 1.0 #padding p
filters = 384 #number of filters ncl
nparameters_convolution(inputs, kernel,stride,padding,filters)
Activation Shape, Activation Size, # Parameters
((13, 13, 384), 64896, 1327488)
In TensorFlow this part corresponds to:
conv_2d(network, 384, 3, activation='relu') #8
#CONVOLUTION SAME 4
inputs =13, 13, 384 #nw x nh x nc image
kernel = 3,3 #fw x fw filter
stride = 1.0 #stride s
padding = 1.0 #padding p
filters = 256 #number of filters ncl
nparameters_convolution(inputs, kernel,stride,padding,filters)
Activation Shape, Activation Size, # Parameters
((13, 13, 256), 43264, 884992)
In TensorFlow this part corresponds to:
conv_2d(network, 256, 3, activation='relu') #9
#POOL3
inputs = 13, 13, 256 #nw x nh x nc
kernel = 3,3 #fw x fw filter
stride = 2.0 #stride s
padding = 0.0 #padding p
dim_pool(inputs, kernel,stride,padding)
Activation Shape, Activation Size, # Parameters
((6, 6, 256), 9216, 0)
In TensorFlow this part corresponds to:
max_pool_2d(network, 3, strides=2) #10
After pool we use a normalization
local_response_normalization(network) #11
#FC1
nparameters_fully_connected(4096 , 9216)
Activation Shape, Activation Size, # Parameters
((4096, 1), 4096, 37752832)
In TensorFlow this part corresponds to:
fully_connected(network, 4096, activation='tanh') #12
Dropout can be used after convolutional layers (e.g. Conv2D) and after pooling layers (e.g. MaxPooling2D). Often, dropout is only used after the pooling layers, but this is just a rough heuristic. After fully connected layer we use dropout to avoid overfitting
dropout(network, 0.5) #13
#FC2
nparameters_fully_connected(4096 , 4096)
Activation Shape, Activation Size, # Parameters
((4096, 1), 4096, 16781312)
In TensorFlow this part corresponds to:
fully_connected(network, 4096, activation='tanh') #14
After fully connected layer we use dropout
dropout(network, 0.5) #15
#Softmax
nparameters_fully_connected(1000 , 4096)
Activation Shape, Activation Size, # Parameters
((1000, 1), 1000, 4097000)
In TensorFlow this part corresponds to:
fully_connected(network, 29, activation='softmax') #16
Full code
Let us write the parameters Alexnet network in asimple code
parameters={}
#Input layer
parameters[0]=227,227,3
#CONV 1
inputs =parameters[0] #nw x nh x nc image
kernel = 11,11 #fw x fw filter
stride = 4.0 #stride s
padding = 0.0 #padding p
filters = 96 #number of filters ncl
parameters[1]=nparameters_convolution(inputs, kernel,stride,padding,filters)
#POOL1
inputs = parameters[1][0] #nw x nh x nc
kernel = 3,3 #fw x fw filter
stride = 2.0 #stride s
padding = 0.0 #padding p
parameters[2]=dim_pool(inputs, kernel,stride,padding)
#CONVOLUTION SAME 1
inputs =parameters[2][0] #nw x nh x nc image
kernel = 5,5 #fw x fw filter
stride = 1.0 #stride s
padding = 2.0 #padding p
filters = 256 #number of filters ncl
parameters[3]=nparameters_convolution(inputs, kernel,stride,padding,filters)
check_same(inputs,parameters[3]) # Checking parameters of same convolution
#POOL2
inputs = parameters[3][0] #nw x nh x nc
kernel = 3,3 #fw x fw filter
stride = 2.0 #stride s
padding = 0.0 #padding p
parameters[4]=dim_pool(inputs, kernel,stride,padding)
#CONVOLUTION SAME 2
inputs =parameters[4][0] #nw x nh x nc image
kernel = 3,3 #fw x fw filter
stride = 1.0 #stride s
padding = 1.0 #padding p
filters = 384 #number of filters ncl
parameters[5]=nparameters_convolution(inputs, kernel,stride,padding,filters)
check_same(inputs,parameters[5]) # Checking parameters of same convolution
#CONVOLUTION SAME 3
inputs =parameters[5][0] #nw x nh x nc image
kernel = 3,3 #fw x fw filter
stride = 1.0 #stride s
padding = 1.0 #padding p
filters = 384 #number of filters ncl
parameters[6]=nparameters_convolution(inputs, kernel,stride,padding,filters)
check_same(inputs,parameters[6]) # Checking parameters of same convolution
#CONVOLUTION SAME 4
inputs =parameters[6][0] #nw x nh x nc image
kernel = 3,3 #fw x fw filter
stride = 1.0 #stride s
padding = 1.0 #padding p
filters = 256 #number of filters ncl
parameters[7]=nparameters_convolution(inputs, kernel,stride,padding,filters)
check_same(inputs,parameters[7]) # Checking parameters of same convolution
#POOL3
inputs = parameters[7][0] #nw x nh x nc
kernel = 3,3 #fw x fw filter
stride = 2.0 #stride s
padding = 0.0 #padding p
parameters[8]=dim_pool(inputs, kernel,stride,padding)
#FC1
parameters[9]=nparameters_fully_connected(4096 , parameters[8][1])
#FC2
parameters[10]=nparameters_fully_connected(parameters[9][1] , parameters[9][1])
#Softmax
parameters[11]=nparameters_fully_connected(1000 , parameters[10][1])
From the previous analysis we can parametrize the model
def alexnet_parametrized(width, height, lr, output=29):
# Building 'AlexNet' #line
network = input_data(shape=[None, width, height, 3]) #0
network = conv_2d(network, filters1, kernel1, stride1, activation='relu') #1
network = max_pool_2d(network, kernel2, strides=stride2 ) #2
network = local_response_normalization(network) #3
network = conv_2d(network, filters3 , kernel3 , activation='relu') #4
network = max_pool_2d(network, kernel4, strides=stride4) #5
network = local_response_normalization(network) #6
network = conv_2d(network, filters5 , kernel5 , activation='relu') #7
network = conv_2d(network, filters6 , kernel6 , activation='relu') #8
network = conv_2d(network, filters7, kernel7 , activation='relu') #9
network = max_pool_2d(network, kernel8 , strides=stride8 ) #10
network = local_response_normalization(network) #11
network = fully_connected(network, activation9, activation='tanh') #12
network = dropout(network, dropout13) #13
network = fully_connected(network, activation10, activation='tanh') #14
network = dropout(network, dropout15) #15
network = fully_connected(network, outputs11, activation='softmax') #16
network = regression(network, optimizer='momentum', #17
loss='categorical_crossentropy',
learning_rate=learning_rate17)
# Training
model = tflearn.DNN(network, checkpoint_path='model_alexnet',
max_checkpoints=1, tensorboard_verbose=2, tensorboard_dir='log')
return model
#Paramters Operation
filters1 = 96 #1
kernel1 = 11
stride1 = 4
kernel2 = 3 #2
stride2 = 2
filters3 = 256 #3
kernel3 = 5
kernel4 = 3 #4
stride4 = 2
filters5 = 384 #5
kernel5 = 3
filters6 = 384 #6
kernel6 = 3
filters7 = 256 #7
kernel7 = 3
kernel8 = 3 #8
stride8 = 2
activation9 = 4096 #9
activation10 = 4096 #10
outputs11 = 29 #11
dropout13=0.5
dropout15=0.5
learning_rate17=0.001
That follows the following set of parameters:
print("Operation,","Activation Shape,", "Activation Size,","#Parameters")
for i in range(12):
step=i
layer=parameters[step]
print(step, layer)
Operation, Activation Shape, Activation Size, #Parameters
0 (227, 227, 3)
1 ((55, 55, 96), 290400, 34944)
2 ((27, 27, 96), 69984, 0)
3 ((27, 27, 256), 186624, 614656)
4 ((13, 13, 256), 43264, 0)
5 ((13, 13, 384), 64896, 885120)
6 ((13, 13, 384), 64896, 1327488)
7 ((13, 13, 256), 43264, 884992)
8 ((6, 6, 256), 9216, 0)
9 ((4096, 1), 4096, 37752832)
10 ((4096, 1), 4096, 16781312)
11 ((1000, 1), 1000, 4097000)
From the standard framework of the AlexNet we see that:
The original input pictures have the dimensions of
227x227x3
and our pictutes in the MMORPG-AI project are:
270x 480x3
That means that we have to adapt the template AlexNet model
showarray(X_image[0])
X_image[0].shape
(270, 480, 3)
We should modify al the whole neural network!
Modified version of AlexNet - Adapted version
Let us write the parameters Alexnet network in simple code
parameters={}
#Input layer
parameters[0]=270,480,3
#CONV 1
inputs =parameters[0] #nw x nh x nc image
kernel = 11,11 #fw x fw filter
stride = 4.0 #stride s
padding = 0.0 #padding p
filters = 96 #number of filters ncl
parameters[1]=nparameters_convolution(inputs, kernel,stride,padding,filters)
#POOL1
inputs = parameters[1][0] #nw x nh x nc
kernel = 3,3 #fw x fw filter
stride = 2.0 #stride s
padding = 0.0 #padding p
parameters[2]=dim_pool(inputs, kernel,stride,padding)
#CONVOLUTION SAME 1
inputs =parameters[2][0] #nw x nh x nc image
kernel = 5,5 #fw x fw filter
stride = 1.0 #stride s
padding = 2.0 #padding p
filters = 256 #number of filters ncl
parameters[3]=nparameters_convolution(inputs, kernel,stride,padding,filters)
check_same(inputs,parameters[3]) # Checking parameters of same convolution
#POOL2
inputs = parameters[3][0] #nw x nh x nc
kernel = 3,3 #fw x fw filter
stride = 2.0 #stride s
padding = 0.0 #padding p
parameters[4]=dim_pool(inputs, kernel,stride,padding)
#CONVOLUTION SAME 2
inputs =parameters[4][0] #nw x nh x nc image
kernel = 3,3 #fw x fw filter
stride = 1.0 #stride s
padding = 1.0 #padding p
filters = 384 #number of filters ncl
parameters[5]=nparameters_convolution(inputs, kernel,stride,padding,filters)
check_same(inputs,parameters[5]) # Checking parameters of same convolution
#CONVOLUTION SAME 3
inputs =parameters[5][0] #nw x nh x nc image
kernel = 3,3 #fw x fw filter
stride = 1.0 #stride s
padding = 1.0 #padding p
filters = 384 #number of filters ncl
parameters[6]=nparameters_convolution(inputs, kernel,stride,padding,filters)
check_same(inputs,parameters[6]) # Checking parameters of same convolution
#CONVOLUTION SAME 4
inputs =parameters[6][0] #nw x nh x nc image
kernel = 3,3 #fw x fw filter
stride = 1.0 #stride s
padding = 1.0 #padding p
filters = 256 #number of filters ncl
parameters[7]=nparameters_convolution(inputs, kernel,stride,padding,filters)
check_same(inputs,parameters[7]) # Checking parameters of same convolution
#POOL3
inputs = parameters[7][0] #nw x nh x nc
kernel = 3,3 #fw x fw filter
stride = 2.0 #stride s
padding = 0.0 #padding p
parameters[8]=dim_pool(inputs, kernel,stride,padding)
#FC1
parameters[9]=nparameters_fully_connected(4096 , parameters[8][1])
#FC2
parameters[10]=nparameters_fully_connected(parameters[9][1] , parameters[9][1])
#Softmax
parameters[11]=nparameters_fully_connected(29 , parameters[10][1])
print("Operation,","Activation Shape,", "Activation Size,","#Parameters")
for i in range(12):
step=i
layer=parameters[step]
print(step, layer)
Operation, Activation Shape, Activation Size, #Parameters
0 (270, 480, 3)
1 ((65, 118, 96), 736320, 34944)
2 ((32, 58, 96), 178176, 0)
3 ((32, 58, 256), 475136, 614656)
4 ((15, 28, 256), 107520, 0)
5 ((15, 28, 384), 161280, 885120)
6 ((15, 28, 384), 161280, 1327488)
7 ((15, 28, 256), 107520, 884992)
8 ((7, 13, 256), 23296, 0)
9 ((4096, 1), 4096, 95424512)
10 ((4096, 1), 4096, 16781312)
11 ((29, 1), 29, 118813)
Meanwhile the orginal AlexNet calculation contains
Operation, Activation Shape, Activation Size, #Parameters
0 (227, 227, 3)
1 ((55, 55, 96), 290400, 34944)
2 ((27, 27, 96), 69984, 0)
3 ((27, 27, 256), 186624, 614656)
4 ((13, 13, 256), 43264, 0)
5 ((13, 13, 384), 64896, 885120)
6 ((13, 13, 384), 64896, 1327488)
7 ((13, 13, 256), 43264, 884992)
8 ((6, 6, 256), 9216, 0)
9 ((4096, 1), 4096, 37752832)
10 ((4096, 1), 4096, 16781312)
11 ((1000, 1), 1000, 4097000)
The previous results shows how we should modify all the layers in an appropiate way if we want to follow the same structure of the AlexNet
In ordering to improve the Neural Network we can take into account the following best practices:
- Is the network size is too small / large?
- Check overfitting or underfitting by train history, then chose the best epoch size.
- Try initialise weights with different initialization scheme.
- Try different activation functions, loss function, optimizer.
- Change layers number and units number.
- Change batch size.
- Add dropout layer.
Among the best practices mentioned before , we will take into account “Change layers number and units number.” Because the original AlexNet were developed taking into account 1000 classes insted we have only 29 classes and then does not makes any sense keep the same number of units.
#Normalization Parameter
Norma = 29/1000
#round a float up to next even number
import math
def roundeven(f):
return math.ceil(f / 2.) * 2
parameters={}
#Input layer
parameters[0]=270,480,3
#CONV 1
inputs =parameters[0] #nw x nh x nc image
kernel = 11,11 #fw x fw filter
stride = 4.0 #stride s
padding = 0.0 #padding p
filters = roundeven(96*Norma) #number of filters ncl
parameters[1]=nparameters_convolution(inputs, kernel,stride,padding,filters)
#POOL1
inputs = parameters[1][0] #nw x nh x nc
kernel = 3,3 #fw x fw filter
stride = 2.0 #stride s
padding = 0.0 #padding p
parameters[2]=dim_pool(inputs, kernel,stride,padding)
#CONVOLUTION SAME 1
inputs =parameters[2][0] #nw x nh x nc image
kernel = 5,5 #fw x fw filter
stride = 1.0 #stride s
padding = 2.0 #padding p
filters = roundeven(256*Norma) #number of filters ncl
parameters[3]=nparameters_convolution(inputs, kernel,stride,padding,filters)
check_same(inputs,parameters[3]) # Checking parameters of same convolution
#POOL2
inputs = parameters[3][0] #nw x nh x nc
kernel = 3,3 #fw x fw filter
stride = 2.0 #stride s
padding = 0.0 #padding p
parameters[4]=dim_pool(inputs, kernel,stride,padding)
#CONVOLUTION SAME 2
inputs =parameters[4][0] #nw x nh x nc image
kernel = 3,3 #fw x fw filter
stride = 1.0 #stride s
padding = 1.0 #padding p
filters = roundeven(384*Norma) #number of filters ncl
parameters[5]=nparameters_convolution(inputs, kernel,stride,padding,filters)
check_same(inputs,parameters[5]) # Checking parameters of same convolution
#CONVOLUTION SAME 3
inputs =parameters[5][0] #nw x nh x nc image
kernel = 3,3 #fw x fw filter
stride = 1.0 #stride s
padding = 1.0 #padding p
filters = roundeven(384*Norma) #number of filters ncl
parameters[6]=nparameters_convolution(inputs, kernel,stride,padding,filters)
check_same(inputs,parameters[6]) # Checking parameters of same convolution
#CONVOLUTION SAME 4
inputs =parameters[6][0] #nw x nh x nc image
kernel = 3,3 #fw x fw filter
stride = 1.0 #stride s
padding = 1.0 #padding p
filters = roundeven(256*Norma) #number of filters ncl
parameters[7]=nparameters_convolution(inputs, kernel,stride,padding,filters)
check_same(inputs,parameters[7]) # Checking parameters of same convolution
#POOL3
inputs = parameters[7][0] #nw x nh x nc
kernel = 3,3 #fw x fw filter
stride = 2.0 #stride s
padding = 0.0 #padding p
parameters[8]=dim_pool(inputs, kernel,stride,padding)
#FC1
parameters[9]=nparameters_fully_connected(roundeven(4096*Norma) , parameters[8][1])
#FC2
parameters[10]=nparameters_fully_connected(parameters[9][1] , parameters[9][1])
#Softmax
parameters[11]=nparameters_fully_connected(int(1000*Norma) , parameters[10][1])
print("Operation,","Activation Shape,", "Activation Size,","#Parameters")
for i in range(12):
step=i
layer=parameters[step]
print(step, layer)
Operation, Activation Shape, Activation Size, #Parameters
0 (270, 480, 3)
1 ((65, 118, 4), 30680, 1456)
2 ((32, 58, 4), 7424, 0)
3 ((32, 58, 8), 14848, 808)
4 ((15, 28, 8), 3360, 0)
5 ((15, 28, 12), 5040, 876)
6 ((15, 28, 12), 5040, 1308)
7 ((15, 28, 8), 3360, 872)
8 ((7, 13, 8), 728, 0)
9 ((120, 1), 120, 87480)
10 ((120, 1), 120, 14520)
11 ((29, 1), 29, 3509)
#Importing Gamepad library
from mmorpg import *
The important part is this:
# We define the size of the pictures
WIDTH = 480
HEIGHT = 270
We load the data of the project
#We load the images of the gameplay
x_training_data=pd.read_pickle('data/dfx-0.pkl')
#We load the inputs of the of the gameplay
y_training_data=pd.read_pickle('data/dfy-0.pkl')
X_train, X_valid, y_train, y_valid = train_test_split(x_training_data, y_training_data, test_size=0.2, random_state=6)
# Train Image part ( 4 Dimensional)
X_image = np.array([df_to_numpy_image(X_train,i) for i in X_train.index])
X=X_image.reshape(-1,WIDTH,HEIGHT,3)
#Train Input part ( 1 Dimensional )
Y = [df_to_numpy_input(y_train,i) for i in y_train.index]
# Test Image part ( 4 Dimensional)
test_image = np.array([df_to_numpy_image(X_valid,i) for i in X_valid.index])
test_x=test_image.reshape(-1,WIDTH,HEIGHT,3)
## Test Input part( 1 Dimensional )
test_y = [df_to_numpy_input(y_valid,i) for i in y_valid.index]
First let us define all the parameters of AlexNet adapted
#Paramters Operation
filters1 = roundeven(96*Norma) #1
kernel1 = 11
stride1 = 4
kernel2 = 3 #2
stride2 = 2
filters3 = roundeven(256*Norma) #3
kernel3 = 5
kernel4 = 3 #4
stride4 = 2
filters5 = roundeven(384*Norma) #5
kernel5 = 3
filters6 = roundeven(384*Norma) #6
kernel6 = 3
filters7 = roundeven(256*Norma) #7
kernel7 = 3
kernel8 = 3 #8
stride8 = 2
activation9 = roundeven(4096*Norma) #9
activation10 = roundeven(4096*Norma) #10
outputs11 = int(1000*Norma) #11
dropout13=0.5
dropout15=0.5
learning_rate17=0.001
def alexnet_adapted(width, height, lr, output=29):
# Building 'AlexNet' #line
network = input_data(shape=[None, width, height, 3]) #0
network = conv_2d(network, filters1, kernel1, stride1, activation='relu') #1
network = max_pool_2d(network, kernel2, strides=stride2 ) #2
network = local_response_normalization(network) #3
network = conv_2d(network, filters3 , kernel3 , activation='relu') #4
network = max_pool_2d(network, kernel4, strides=stride4) #5
network = local_response_normalization(network) #6
network = conv_2d(network, filters5 , kernel5 , activation='relu') #7
network = conv_2d(network, filters6 , kernel6 , activation='relu') #8
network = conv_2d(network, filters7, kernel7 , activation='relu') #9
network = max_pool_2d(network, kernel8 , strides=stride8 ) #10
network = local_response_normalization(network) #11
network = fully_connected(network, activation9, activation='tanh') #12
network = dropout(network, dropout13) #13
network = fully_connected(network, activation10, activation='tanh') #14
network = dropout(network, dropout15) #15
network = fully_connected(network, outputs11, activation='softmax') #16
network = regression(network, optimizer='momentum', #17
loss='categorical_crossentropy',
learning_rate=learning_rate17)
# Training
model = tflearn.DNN(network, checkpoint_path='model_alexnet',
max_checkpoints=1, tensorboard_verbose=2, tensorboard_dir='log')
return model
Up to now, we have seen how to use the activation shape, size and number of parameters.
However there are further hyperparameters that we should know. Let us summarize some of them.
Learning rate
The learning rate defines how quickly a network updates its parameters.
Low learning rate slows down the learning process but converges smoothly. Larger learning rate speeds up the learning but may not converge.
Usually a decaying Learning rate is preferred.
Momentum
Momentum helps to know the direction of the next step with the knowledge of the previous steps. It helps to prevent oscillations. A typical choice of momentum is between 0.5 to 0.9.
Number of epochs
Number of epochs is the number of times the whole training data is shown to the network while training.
Increase the number of epochs until the validation accuracy starts decreasing even when training accuracy is increasing(overfitting).
Batch size
Mini batch size is the number of sub samples given to the network after which parameter update happens.
The activation function is a node that is put at the end of or in between Neural Networks. The activation function is the non linear transformation that we do over the input signal. This transformed output is then sent to the next layer of neurons as input.
A good default for batch size might be 32. Also try 32, 64, 128, 256, and so o
The adapted version of the AlexNet model does not modify the latest size of the neural net.
LR = 1e-3
MODEL_NAME = 'mmorpg-{}-{}.model'.format(LR, 'alex-adaptedd')
MODEL_NAME
'mmorpg-0.001-alex-adaptedd.model'
model = alexnet_adapted(WIDTH, HEIGHT, LR, output=29)
We train the modifed model
model.fit(X, Y, n_epoch=5, validation_set=0.1, shuffle=True,
show_metric=True, batch_size=64, snapshot_step=200,
snapshot_epoch=True, run_id=MODEL_NAME)
Training Step: 14 | total loss: [1m[32m5.99706[0m[0m | time: 0.222s
| Momentum | epoch: 005 | loss: 5.99706 - acc: 0.4878 -- iter: 128/180
Training Step: 15 | total loss: [1m[32m5.92157[0m[0m | time: 1.347s
| Momentum | epoch: 005 | loss: 5.92157 - acc: 0.4498 | val_loss: 5.46878 - val_acc: 0.0000 -- iter: 180/180
--
# Set paramaters
params_grid ={
'batch_size':(32, 64,256,512,1024,2*1024,3*1024),
'epochs':(5, 10,20,30,40,50)
}
for bsize in params_grid['batch_size']:
for epochs in params_grid['epochs']:
MODEL_NAME = 'mmorpg-{}-{}-{}.model'.format('alex-adapted',bsize,epochs)
model = alexnet_adapted(WIDTH, HEIGHT, LR, output=29)
print(MODEL_NAME)
model.fit(X, Y, n_epoch=epochs, validation_set=0.1, shuffle=True,
show_metric=True, batch_size=bsize, snapshot_step=200,
snapshot_epoch=False, run_id=MODEL_NAME)
We can try different combinations of hyperparameters. We should perform hyperparameter tuning but due to we are working with tflearn, we can skip this part. To more information visit this reference.
FULL CODE 1 Adapted
import pandas as pd
from sklearn.model_selection import train_test_split
import numpy as np
import io
from IPython.display import clear_output, Image, display
import PIL.Image
from matplotlib import pyplot as plt
import logging, sys
logging.disable(sys.maxsize)
import tflearn
from tflearn.layers.core import input_data, dropout, fully_connected
from tflearn.layers.conv import conv_2d, max_pool_2d
from tflearn.layers.normalization import local_response_normalization
from tflearn.layers.estimator import regression
# We define the size of the pictures
WIDTH = 480
HEIGHT = 270
LR = 1e-4
MODEL_NAME = 'mmorpg-{}-{}.model'.format(LR, 'alex-adapted')
PREV_MODEL = ''
LOAD_MODEL = False
FILE_I_END=1
EPOCHS=1
#We load the images of the gameplay
x_training_data=pd.read_pickle('data/dfx-0.pkl')
#We load the inputs of the of the gameplay
y_training_data=pd.read_pickle('data/dfy-0.pkl')
def df_to_numpy_image(df_image_clean,index):
#select the row with index label 'index'
image_clean=df_image_clean.loc[[index]].T.to_numpy()
lists =image_clean.tolist()
# Nested List Comprehension to flatten a given 2-D matrix
# 2-D List
matrix = lists
flatten_matrix = [val.tolist() for sublist in matrix for val in sublist]
# converting list to array
arr = np.array(flatten_matrix)
return arr
def df_to_numpy_input(df_input,index):
# flattening a 2d numpy array
# into 1d array
# and remove dtype at the end of numpy array
lista=df_input.loc[[index]].values.tolist()
arr=np.array(lista).ravel()
return arr
#Normalization Parameter
Norma = 29/1000
#round a float up to next even number
import math
def roundeven(f):
return math.ceil(f / 2.) * 2
#Paramters Operation
filters1 = roundeven(96*Norma) #1
kernel1 = 11
stride1 = 4
kernel2 = 3 #2
stride2 = 2
filters3 = roundeven(256*Norma) #3
kernel3 = 5
kernel4 = 3 #4
stride4 = 2
filters5 = roundeven(384*Norma) #5
kernel5 = 3
filters6 = roundeven(384*Norma) #6
kernel6 = 3
filters7 = roundeven(256*Norma) #7
kernel7 = 3
kernel8 = 3 #8
stride8 = 2
activation9 = roundeven(4096*Norma) #9
activation10 = roundeven(4096*Norma) #10
outputs11 = int(1000*Norma) #11
dropout13=0.5
dropout15=0.5
learning_rate17=0.001
def alexnet_adapted(width, height, lr, output=29):
# Building 'AlexNet' #line
network = input_data(shape=[None, width, height, 3]) #0
network = conv_2d(network, filters1, kernel1, stride1, activation='relu') #1
network = max_pool_2d(network, kernel2, strides=stride2 ) #2
network = local_response_normalization(network) #3
network = conv_2d(network, filters3 , kernel3 , activation='relu') #4
network = max_pool_2d(network, kernel4, strides=stride4) #5
network = local_response_normalization(network) #6
network = conv_2d(network, filters5 , kernel5 , activation='relu') #7
network = conv_2d(network, filters6 , kernel6 , activation='relu') #8
network = conv_2d(network, filters7, kernel7 , activation='relu') #9
network = max_pool_2d(network, kernel8 , strides=stride8 ) #10
network = local_response_normalization(network) #11
network = fully_connected(network, activation9, activation='tanh') #12
network = dropout(network, dropout13) #13
network = fully_connected(network, activation10, activation='tanh') #14
network = dropout(network, dropout15) #15
network = fully_connected(network, outputs11, activation='softmax') #16
network = regression(network, optimizer='momentum', #17
loss='categorical_crossentropy',
learning_rate=learning_rate17)
# Training
model = tflearn.DNN(network, checkpoint_path='alexnet',
max_checkpoints=1, tensorboard_verbose=2, tensorboard_dir='log')
return model
model = alexnet_adapted(WIDTH, HEIGHT, LR, output=29)
if LOAD_MODEL:
model.load(PREV_MODEL)
print('We have loaded a previous model!!!!')
# iterates through the training files
for e in range(EPOCHS):
data_order = [i for i in range(0,FILE_I_END)]
#shuffle(data_order)
for count,i in enumerate(data_order):
try:
#processed image rgb color - no image filters
file_name_x = 'data/dfx-{}.pkl'.format(i)
file_name_y = 'data/dfy-{}.pkl'.format(i)
print(file_name_x)
#We load the images of the gameplay
x_training_data=pd.read_pickle(file_name_x)
#We load the inputs of the of the gameplay
y_training_data=pd.read_pickle(file_name_y)
X_train, X_valid, y_train, y_valid = train_test_split(x_training_data, y_training_data, test_size=0.2, random_state=6)
# Train Image part ( 4 Dimensional)
X_image = np.array([df_to_numpy_image(X_train,i) for i in X_train.index])
X=X_image.reshape(-1,WIDTH,HEIGHT,3)
#Train Input part ( 1 Dimensional )
Y = [df_to_numpy_input(y_train,i) for i in y_train.index]
# Test Image part ( 4 Dimensional)
test_image = np.array([df_to_numpy_image(X_valid,i) for i in X_valid.index])
test_x=test_image.reshape(-1,WIDTH,HEIGHT,3)
## Test Input part( 1 Dimensional )
test_y = [df_to_numpy_input(y_valid,i) for i in y_valid.index]
model.fit(X, Y, n_epoch=300,
validation_set=(test_x,test_y),
shuffle=True,
show_metric=True,
batch_size=256,
snapshot_step=50,
snapshot_epoch=False,
run_id=MODEL_NAME)
if count%4 == 0:
print('SAVING MODEL!')
model.save(MODEL_NAME)
except Exception as e:
print(str(e))
Training Step: 299 | total loss: [1m[32m1.38905[0m[0m | time: 0.327s
| Momentum | epoch: 299 | loss: 1.38905 - acc: 0.5756 -- iter: 200/200
Training Step: 300 | total loss: [1m[32m1.38892[0m[0m | time: 1.373s
| Momentum | epoch: 300 | loss: 1.38892 - acc: 0.5730 | val_loss: 1.39102 - val_acc: 1.0000 -- iter: 200/200
--
SAVING MODEL!
We have got acc: 0.5730 and loss: 1.38892, we could decrease the loss and training time.

The results can be improved by changing the hyperparameters , like stop early, with 100 epochs for example, and have a better dataset with more data.
You can download this notebook here.
Congratulations! You have learned about activations activation shape, activation size, and the number of parameters of the neural networks
Leave a comment